
Czy WhatsApp używa Rabbitmq
Rabbitmq jest zbudowany Erlang Język programowania ogólnego przeznaczenia i jest również używany przez WhatsApp do wiadomości.
Streszczenie
WhatsApp używa Rabbitmq, który jest zbudowany na Erlang, jako kolejkę przesyłania wiadomości do dostarczania wiadomości.
Projektując system czatu w czasie rzeczywistym, ważne jest, aby rozważyć kolejkę używaną przez popularne platformy wiadomości, takie jak WhatsApp i Facebook Messenger. Chociaż może wydawać się logiczne, aby mieć kolejkę dla osoby lub kafka dla każdego użytkownika, biorąc pod uwagę miliardy użytkowników na tych platformach, takie podejście wymagałoby niepraktycznej liczby kolejek lub tematów. Jednak zaobserwowano, że WhatsApp i Facebook Messenger używają kolejki o nazwie „Iris” (podobnie jak Kafka) do dostarczania wiadomości.
Istnieją systemy wewnętrzne, które wypełniają bazy danych (takie jak HBase i MyRocks) z kolejki wiadomości, ale te bazy danych nie są głównym systemem dostarczania.
Pytania i odpowiedzi
1. Na czym zbudowano Rabbitmq?
Rabbitmq jest zbudowany na języku programowania ogólnego przez Erlang.
2. Jak WhatsApp używa Rabbitmq?
WhatsApp używa Rabbitmq jako kolejki przesyłania wiadomości do dostarczania wiadomości.
3. Jaki jest cel kolejki przesyłania wiadomości?
Kolejka przesyłania wiadomości służy do oddzielenia komponentów systemu, umożliwiając wysyłanie wiadomości między nimi asynchronicznych.
4. Czy w kolejce na osobę można użyć do dostarczania wiadomości w WhatsApp lub Facebook Messenger?
Chociaż kolejka peronitu może wydawać się logiczna, wymagałaby niepraktycznej liczby kolejek, biorąc pod uwagę miliardy użytkowników na tych platformach.
5. Z jakiej kolejki jest używana przez WhatsApp i Facebook Messenger do dostarczania wiadomości?
WhatsApp i Facebook Messenger używają kolejki o nazwie „Iris” do dostawy wiadomości. „Iris” jest podobny do Kafki.
6. Jakie są niektóre bazy danych używane przez WhatsApp do przechowywania wiadomości?
WhatsApp używa baz danych, takich jak HBase i MyRocks do przechowywania wiadomości. Te bazy danych są wypełnione z kolejki wiadomości.
7. Czy rabbitmq jest podstawowym systemem dostarczania dla WhatsApp?
Nie, Rabbitmq nie jest podstawowym systemem dostarczania WhatsApp. Jest używany jako kolejka przesyłania wiadomości do dostarczania wiadomości.
8. Czy dostarczenie wiadomości w WhatsApp i Facebook Messenger synchroniczny lub asynchroniczny?
Dostawa wiadomości w WhatsApp i Facebook Messenger jest asynchroniczna, co oznacza, że wiadomości są wysyłane i odbierane niezależnie od siebie.
9. Jakie są korzyści z korzystania z kolejki przesyłania wiadomości, takiej jak Rabbitmq?
Korzystanie z kolejki przesyłania wiadomości, takiej jak Rabbitmq, pozwala na oddzielanie komponentów, lepszą skalowalność i asynchroniczną komunikację między elementami systemowymi.
10. Czy Rabbitmq może obsłużyć wysokie ilości wiadomości?
Tak, RabbitMQ jest zaprojektowany do obsługi dużych wolumenów wiadomości i jest w stanie je wydajnie i niezawodnie dostarczać je.
11. Jakie są alternatywy dla Rabbitmq do wdrożenia kolejki przesyłania wiadomości?
Niektóre alternatywy dla RabbitMQ obejmują strumienie Apache Kafka, ActiveMQ i Redis.
12. Czy istnieją jakieś ograniczenia korzystania z kolejki przesyłania wiadomości, takiej jak Rabbitmq?
Pewne ograniczenia korzystania z kolejki przesyłania wiadomości, takie jak RabbitMQ, obejmują potrzebę prawidłowego skonfigurowania i dostrojenia go w celu uzyskania optymalnej wydajności, potencjalnej utraty wiadomości, jeśli nie jest właściwie skonfigurowana oraz potrzeba dodatkowej infrastruktury do obsługi kolejki przesyłania wiadomości.
