
Optyczne rozpoznawanie znaków (OCR) dla Windows 10
Streszczenie
W dzisiejszym cyfrowym świecie optyczne rozpoznawanie znaków (OCR) stało się niezbędnym narzędziem dla użytkowników systemu Windows 10. Oprogramowanie OCR umożliwia konwersję zeskanowanych obrazów i plików PDF na tekst edytowalny i możliwy do wyszukiwania. Jedną z wiodących bibliotek OCR dla Windows 10 jest biblioteka C# OCR, która zapewnia szeroki zakres funkcji i obsługuje wiele języków programowania.
Kluczowe punkty
- OCR dla C# do skanowania i czytania zdjęć i pdfs: Biblioteka C# OCR pozwala programistom zintegrować możliwości OCR z ich aplikacjami C#. Obsługuje skanowanie i czytanie różnych formatów obrazów, w tym PDF.
- .Biblioteka netto OCR z 127+ globalnymi pakietami językowymi: Dzięki bibliotece C# OCR możesz wyodrębnić tekst z obrazów i plików PDF w ponad 127 językach, co czyni go odpowiednim dla użytkowników międzynarodowych.
- Wyjście jako tekst, dane ustrukturyzowane lub przeglądane pliki PDF: Biblioteka zawiera opcje wyświetlania wyników OCR jako zwykły tekst, dane ustrukturyzowane lub przeglądane pliki PDF, w zależności od wymagań aplikacji.
- Wsparcie .Netto 7, 6, 5, rdzeń, standard, ramy: Biblioteka C# OCR jest kompatybilna z różnymi wersjami .Net, dzięki czemu jest dostępny dla programistów pracujących na różnych platformach.
pytania
- Jak mogę wykonać OCR w C# z biblioteką C# OCR?
Wykonanie OCR w C# za pomocą biblioteki C# OCR jest proste. Oto przykład:// Nuget PM> instaluj package Ironocr przy użyciu Ironocr; String ImageText = new irontesseract ().Odczyt (@„obrazy \ obraz.png ").Tekst;Ten fragment kodu odczytuje tekst z obrazu „obraz.PNG „Korzystanie z biblioteki C# OCR i przechowuje ją w zmiennej„ ImageText ”.
- Czy biblioteka C# OCR może wyodrębnić tekst z PDFS?
Tak, biblioteka C# OCR ma wbudowaną obsługę wyodrębnienia tekstu z dokumentów PDF. Oto przykład:używając Ironocr; za pomocą systemu; var octesseract = new irontesseract (); używając (var ocrinput = new ocrinput ()) < // OCR entire document ocrInput.AddPdf("example.pdf", "password"); // Alternatively OCR selected page numbers ocrInput.AddPdfPages("example.pdf", new[] < 1, 2, 3 >, "hasło"); var ocrresult = octesseract.Czytaj (ocrinput); Konsola.Writeline (Ocrresult.Tekst); >Ten fragment kodu pokazuje, jak wykonać OCR w dokumencie PDF o nazwie „Przykład.PDF „Korzystanie z biblioteki C# OCR.
- Czy odczyt kodu kodów kreskowych i QR obsługiwany przez bibliotekę C# OCR?
Tak, biblioteka C# OCR zapewnia obsługę czytania kodów kreskowych i kodów QR. Może wyodrębniać informacje z obrazów zawierających tego rodzaju kody. Oto przykład:używając Ironocr; za pomocą systemu; var octesseract = new irontesseract (); Octesseract.Konfiguracja.Readbarcodes = true; używając (var ocrinput = new ocrinput (@"images \ imageWithbarCode.png ")) < var ocrResult = ocrTesseract.Read(ocrInput); foreach (var barcode in ocrResult.Barcodes) < Console.WriteLine(barcode.Value); >>Ten fragment kodu odczytuje kod kreskowy lub kod QR z obrazu „ImageWithbarCode.png „Korzystanie z biblioteki C# OCR.
- Ile języków obsługuje biblioteka C# OCR?
Biblioteka C# OCR obsługuje ponad 125 języków na całym świecie, co czyni ją wszechstronną dla użytkowników na całym świecie. Oto przykład używania arabskiego jako języka:// PM> instalowanie ironoct.Języki.Arabski za pomocą żelaza; za pomocą systemu; var octesseract = new irontesseract (); Octesseract.Język = Ocrlanguage.Arabski; używając (var ocrinput = new ocrinput (@"obrazy \ arabski.gif ")) < var ocrResult = ocrTesseract.Read(ocrInput); Console.WriteLine(ocrResult.Text); >Ten fragment kodu pokazuje tekst czytania z obrazu arabskiego za pomocą biblioteki C# OCR.
- Czy biblioteka C# OCR może obsługiwać niską jakość skanowania i obrazy?
Tak, biblioteka C# OCR może obsłużyć skany i obrazy niskiej jakości. Obejmuje funkcjonalność w celu poprawy jakości obrazów przed wykonaniem OCR. Deweloperzy mogą zastosować różne filtry, aby zwiększyć jakość obrazu. Oto przykład:używając Ironocr; za pomocą systemu; var octesseract = new irontesseract (); używając (var ocrinput = new Ocrinput (@"images \ image.png "))Ten fragment kodu pokazuje, jak korzystać z biblioteki C# OCR z obrazem niskiej jakości o nazwie „obraz.PNG “.
Uwaga: pozostałe 10 pytań i ich szczegółowe odpowiedzi są dostępne w oryginalnym artykule.
Optyczne rozpoznawanie znaków (OCR) dla Windows 10
Jeśli nie masz pewności, czy SODA PDF jest dla Ciebie odpowiednia, dostępna jest bezpłatna próba, która pozwala odkrywać wszystkie jego funkcje. Elastyczny system cen umożliwia wybór planu, który najlepiej Ci odpowiada.
Czy Windows 10 ma wbudowane w OCR?
Biblioteka C# OCR
- OCR dla C# do skanowania i czytania zdjęć i pdfs
- .Biblioteka netto OCR z 127+ globalnymi pakietami językowymi
- Wyjście jako tekst, dane ustrukturyzowane lub przeglądane pliki PDF
- Wsparcie .Netto 7, 6, 5, rdzeń, standard, ramy
Przykłady
- OCR w 1 wierszu kodu
- Ekstrakcja tekstu PDF OCR
- OCR z odczytem kodu barkodowego i QR
- 125 Międzynarodowe języki OCR
- Naprawienie skanów i obrazów niskiej jakości
- Szybka konfiguracja OCR
- Filtry optymalizacji obrazu OCR
- Edycja kolorów obrazu OCR
- Klasa ocrresult
- Utwórz wyszukiwalne pliki PDF przez OCR
- Tesseract 5 dla .INTERNET
- Tesseract Szczegółowa konfiguracja
- Klasa ocrinput
- Ocr region obrazu
- TIFF do przeglądania konwertera pdf
- Optymalizacja rozdzielczości obrazu (DPI)
- Multitreadtesseract OCR
- Postęp OCR i śledzenie wydajności
- OCR dla wielopasmowych plików TIFF
- Zrób dowolny plik PDF, który można wyszukiwać, możliwy do kopiowania tekst
- Korzystanie z niestandardowych plików językowych Tesseract
- Wiele języków dla 1 dokumentu
- Eksportowanie obrazów elementów OCR
OCR w 1 wierszu kodu
// Nuget PM> instaluj package Ironocr przy użyciu Ironocr; String ImageText = new irontesseract ().Odczyt (@„obrazy \ obraz.png ").Tekst;Ekstrakcja tekstu PDF OCR
używając Ironocr; za pomocą systemu; var octesseract = new irontesseract (); używając (var ocrinput = new ocrinput ()) < // OCR entire document ocrInput.AddPdf("example.pdf", "password"); // Alternatively OCR selected page numbers ocrInput.AddPdfPages("example.pdf", new[] < 1, 2, 3 >, "hasło"); var ocrresult = octesseract.Czytaj (ocrinput); Konsola.Writeline (Ocrresult.Tekst); >OCR z odczytem kodu barkodowego i QR
używając Ironocr; za pomocą systemu; var octesseract = new irontesseract (); Octesseract.Konfiguracja.Readbarcodes = true; używając (var ocrinput = new ocrinput (@"images \ imageWithbarCode.png ")) < var ocrResult = ocrTesseract.Read(ocrInput); foreach (var barcode in ocrResult.Barcodes) < Console.WriteLine(barcode.Value); >>125 Międzynarodowe języki OCR
// PM> instalowanie ironoct.Języki.Arabski za pomocą żelaza; za pomocą systemu; var octesseract = new irontesseract (); Octesseract.Język = Ocrlanguage.Arabski; używając (var ocrinput = new ocrinput (@"obrazy \ arabski.gif ")) < var ocrResult = ocrTesseract.Read(ocrInput); Console.WriteLine(ocrResult.Text); >// Przykład z używaną niestandardową szkoloną czcionką: var ocTesserActCustomerlang = new iRontesSeract (); OcTesserActCustomerlang.UsEcustomTesseractLanguageFile („Custom_Tesseract_files/Custom.trainedData ”); octesseractcustomerlang.Dodatek.Englishbest); używając (var ocrinput = new ocrinput (@"obrazy \ mixed-lang.pdf "))
Naprawienie skanów i obrazów niskiej jakości
używając Ironocr; za pomocą systemu; var octesseract = new irontesseract (); używając (var ocrinput = new Ocrinput (@"images \ image.png "))
Szybka konfiguracja OCR
używając Ironocr; za pomocą systemu; var octesseract = new irontesseract (); // szybki słownik Ocrtesseract.Język = Ocrlanguage.Englishfast; // wyłącz niepotrzebne opcje Ocrtesseract.Konfiguracja.Readbarcodes = false; Octesseract.Konfiguracja.Renderearchablepdfsandhocr = false; // Załóżmy, że tekst jest starannie ułożony w dokumencie ortogonalnym Ocrtesseract.Konfiguracja.PageSegmerationMode = TesseractPagesegmentationMode.Automatyczny; używając (var ocrinput = new Ocrinput (@"images \ image.png "))
Filtry optymalizacji obrazu OCR
używając Ironocr; za pomocą systemu; var octesseract = new irontesseract (); używając (var ocrinput = new Ocrinput (@"images \ image.png ")) < // Note: You don't need all of them; most users only need Deskew() and occasionally DeNoise() ocrInput.WithTitle("My Document"); ocrInput.Binarize(); ocrInput.Contrast(); ocrInput.Deskew(); ocrInput.DeNoise(); ocrInput.Despeckle(); ocrInput.Dilate(); ocrInput.EnhanceResolution(300); ocrInput.Invert(); ocrInput.Rotate(90); ocrInput.Scale(150); ocrInput.Sharpen(); ocrInput.ToGrayScale(); ocrInput.Erode(); // WIZARD - If you are unsure use the debug-wizard to test all combinations: string codeToRun = OcrInputFilterWizard.Run(@"images\image.png", out double confidence, ocrTesseract); Console.WriteLine(codeToRun); // Optional: Export modified images so you can view them. foreach (var page in ocrInput.Pages) < page.SaveAsImage($"filtered_.bmp"); > var ocrresult = octesseract.Czytaj (ocrinput); Konsola.Writeline (Ocrresult.Tekst); >Edycja kolorów obrazu OCR