13. Czy Rabbitmq można użyć do innych celów oprócz wiadomości?
Tak, Rabbitmq może być używany do innych celów oprócz wiadomości, takich jak planowanie zadań, architektury oparte na zdarzeniach i przesyłanie strumieniowe danych.
14. Czy Rabbitmq obsługuje trwałość wiadomości?
Tak, Rabbitmq obsługuje trwałość wiadomości, umożliwiając przechowywanie i pobieranie wiadomości nawet w przypadku awarii systemu.
15. W jaki sposób Rabbitmq zapewnia niezawodność dostarczania wiadomości?
Rabbitmq zapewnia niezawodność dostarczania wiadomości poprzez funkcje takie jak potwierdzenie wiadomości, wydawca potwierdza i trwałość kolejki.
Czy WhatsApp używa Rabbitmq
Rabbitmq jest zbudowany Erlang Język programowania ogólnego przeznaczenia i jest również używany przez WhatsApp do wiadomości.
Kolejka używana w WhatsApp lub FB Messenger
Myśląc o projekcie systemu na czacie w czasie rzeczywistym, jestem ciekawy, jakiego rodzaju kolejki WhatsApp lub FB Messenger używa po stronie serwera, aby dostarczyć wiadomość do odbiorcy. Myślałem, że jest kolejka perspektytu/kafka-topic, więc kiedy nowa wiadomość musi być dostarczona do użytkownika A, wiadomość jest enqueue do kolejki A. Mogą jednak być miliardy użytkowników (FB ma 2 miliardy użytkowników), czy to oznacza, że potrzebujemy 2 miliardów kolejek/tematów (w okresie Kafka)? Jeśli tak, to, którą kolejka może sobie z tym poradzić. Każdy komentarz jest mile widziany! Dziękuję!
zapytał 25 czerwca 2019 o 16:44
1 669 8 8 złotych odznak 23 23 Srebrne odznaki 37 37 brązowych odznaki
Można znaleźć dokumentację, że Messager został zbudowany przez HBase, a teraz myRocks. Istnieją systemy wewnętrzne, które wypełniają te bazy danych z kolejki, tak, ale nie jest to główny system dostarczania. kod.pełne wyżywienie.com/core-data/…
26 czerwca 2019 o 3:08
@Cricket_007 Dzięki za komentarze. Yeap, wygląda na to, że FB używa tęczówki (kafka jak) jako kolejka do dostawy.
alifzl/yomkippur
Ten zatwierdzenie nie należy do żadnego oddziału w tym repozytorium i może należeć do widelca poza repozytorium.
Przełącz gałęzie/tagi
Tagi gałęzi
Nie mogło załadować gałęzi
Nic do pokazania
Nie mogło załadować tagów
Nic do pokazania
Nazwa już używana
Tag już istnieje z podaną nazwą gałęzi. Wiele poleceń git akceptuje nazwy tagów i gałęzi, więc tworzenie tej gałęzi może powodować nieoczekiwane zachowanie. Czy na pewno chcesz utworzyć tę gałąź?
Anuluj Utwórz
- Lokalny
- Kodespaces
Https github cli
Użyj git lub kasy z SVN za pomocą adresu URL internetowego.
Pracuj szybko z naszym oficjalnym CLI. Dowiedz się więcej o CLI.
Rejestracja jest wymagana
Zaloguj się, aby korzystać z kodesprzeń.
Uruchamianie pulpitu Github
Jeśli nic się nie stanie, pobierz github komputer i spróbuj ponownie.
Uruchamianie pulpitu Github
Jeśli nic się nie stanie, pobierz github komputer i spróbuj ponownie.
Uruchamianie Xcode
Jeśli nic się nie stanie, pobierz Xcode i spróbuj ponownie.
Uruchamianie kodu Visual Studio
Twój kodespace otworzy się po gotowaniu.
Wystąpił problem z przygotowaniem kody.
Najnowsze zatwierdzenie
GIT Stats
Akta
Nie udało się załadować najnowszych informacji o zatwierdzeniu.
Najnowsza wiadomość o zatwierdzeniu
Popełnić czas
Readme.MD
Jom Kippur to narzędzie do automatyzacji WhatsApp, które ma być spójnym i stałym rozwiązaniem dla niekomercyjnego użycia WhatsApp jako zautomatyzowanego bota.
Co to robi?
- Wyślij/otrzymuj pojedynczą wiadomość w wstępnie skonfigurowanej aplikacji WhatsApp w AVD (urządzenie wirtualne Android)
- Utwórz listę kontaktową w AVD i użyj go do wysyłania/odbierania rzeczy
- Dosłownie może zrobić wszystko z AVD (tworzy wiele możliwości przekonania)
Na pierwszym miejscu widziałem Yowsup mój jedyny wybór, ale ze względu na wymienione poniżej problemy zmieniłem zdanie, aby wdrożyć go w inny sposób:
- Różnorodność problemów społecznościowych (tu powiązane)
- Yosup to asynchroniczny rodzaj interfejsu API, który wchodzi w interakcje z WhatsApp Restapi, w odniesieniu do rozważań WhatsApp o wysokim poziomie bezpieczeństwa, był bardzo wrażliwy na obecne sesje aktywnych każdego użytkownika i nie będzie bardzo przyjazne z synchronicznymi rozwiązaniami. (Jak prawdopodobnie znasz ograniczenia korzystania z widoku internetowego WhatsApp, które mówi, że powinniśmy mieć jednocześnie spójne aktywne połączenie internetowe)
- Mój lenistwo, a także rzucam sobie wyzwanie, aby zrobić to w trudnej sytuacji
Cóż, zależności w tym projekcie, są one raczej dużo! Pierwszy z was powinien mieć spełnienie tych wymagań:
Instalatorzy systemu Windows są odświeżeni, ale może to być implement w systemie Linux lub MacOS (oba nie są testowane)
| Zależność | Opis / Pobierz linki |
|---|---|
| Android Studio | Android Studio z Android API 28 |
| JAWA | Java JDK 11 |
| Mysql | Mysql Installer Community 8.X lub nowsze |
| Python 2.7 | Python 2.7 |
| Appium | V1.10 lub więcej |
| Rabbitmq | Najnowsza wersja Rabbitmq |
| Listonosz | Najnowsza wersja Postman |
Rozważania: Możesz użyć Cdai virenv do Pythona 2.7, ale napędzało mi to poważny ból głowy (nie zalecany)
Głównym powodem, dla którego użyłem Python 2 dla tego projektu, jest to, że Appaum, MySQL Connector Client i RabbitMQ były niezgodne w wersji 3.
Po pierwsze, bądź cierpliwy w tej części. Zajęło mi krew i łzy, aby wytrzeć gówno zależności za takie proste zadanie.
1.Urządzenie wirtualne Android
LUACH AVD Manager w Android Studio, skonfiguruj urządzenie z Androidem 9.0 z API 28 (wybór i odpowiednia nazwa dla AVD, ponieważ potrzebujemy go w kolejnych krokach).
Zauważ, że powinieneś zainstalować WhatsApp za pośrednictwem samego AVD, więc wybierz wersję obsługiwaną przez Playstore.
Sprawdź, czy masz te zmienne środowiskowe na swoim koncie:
| Nazwa zmiennej | Wartość zmienna |
|---|---|
| Android_Home | C: \ Users \ fzl \ appData \ Local \ Android \ sdk |
| Java_home | C: \ Program Files \ Java \ JDK-111.0.2 |
| Pythonpath | C: \ python27; c: \ python27 \ lib \ site-packages; c: \ python27 \ lib; c: \ python27 \ dlls; c: \ python27 \ skrypty Scripts |
| Skrawek | C: \ Python27; C: \ Python27 \ Scripts; C: \ Python27 \ lib \ Site-Packages; C: \ Program Files \ Java \ Jdk-111.0.2; C: \ Program Files \ Java \ JDK-111.0.2 \ bin; |
Następnie powinieneś uruchomić AVD, zainstalować WhatsApp w tym, a także autoryzować ADB z urządzeniem (obowiązkowe)
Aby to zrobić, powinieneś wykonać urządzenia ADB lub ADB USB, aby sprawdzić autoryzację AVD.
C:\ USers\FZl\Appdata\ LOcal\Android\SDk\PLatform-tools: Lista urządzeń ADB dołączone urządzenia emulator-5554 urządzenia
Jeśli widzisz nieautoryzowany wynik, powinieneś kliknąć ten link.
2.Konfiguracja Rabbitmq
Po zainstalowaniu Raabitmq należy uruchomić Rabbitmq-Plugins Włącz Rabbitmq_Management w katalogu Rabbitmq SBIN w celu włączenia internetowego-gui SYTEM RAMBITMQ SYTEM. może być potrzebne ograniczenie usługi Rabbitmq.