używając Ironocr; Korzystanie z Ironsoftware.Rysunek; za pomocą systemu; var octesseract = new irontesseract (); używając (var ocrinput = new ocrinput ("blue_and_pink.png ")) < ocrInput.WithTitle("Recolored"); ocrInput.ReplaceColor(Color.Pink, Color.White, 10); // Pink detection has 10% tolerance ocrInput.ReplaceColor(Color.Blue, Color.Black, 5); // Blue detection has 5% tolerance // Export the modified image so you can manually inspect it. foreach (var page in ocrInput.Pages) < page.SaveAsImage($"black_and_white_page_.bmp"); > var ocrresult = octesseract.Czytaj (ocrinput); Konsola.Writeline (Ocrresult.Tekst); >Klasa ocrresult
używając Ironocr; Korzystanie z Ironsoftware.Rysunek; // Możemy zagłębić się w wyniki OCR jako model obiektowy // stron, kody kreskowe, akapity, linie, słowa i znaki // To pozwala nam eksplorować, eksportować i rysować zawartość OCR przy użyciu innych interfejsów API/ var ocTesseract = new IrrontesSeract (); Octesseract.Konfiguracja.Readbarcodes = true; używając (var ocrinput = new Ocrinput (@"przykład.sprzeczka")) < OcrResult ocrResult = ocrTesseract.Read(ocrInput); foreach (var page in ocrResult.Pages) < // Page object int PageNumber = page.PageNumber; string PageText = page.Text; int PageWordCount = page.WordCount; // null if we dont set Ocr.Configuration.ReadBarCodes = true; OcrResult.Barcode[] Barcodes = page.Barcodes; AnyBitmap PageImage = page.ToBitmap(ocrInput); int PageWidth = page.Width; int PageHeight = page.Height; double PageRotation = page.Rotation; // angular correction in degrees from OcrInput.Deskew() foreach (var paragraph in page.Paragraphs) < // Pages ->Akapity int akaplarz = akapit.OKAGNICZA; String akraftext = akapit.Tekst; AnyBitMap Paragrafimage = akapit.TOBITMAP (ocrinput); int akaphx_location = akapit.X; int akapiza pkt.Y; int akapit = akapit.Szerokość; int akaphheight = akapit.Wysokość; podwójny akaptacja akapitu = akapit.Zaufanie; Ocrresult.TextFlow Paragrapthtext_Direction = akapit.Kierunek tekstu; foreach (linia var w akapicie.Linie) < // Pages ->Akapity -> linie int linium = linia.Numer kolejki; String lineText = linia.Tekst; AnyBitMap LineImage = Line.TOBITMAP (ocrinput); int linex_location = linia.X; int liney_location = linia.Y; int lineWidth = linia.Szerokość; int lineHeight = linia.Wysokość; podwójny liniaCducation = linia.Zaufanie; podwójne liniekeW = linia.Bazylean; podwójny linia linii = linia.BaselineOffset; foreach (var słowo w kolejce.Słowa) < // Pages ->Paragrafy -> Linie -> słowa int słowna liczba = słowo.Liczba słów; String WordText = Word.Tekst; AnyBitmap Wordimage = Word.TOBITMAP (ocrinput); int Wordx_Location = Word.X; int Wordy_Location = Word.Y; int WordWidth = Word.Szerokość; int wordheight = słowo.Wysokość; podwójny wordoccracation = Word.Zaufanie; Foreach (znak var w słowie.Postacie) < // Pages ->Akapity -> wiersze -> słowa -> znaki Int Characternumber = Charakterys.Charabinerumber; String ChaperText = Charakterys.Tekst; AnybitMap CharacterImage = Charakterys.TOBITMAP (ocrinput); int bohaterx_location = znak.X; int charaktery_lokacja = znak.Y; int charakterystyczny = charakter.Szerokość; int charakterHeight = Charakter.Wysokość; podwójny charakterokradacy = charakter.Zaufanie; // Wydaj alternatywne wybory symboli i ich prawdopodobieństwo. // bardzo przydatne do sprawdzania pisowni ocresult.Wybór [] wybory = znak.Wybory; >>>>>>Utwórz wyszukiwalne pliki PDF przez OCR
używając Ironocr; var octesseract = new irontesseract (); używając (var ocrinput = new ocrinput ())
Optyczne rozpoznawanie znaków (OCR) dla Windows 10
Optyczne rozpoznawanie znaków (OCR) jest częścią Universal Windows Platform (UWP), co oznacza, że można ją używać we wszystkich aplikacjach ukierunkowanych na system Windows 10. Za pomocą OCR możesz wyodrębnić informacje o układzie tekstu i tekstu z obrazów. To’S zaprojektowany do obsługi różnych rodzajów obrazów, od zeskanowanych dokumentów po zdjęcia. Jednocześnie jest wysoce zoptymalizowany i działa całkowicie na urządzeniu bez konieczności połączenia internetowego. Aktualizacja Windows 10 listopada umożliwia OCR dla czterech nowych języków, co zwiększa całkowitą liczbę obsługiwanych języków do 25.
Ta technologia była mocno przetestowana w Microsoft od lat. To’S używane w głównych produktach, takich jak Word, OneNote, OneDrive, Bing, Office, i tłumacz dla różnych scenariuszy, w tym indeksowanie obrazów, rekonstrukcja dokumentów i rzeczywistość rozszerzona.
Korzystanie z interfejsu API OCR jest bardzo proste, jak wykazał ten fragment kodu:
//…
// pozyskaj mapę bitową z pliku, aparatu,…
//…
Ocrengine ocrengine = ocrengine.TrycreateFromUserProfileLanguages ();
Ocrresult ocrresult = czekaj na ocrengine.Rozpoznawanie (bitmap);
String ExtractedText = ocrresult.Tekst;
Uruchamianie kodu na poniższym obrazku wyodrębnia następujący tekst:
“Podróżuj po świecie, widząc, że zabytki mają wspaniałe dni i lepsze noce”

Ocrresult można również użyć do pobierania wiersza tekstowego według wiersza lub znalezienia pozycji każdego słowa. Aby uzyskać więcej informacji, sprawdź próbkę kodu w dokumentacji GitHub i MSDN.