Następnie powinieneś mieć dostęp do rabbitmq web-gui z http: // localhost: 15672/#/adres w komputerze lokalnym. Jeśli tak, utwórz nowego użytkownika według poniższych poleceń i uczyń go administratorem:
Rabbitmqctl add_user hasło nazwy użytkownika # To sprawia, że użytkownik jest administratorem rabbitmqctl set_user_tags administrator nazwy użytkownika # To ustawia uprawnienia dla użytkownika rabbitmqctl set_permissions -p / nazwa użytkownika ".*" ".*" ".*"
Zaloguj się z nowo utworzonymi poświadczeniami i importuj specyfikacje kolejki, które są już dołączone do tego repozytorium, które nazywa się rabbitmq_conf.JSON w sekcjach definicji importu w ramach przeglądu menue.
Utworzy to niezbędne konfiguracje dla RabbitMQ i umożliwia potrzebne uprzywilejowanie.
3.Appium
Wystarczy uruchomić serwer Appium z domyślnymi ustawieniami. Appium–default-capabilities ” jest już osadzony w kodzie. Tl; Dr: W tym kroku nie ma nic do zrobienia.
4.Mysql
Zainstaluj edycję Community MySQL, utwórz odpowiednie konto DB i ustaw obsługę usługi, gdy system operacyjny uruchomi się.
5.Zainstaluj zależności Pythona
Po prostu uruchom zależności instalacji PIP –R.TXT w celu rozwiązania zależności używanych bibliotek.
Możesz stawić czoła przestarzałej wersji biblioteki MySQLDB, która można rozwiązać za instalacją tego i tego. Zajmij się instalacją Python 2.x Wersja wspomnianych bibliotek.
6.Utwórz katalogi dla plików dziennika
Utwórz katalogi i pliki’s wspomniany poniżej:
# katalogi C:\ var\ lOG [katalog] c:\ var\ lOG\ whatsapp_api [katalog] # pliki dziennika C:\ var\ lOG\ALiczba Pi.Log C:\ var\ lOG\ wHatsapp_single_consumer.Log C:\ var\ lOG\ wHatsApp_Single_Worker.Log C:\ var\ lOG \
7.Ustaw Jom Kippur’s Plik konfiguracyjny
Przejdź do Yomkippur-Master \ Config \ Config.CFG i wprowadza następujące.
(Nie zmieniaj niczego esle, chyba że wiesz, co robisz)
[mysql] host = 127.0.0.1 nazwa użytkownika ='Twoja nazwa użytkownika Mysql' hasło ='Twoje hasło MySQL' baza danych = WhatsApp [rabbitmq] ip = 127.0.0.1 ipququeuename = iPaddr.Nazwa użytkownika kolejki ='Twoja nazwa użytkownika Rabbitmq' hasło ='Twoje hasło Rabbitmq' [Kolejka_nazwa] single_message = WhatsApp_Singlemessage_Queue Broadcast_message = WhatsApp_Broadcastmessage_Queue add_contact = WhatsApp_Newcontact_Listener_Queue Listen_Message = WhatsApp_Messagelistener_Queue
Uruchom główny.PY i add_new_contact_producer.PY w dwóch oddzielnych środowiskach terminal/CMD.
Jeśli nie widziałeś żadnego błędu, możesz iść.
- Upewnij się, że MySQL Server działa
- Upewnij się, że Rabbitmq Sever to Runnig
- Uruchom appium z ustawieniami deszcz
- Uruchom te skrypty
Python Main.Py Python add_new_contact_producer.Py Python single_message_producer.py
- Uruchom listonosz i utwórz pożądane polecenia post z listy poniżej:
Dodawanie kontaktu w aplikacji Google Contacts
Wysyłanie pojedynczej wiadomości za pośrednictwem WhatsApp
Rozwój i wkład?
Chcesz wnieść wkład? Świetnie! Nie krępuj się powalić.fazeli95 [at] gmail [dot] com lub po prostu utworzyć żądanie ciągnięcia.
Wszystkie komponenty używane w tym projekcie są open source i mają licencję MIT i można je wykorzystać w każdym produkcie niezachwialnym
O
Broker wiadomości WhatsApp z Rabbitmq, AVD i Appium
Wprowadzenie do Rabbitmq
Tutaj dowiemy się, co to jest Rabbitmq, zastosowania Rabbitmq i dlaczego musimy używać Rabbitmq w naszych aplikacjach z przykładami.
Co to jest Rabbitmq?