Ta praca to ewolucja biblioteki Microsoft OCR dla Windows Runtime, wydana w Nuget w 2014 roku. Jeśli użyłeś tej biblioteki w aplikacji dla systemu Windows/Windows Phone 8.1, przejście do nowego interfejsu API OCR w systemie Windows 10 będzie proste.
Jeśli musisz użyć OCR jako usługi, my’ve cię również zakryło. Ta sama technologia jest wydawana w ramach Project Oxford (zestaw usług dla naturalnych rozumienia danych – zalecamy sprawdzenie jej, ponieważ wprowadza szereg możliwości dla twoich aplikacji). W porównaniu do okien.Głoska bezdźwięczna.Przestrzeń nazw OCR, usługa ma dodatkowe funkcje, takie jak wykrywanie języka i wykrywanie orientacji tekstu. Spróbuj eksperymentować z demonstracją usług OCR i uzyskaj szczegółowe informacje w dokumentacji API.
My’Czekam na nowe, niesamowite aplikacje zasilane OCR w sklepie z systemem Windows. Jeśli ty’D chciałbym udostępniać opinie, zadawać pytanie lub rozpocząć dyskusję, napisz na forum MSDN. My’Z niecierpliwością czekam na odpowiedź!
Napisane przez Pavle Josipovic, inżynier oprogramowania w zespole analogowym
Najlepsze oprogramowanie OCR dla systemu Windows 10 do użycia w 2023
Spójrz na nasze wybrane rozwiązania i wybierz dla siebie odpowiednie oprogramowanie OCER
Ekspert w systemie Windows & Software
Madalina jest fanem Windows, odkąd zdobyła swój pierwszy komputer Windows XP. Jest zainteresowana technologią wszystkich rzeczy, zwłaszcza rozwijających się technologii. Czytaj więcej
Zaktualizowano 6 marca 2023
Zrecenzowany przez VLAD TURICEANU
Redaktor naczelny
Pasjonowany technologią, oknami i wszystkim, co ma przycisk zasilania, spędził większość czasu na rozwijaniu nowych umiejętności i uczeniu się o świecie technologii. Nadchodzący. Czytaj więcej
- Dzięki najlepszemu oprogramowaniu OCR możesz przekonwertować zeskanowane, wydrukowane lub odręczne pliki obrazów na w pełni edytowalne pliki.
- W poniższym artykule pokażemy najlepsze bezpłatne oprogramowanie OCR dla systemu Windows 10, którego możesz użyć.
- Wybraliśmy aplikacje OCR dla systemu Windows 10, które obsługują wiele typów plików.
- Istnieją świetne oprogramowanie OCR, z których można łatwo użyć.

Być może zauważyłeś, że papier ma’T nie odszedł, ale cyfryzacja powoli przejmuje kontrolę.
W tym miejscu wchodzi optyczne rozpoznawanie znaków (OCR). Oprogramowanie OCR umożliwia digitalizację drukowanych lub odręcznych dokumentów, czyniąc je edytowymi według programów edytora tekstu.
Optyczne rozpoznawanie znaków (OCR) to program, który może przekonwertować zeskanowane, wydrukowane lub odręczne pliki obrazów na format tekstu, który można odczytać.
Może masz książkę lub paragon, który wpisałeś lub wydrukowałeś lata temu i chcesz, aby umieściła ją w formacie cyfrowym, ale nie’T chcę to ponownie zorganizować. Oprogramowanie OCR może być bardzo przydatne w takim przypadku w systemie Windows 10.
Możemy również użyć tej wspaniałej technologii do dokładnego wyodrębnienia tekstu z obrazów i konwersji drukowanej tabeli na arkusz kalkulacyjny Excel lub starą książkę na pdf z tekstami podlegającymi wyszukiwaniu pod obrazami strony.
W tym artykule przedstawimy Ci najlepsze bezpłatne i płatne oprogramowanie do rozpoznawania znaków optycznych na rynku.
Jak korzystać z oprogramowania OCR w systemie Windows 10?
Optyczne rozpoznawanie znaków (OCR) może być używane we wszystkich aplikacjach ukierunkowanych na system Windows 10, ponieważ jest częścią platformy Universal Windows.
OCR jest tworzony, aby pomóc Ci zarządzać różnymi rodzajami obrazów, od zeskanowanych dokumentów po zdjęcia, dzięki czemu możesz użyć go do wyodrębnienia informacji o układzie tekstu i tekstu.
Jak mogę wybrać, które oprogramowanie OCR do pobrania?
To jest główne pytanie, które możesz mieć przed pobraniem OCR. Pomożemy Ci wybrać, odpowiadając na bardziej szczegółowe pytania:
Jakie są najlepsze narzędzia programowe OCR dla systemu Windows 10?
Soda PDF-w pełni funkcjonowane narzędzia do edycji
Soda PDF oferuje szeroką gamę rozwiązań dla twojego pakietu biurowego wraz z potężnym narzędziem OCR, które pomoże ci zdigitalizować dokumenty.
Przekształcenie dokumentów w tekst cyfrowy bez ponownego pisania jest dość łatwy. Po prostu rób zdjęcia swoich fizycznych dokumentów za pomocą telefonu komórkowego, prześlij je do sody pdf i przekonwertuj na edytowalny pdf w ciągu kilku sekund.
To narzędzie bardzo elastyczne pozwala dostosować swoje narzędzie OCR w zależności od potrzeb. Dzięki automatycznemu i ręcznej skanowaniu masz pełną kontrolę nad transmisją tekstową.
Musisz jednocześnie skanować wiele obrazów lub dokumentów? Funkcja skanowania partii OCR pomaga rozpoznać tekst z wielu obrazów lub dokumentów, skracając czas konwersji.
Narzędzie OCR znajduje się w wersji PRO SODA PDF, która oferuje najlepszą wartość dla wszystkich potrzeb edycji PDF.
Soda PDF zawiera szereg innych narzędzi, które pomogą ci łatwiej i szybciej edytować pliki PDF:
- W pełni przedstawione możliwości edycji
- Łatwe tworzenie i konwersja PDF
- Scalanie i kompresja pliku
- Wypełnianie formularzy, ankiety i podpisy elektroniczne
Jeśli nie masz pewności, czy SODA PDF jest dla Ciebie odpowiednia, dostępna jest bezpłatna próba, która pozwala odkrywać wszystkie jego funkcje. Elastyczny system cen umożliwia wybór planu, który najlepiej Ci odpowiada.
Soda pdf
Przekształć dowolny obraz w tekst w kilka sekund za pomocą sody pdf!
Sprawdź cenę Odwiedź stronę
Adobe Acrobat DC (zalecany) – świetny konwerter

Adobe Acrobat DC jest przeznaczony dla użytkowników, którzy chcą cieszyć się potężnymi funkcjami oprogramowania do rozpoznawania znaków optycznych.
Wersja Adobe Acrobat DC obsługuje wiele plików wejściowych, takich jak .Doc, .Docx, .XLS, .XLSX, .ppt, .pptx, .Ps, .Eps, .PRN itp., więc łatwiej będzie wyodrębnić pożądaną część z tekstu w celu sformatowania i ponownego ponownego opanowania sekwencji.
Jest to łatwe i bardzo intuicyjne w użyciu, ponieważ działa dla Ciebie, automatycznie przekształcając sekcję tekstową ze zeskanowanego dokumentu na tekst, który można zmodyfikować w pliku PDF.
Ponadto możesz zarchiwizować swój dokument i dodać ograniczenia w celu ograniczenia możliwości edycji i kopiowania.
Możesz dodawać notatki, atrakcje i inne adnotacje i zmniejszyć rozmiar pdf, aby ułatwić udostępnianie. Umożliwia także wysyłanie dokumentów do innych w celu podpisywania i przekształcania istniejących formularzy i skanowania w wypełnione formularze PDF.
OCR jest automatycznie stosowany do dokumentu, więc będziesz mógł go edytować, wpisując pożądane sekwencje tekstu.
Spójrz na inne kluczowe cechy:
- Wypełnij i podpisz
- Zamawiień i wyodrębnia strony PDF
- Chroń funkcję PDF
- Porównaj pliki
- Podziel PDF na wiele plików
Adobe Acrobat DC
Wyodrębnij i przekonwertuj wszystkie zeskanowane pliki na edytowalne formaty, archiwum i chronić hasło.
Sprawdź cenę Odwiedź stronę
Abbyy Finereader – zaawansowane narzędzia korekcyjne

Abbyy Finereader to najpotężniejsze oprogramowanie OCR na rynku i jest najlepszym narzędziem dla każdego, kto potrzebuje szybkiego i dokładnego rozpoznawania tekstu.
Ten OCR doskonale obsługuje wysokiej pracy i jest wyposażony w zaawansowane narzędzia korekcyjne do trudnych zadań.
Znakomite narzędzie weryfikacyjne łatwo koryguje wątpliwe odczyty, dokonując zgrabnego porównania tekstów OCR z oryginałem.
Abbyy Finereader robi więcej, niż można się spodziewać po OCR. Czy to ta 500-stronicowa książka, którą chcesz przekonwertować na przeglądanie pliku PDF? Aplikacja obsługuje ją z najwyższą precyzją.
Abbyy wyodrębni najdokładniejsze teksty z obrazów znalezionych w Internecie i może przekonwertować zeskanowany dokument na HTML lub w formacie EPUB używane przez e-czytników.
Możesz dzielić się pomysłami, zbierać opinie od innych i otrzymywać zatwierdzenie dokumentów, oznaczając, komentując i rysując dokument bezpośrednio w pliku PDF dzięki narzędziom współpracy.
Dzięki temu oprogramowaniu możesz zastosować i weryfikować podpisy cyfrowe, wyczyścić poufne informacje, odłączyć ukryte dane i zarządzać dostępem do plików PDF.
Abbyy Finereader też to ma kluczowe cechy:
- Edytuj i organizuj pdfs
- Przelicz na wyszukiwanie pdfs
- Utwórz wypełnienie formularzy PDF
- Porównaj dokumenty w różnych formatach
- Optymalizuj procedury digitalizacji
Abbyy Finereader
Udostępnij, przekonwertuj i edytuj swoje pliki PDF w mgnieniu oka na oprogramowanie, które korzysta z technologii OCR z napędem AI.
Bezpłatny proces Odwiedź stronę
Readiris-rzadka funkcja oszczędzania chmur
Readiris to najnowsza wersja tego wysokowydajnego oprogramowania OCR. Jest wyposażony w nowy interfejs, nowy silnik rozpoznawania i szybsze zarządzanie dokumentami.
Wskazówka eksperta:
Sponsorowane
Niektóre problemy z komputerem są trudne do rozwiązania, szczególnie jeśli chodzi o uszkodzone repozytoria lub brakujące pliki systemu Windows. Jeśli masz problemy z ustaleniem błędu, system może zostać częściowo zepsuty.
Zalecamy zainstalowanie Restoro, narzędzie, które skanuje Twój komputer i określi, jaka jest usterka.
Kliknij tutaj, aby pobrać i rozpocząć naprawę.
Możesz łatwo przekonwertować na wiele różnych formatów, w tym pliki audio dzięki jego słownej rozpoznawaniu. Readiris obsługuje większość formatów plików i ma inne atrakcyjne funkcje, które upraszczają proces konwersji.