Rabbitmq jest AMQP Messaging Broker i jest to najpopularniejszy broker wiadomości typu open source i cross-platform.
Rabbitmq jest również sposobem na wymianę danych między różnymi aplikacjami platformowymi, takimi jak wiadomość wysyłana z .Internet Aplikacja może być odczytana przez Węzeł.JS aplikacja lub Jawa aplikacja.
Rabbitmq jest zbudowany Erlang Język programowania ogólnego przeznaczenia i jest również używany przez WhatsApp do wiadomości.
Co to jest AMQP?
Zaawansowany protokół w kolejce wiadomości (AMQP) to otwarty standardowy protokół warstwy aplikacji dla zorientowanej na komunikaty, a cechy AMQP to orientacja komunikatów, kolejka, routing (w tym punkt-punkt i publikacja i subskrypcja), niezawodność i bezpieczeństwo.
Został opracowany przez JPMorgan i Imatix Corporation. AMQP został zaprojektowany z następującymi głównymi cechami jako cele:
- Bezpieczeństwo
- Niezawodność
- Interoperacyjność
- Standard
- otwarty
Rabbitmq jest lekki i łatwy do wdrożenia w dostępnych lokalizacjach i obsługuje wiele protokołów przesyłania wiadomości. Rabbitmq może być wdrażany w konfiguracjach rozproszonych i federowanych, aby spełnić wymagania o wysokiej jakości i dostępności.
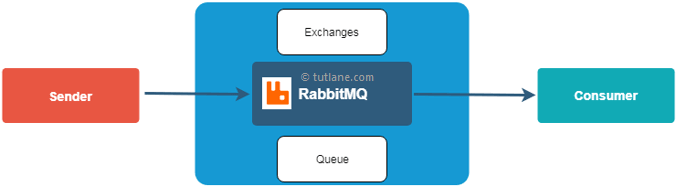
Poniżej znajduje się obrazowy przedstawienie, w jaki sposób Rabbitmq będzie działał jako mediator między nadawcą a konsumentem w naszych aplikacjach.
Dlaczego i kiedy korzystać z Rabbitmq?
Teraz kilka dni większość ludzi wykona wiele zadań w pojedynczej aplikacji, takich jak wysyłanie e -maili lub SMS, raporty, a on stworzy duże obciążenie aplikacji, więc jeśli oddzielić te zadania, otrzymamy więcej miejsca (pamięci), aby obsłużyć więcej żądań.
Korzystając z RabbitMQ, możemy usunąć ciężką pracę z naszych aplikacji internetowych, takich jak wysyłanie raportów w formacie Excel lub PDF’s lub wysyłanie wiadomości e -mail, SMS lub inne zadanie, takie jak wyzwalając niektóre inne aplikacje do rozpoczęcia przetwarzania.
Rabbitmq to broker wiadomości typu open source i cross-platform, więc’jest łatwy w użyciu z wieloma językami, takimi jak .Net, Java, Python, Ruby, węzeł.JS.
Rabbitmq obsługiwał biblioteki klientów
Rabbitmq będzie obsługiwał wiele systemów operacyjnych i języków programowania. Rabbitmq dostarczył różne biblioteki klientów do następujących języków programowania.
- .Internet
- Jawa
- Spring Framework
- Rubin
- Pyton
- Php
- CORSIVE-C i SWIFT
- JavaScript
- IŚĆ
- Perl
Projektowanie systemu: WhatsApp
Zaprojektujmy usługę WhatsApp, takiego jak komunikatyczne wiadomości, podobnie jak usługi takie jak WhatsApp, Facebook Messenger i WeChat.
Co to jest WhatsApp?
WhatsApp to aplikacja do czatu, która świadczy usługi komunikatów informacyjnych dla swoich użytkowników. Jest to jedna z najczęściej używanych aplikacji mobilnych na planecie łączącej ponad 2 miliardy użytkowników w ponad 180 krajach. WhatsApp jest również dostępny w Internecie.
Wymagania
Nasz system powinien spełniać następujące wymagania:
Wymagania funkcjonalne
- Powinien obsłużyć czat jeden na jednego.
- Czaty grupowe (maksymalnie 100 osób).
- Powinien obsługiwać udostępnianie plików (obraz, wideo itp.).
Wymagania niefunkcjonalne
- Wysoka dostępność z minimalnym opóźnieniem.
- System powinien być skalowalny i wydajny.
Rozszerzone wymagania
- Wysłane, dostarczane i czytane wpływy wiadomości.