Na przykład obrazy mogą być pozyskiwane z podłączonych urządzeń, takich jak skanery, a aplikacja pozwala również dostosować parametry przetwarzania, takie jak regulacje DPI.
Readiris ma rzadką funkcję oszczędzania w chmurze, która pozwala użytkownikom zapisać wyodrębniony tekst na różne usługi przechowywania w chmurze, takie jak Dysk Google, OneDrive, Dropbox i inne.
Jest idealny do współpracy, ponieważ oferuje grupę narzędzi, dzięki czemu możesz adnotować, komentować i dołączać linie hipertekstowe na plikach PDF.
Dzięki Readiris możesz podpisać i chronić swoje pliki PDF i wysłać je elektronicznie. Możesz także edytować teksty osadzone na zdjęciach, ponieważ jego silnik OCR pozwala odzyskać teksty we wszystkich plikach, zachowując oryginalny format z nieskazitelną dokładnością.
Oto inne Świetne funkcje z Readiris:
- Rozpoznaj teksty w wielu językach
- Zintegruj słowne rozpoznawanie
- Dodaj znaki wodne
- Edytuj style postaci
- Wizualizuj adnotacje w jednym widoku
Readiris
Konwertuj formaty audio i utwórz edytowalne pliki ze zeskanowanych dokumentów. Zdobądź najlepszą ofertę teraz!
Bezpłatny Odwiedź stronę
Prosty OCR-przyjazny dla użytkownika interfejs
Simpleococ to przydatne narzędzie, którego możesz użyć do konwersji twardego wydruku na edytowalne pliki tekstowe.
Jeśli masz wiele odręcznych dokumentów i chcesz je przekonwertować na edytowalne pliki tekstowe, to Simpleoct byłby najlepszą opcją.
Jednak odręczna ekstrakcja ma ograniczenia i jest oferowane tylko jako 14 dni bezpłatnego procesu. Wydruk maszyny jest bezpłatny i nie ma ograniczeń.
Tam’S wbudowany sprawdzanie zaklęć, którego można użyć do sprawdzania rozbieżności w przekonwertowanym tekście. Możesz także skonfigurować oprogramowanie do odczytania bezpośrednio ze skanera.
Podobnie jak Microsoft OneNote, SimpleCoc nie obsługuje tabel i kolumn.
Freeocr – automatyczne czyszczenie skanowania
Freeocr wykorzystuje silnik Tesseract, który został stworzony przez HP i jest obecnie utrzymywany przez Google.
Tesseract jest bardzo potężnym silnikiem i mówi się, że jest jednym z najdokładniejszych silników OCR na świecie.
FreeOct radzi sobie z formatami PDF i ma obsługę urządzeń Twain, takich jak kamery cyfrowe i skanery obrazów.
Ponadto obsługuje prawie wszystkie znane pliki obrazów i wielostronicowe pliki TIFF. Możesz użyć oprogramowania do wyodrębnienia tekstu ze zdjęć i robi to z wysokim poziomem dokładności.
I, podobnie jak inne rozwiązania oprogramowania OCR dla systemu Windows 10 z tej listy, darmowy OCR może’T Przetłumacz tabele i kolumny.
Boxoft Free OCR – łatwe w użyciu
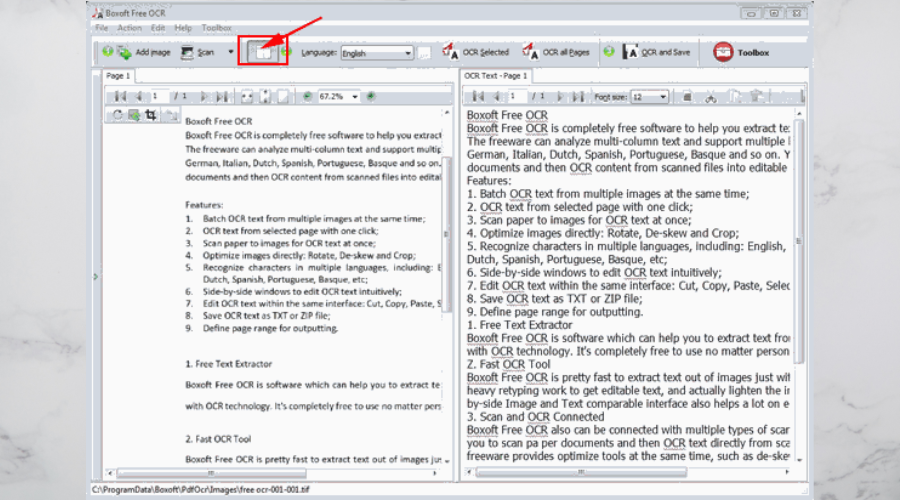
Boxoft Free OCR to kolejne poręczne narzędzie, którego można użyć do wyodrębnienia tekstu z wszelkiego rodzaju obrazów.
To darmowe oprogramowanie jest łatwe w użyciu i jest w stanie analizować tekst wielkolumnowy z dużą dokładnością.
Obsługuje wiele języków, w tym angielski, hiszpański, włoski, holenderski, niemiecki, francuski, portugalski, baskijski i wiele innych.
To oprogramowanie OCR pozwala skanować dokumenty papierowe i przekształca je w edytowalne teksty w bardzo krótkim czasie.
Chociaż istnieją obawy, że ten OCR’T Excel W wyodrębnianiu tekstu z odręcznych notatek, działa wyjątkowo dobrze z wydrukowaną kopią.
TOPOCR READER-WSPÓŁPROMATY

Czytnik topocra różni się od typowego oprogramowania OCR w wielu aspektach, ale dokładnie wykonuje pracę. Działa najlepiej z kamerami cyfrowymi i skanerami.
Jego interfejs jest również inny, ponieważ ma dwa okna – okno obrazu (źródło) i okno tekstowe.
Po pozyskiwaniu obrazu z kamery lub skanera po lewej stronie wyodrębniony tekst pojawia się po prawej stronie, gdzie jest edytor tekstu.
Oprogramowanie obsługuje formaty GIF, JPEG, BMP i TIFF. Wyjście można również przekonwertować na wiele formatów, w tym PDF, HTML, TXT i RTF.
Narzędzie jest również wyposażone w ustawienia filtra aparatu, które można zastosować, aby ulepszyć obraz.
Rynek jest zalany programami OCR, które mogą wyodrębniać tekst z obrazów i zaoszczędzić dużo czasu, które mogłeś spędzić retipowanie dokumentu.
Jednak dobre oprogramowanie OCR powinno robić więcej niż wyodrębnić tekst z drukowanych dokumentów.
Powinien utrzymać układ, czcionki tekstowe i format tekstu jako dokument źródłowy.
Mamy nadzieję, że ten artykuł pomoże Ci znaleźć najlepsze oprogramowanie OCR dla systemu Windows 10. Zapraszam do komentowania i udostępniania.
5 OCR sposobów wyodrębnienia tekstu z obrazów w systemie Windows 10
Optyczne rozpoznawanie znaków (OCR) to bardzo przydatna technika, która wyodrębnia tekst ze zeskanowanego obrazu lub zdjęcia obrazu. To’S był szeroko stosowany jako forma wpisu informacji z drukowanych kopii w wielu miejscach. Często przyjmuje się rozwiązanie do skanowania z wbudowaną funkcją OCR. Jeśli jednak nie masz’t mają takie wygodne funkcje skanowania, czy istnieją inne sposoby korzystania z tej technologii?
Oto kilka opcji, których można użyć w systemie Windows 10
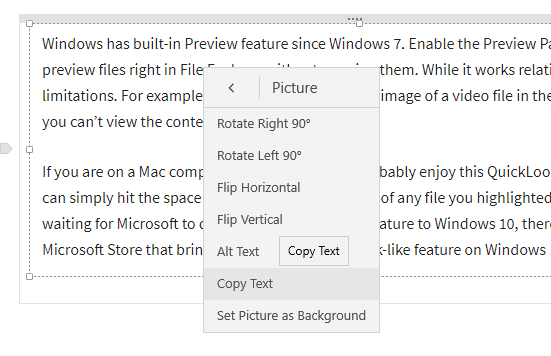
Jedna uwaga
To’S racja. Jeśli już używasz OneNote, masz już do cholery narzędzie. Po prostu kliknij prawym przyciskiem myszy obraz zawierający tekst, który chcesz wyodrębnić, wybierz Zdjęcie i wtedy Skopiuj tekst.
dysk Google
Dysk Google, dokładniej Dokumenty Google, ma dla Ciebie mało znaną bezpłatną funkcję OCR. Wszystko, co musisz zrobić Prześlij plik obrazu Najpierw na dysk Google i otworzyć go z Dokumenty Google.
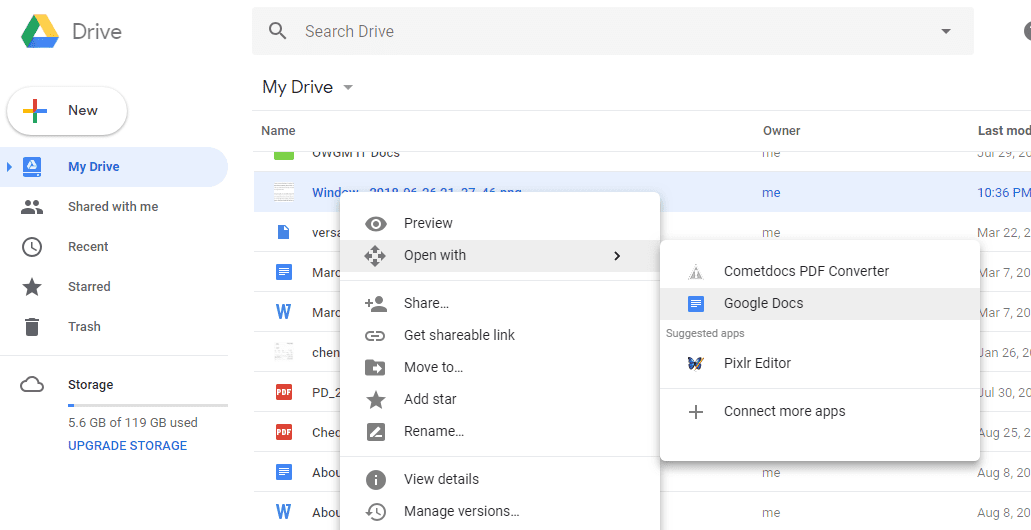
Po otwarciu pliku obrazu w Google Docs słowa osadzone w pliku obrazu są już wyodrębnione i wklejone w tym samym dokumencie. Dość wydajne, zgodziłbym się.
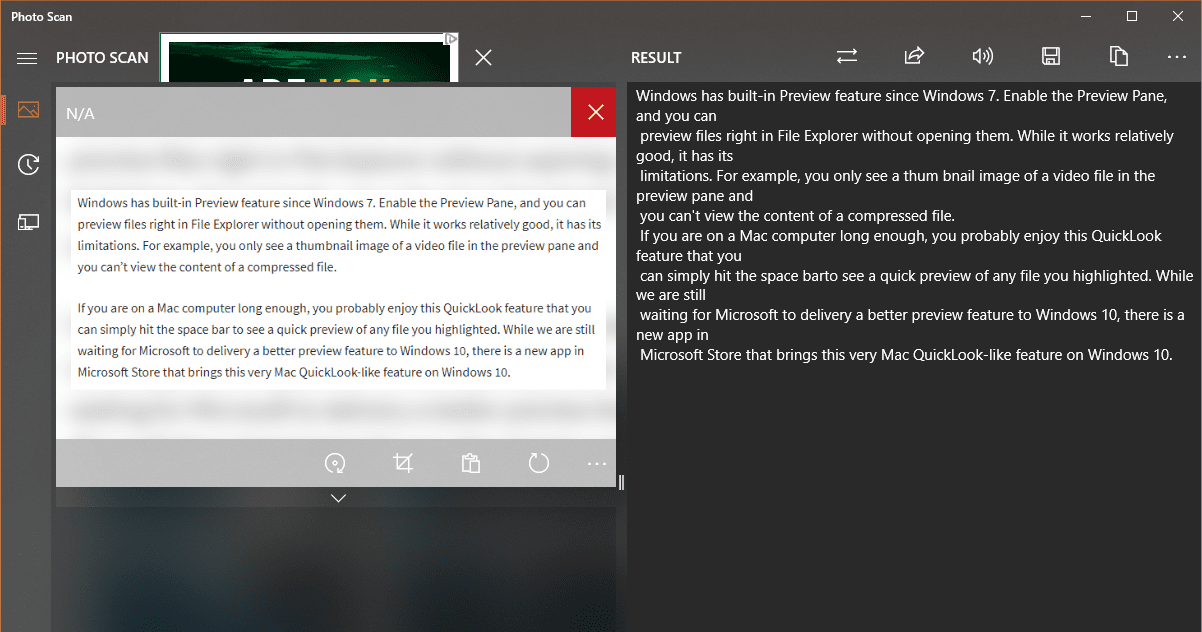
Skan fotograficzny
Skan fotograficznych to bezpłatna aplikacja UWP, która jest wyposażona w funkcję OCR wbudowaną, która łatwo wyodrębnia tekst z pliku zdjęć lub obrazów zaimportowany do aplikacji, czy to’s plik obrazu z komputera lub w schowku lub pobrany z aparatu.
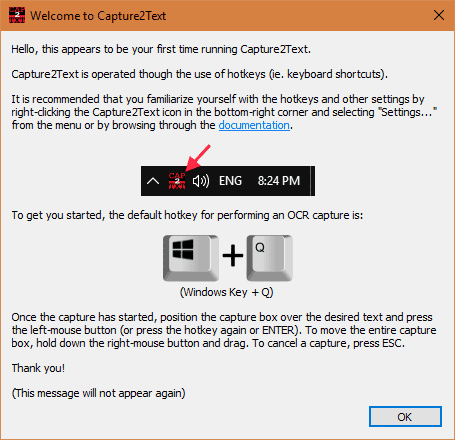
Capture2Text
Capture2Text to bezpłatne przenośne narzędzie, które pozwala szybko uzyskać część ekranu za pomocą skrótu klawiatury. Powstały tekst zostanie domyślnie zapisany do schowka. Obsługuje ponad 90 języków, nie tylko angielski, ale także chiński, francuski, niemiecki, japoński, koreański itp.
Freeocr
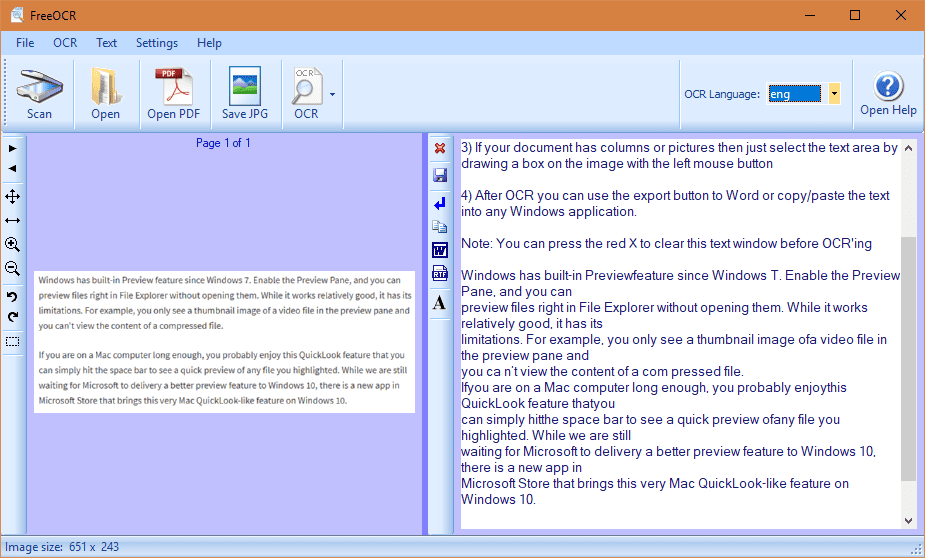
Freeocr to bezpłatne narzędzie OCR, które obsługuje skanowanie z większości skanerów Twain, a także może otworzyć większość zeskanowanych plików PDF’S i wielostronowe obrazy TIFF, a także popularne formaty plików obrazów. Wyświetla zwykły tekst, który można bezpośrednio wyeksportować do Microsoft Word Format. Jeśli szukasz narzędzia, które OCRS nie tylko pliki obrazów, ale także pdfs, Freeocr może być twoim facetem do pracy.
To’na razie o tym. To’jest wysoce możliwe, że istnieje wiele innych opcji, które nie zrobiliśmy’T okrywa. Ale jeśli którekolwiek z nich pomoże ci w jakikolwiek sposób, ciesz się.
powiązane posty
- Jak konwertować obrazy WebP na PNG, JPEG lub GIF w systemie Windows
- Powertoy nowe narzędzia
- Trzy różne metody, aby bezprzewodowo przesyłać obrazy dwukierunkowe od Androida do PC
- Dlaczego dysk twardy lub SSD nie pojawiają się na płycie głównej Gigabyte AB350m
- Jak skonfigurować kompatybilną kamerę internetową Windows Hello do automatycznego logowania