- Pokaż ostatni czas użytkowników.
- Powiadomienia push.
Szacowanie i ograniczenia
Zacznijmy od oszacowania i ograniczeń.
UWAGA: Upewnij się, że sprawdź dowolną skalę lub założenia związane z ruchem drogowym z ankieterem.
Ruch drogowy
Załóżmy, że mamy 50 milionów aktywnych użytkowników (DAU) i średnio każdy użytkownik wysyła co najmniej 10 wiadomości do 4 różnych osób każdego dnia. Daje nam to 2 miliardy wiadomości dziennie.
50 m i l l i o n × 20 m e s a g e s = 2 b i l l i o n / d a y 50 \ space milion \ Times 20 \ Komunikaty o przestrzeni = 2 \ Space miliard / dzień 50 mi ll i o n × 20 m ess a g es = 2 bi ll i o n / d a y y y y y y y y y y y y y y y y
Wiadomości mogą również zawierać media, takie jak obrazy, filmy lub inne pliki. Możemy założyć, że 5 procent wiadomości to pliki multimedialne udostępniane przez użytkowników, co daje nam dodatkowe 200 milionów plików, które musielibyśmy przechowywać.
5 p e r c e n t × 2 b i l l i o n = 200 m i l l i o n / d A y 5 \ Space Procent \ Times 2 \ Space miliard = 200 \ Space Million / dzień 5 P erce n t × 2 bi ll i o n = 200 mi ll i o n / d a y y y y y y y y y y y y
Jakie byłyby żądania na sekundę (RPS) dla naszego systemu? 2 miliardy żądań dziennie Przekłada się na 24 tys. Żądań na sekundę.
2 B i l l i o n (24 h r s × 3600 s e c o n d s) = ∼ 24 k r e q u e s t s / s e c o n d \ frac<2 \space billion> <(24 \space hrs \times 3600 \space seconds)>= \ sim 24k \ żądania przestrzeni / sekunda (24 h rs × 3600 seco n d s) 2 bi ll i o n = ∼ 24 k re q u es t s / seco n d
### Pamięć, jeśli zakładamy, że każda wiadomość wynosi średnio 100 bajtów, będziemy potrzebować około 200 GB pamięci bazy danych każdego dnia.
2 B i l l i o n × 100 b y t e s = ∼ 200 g b / d a y 2 \ space miliard \ Times 100 \ Space bajty = \ sim 200 \ Space GB / dzień 2 bi ll i o n × 100 b y t es = ∼ 200 gb / d a y y y
Zgodnie z naszymi wymaganiami wiemy również, że około 5 procent naszych codziennych wiadomości (100 milionów) to pliki multimedialne. Jeśli założymy, że każdy plik ma średnio 50 kb, będziemy potrzebować 10 TB pamięci każdego dnia.
100 m i l l i o n × 100 k b = 10 t b / d a y 100 \ space milion \ Times 100 \ Space Kb = 10 \ Space Tb / dzień 100 mi ll i o n × 100 k b = 10 tb / d a y y y y y y y y y y y y y y y y y y y
I przez 10 lat będziemy potrzebować około 38 pb pamięci.
(10 t B + 0.2 T B) × 10 y e a r s × 365 d a y s = ∼ 38 p b (10 \ Space Tb + 0.2 \ Space Tb) \ Times 10 \ Space Years \ Times 365 \ Space Days = \ Sim 38 \ Space Pb (10 TB + 0.2 TB) × 10 ye a rs × 365 d a ys = ∼ 38 pb
### przepustowość jako nasz system obsługuje 10.2 TB wnikania każdego dnia będziemy wymagać minimalnej przepustowości około 120 MB na sekundę.
10.2 T B (24 H R S × 3600 S E C O N D S) = ∼ 120 M B / S E C O N D \ FRAC<10.2 \space TB> <(24 \space hrs \times 3600 \space seconds)>= \ sim 120 \ Space MB/Second (24 h rs × 3600 seco n d s) 10.2 TB = ∼ 120 MB / SECO N D
### Ocena wysokiego poziomu Oto nasze szacunki na wysokim poziomie:
| Typ | Oszacować |
|---|---|
| Codziennie aktywni użytkownicy (dau) | 50 milionów |
| Żądania na sekundę (RPS) | 24k/s |
| Przechowywanie (dziennie) | ~ 10.2 TB |
| Przechowywanie (10 lat) | ~ 38 pb |
| Przepustowość łącza | ~ 120 MB/s |
Projektowanie modelu danych
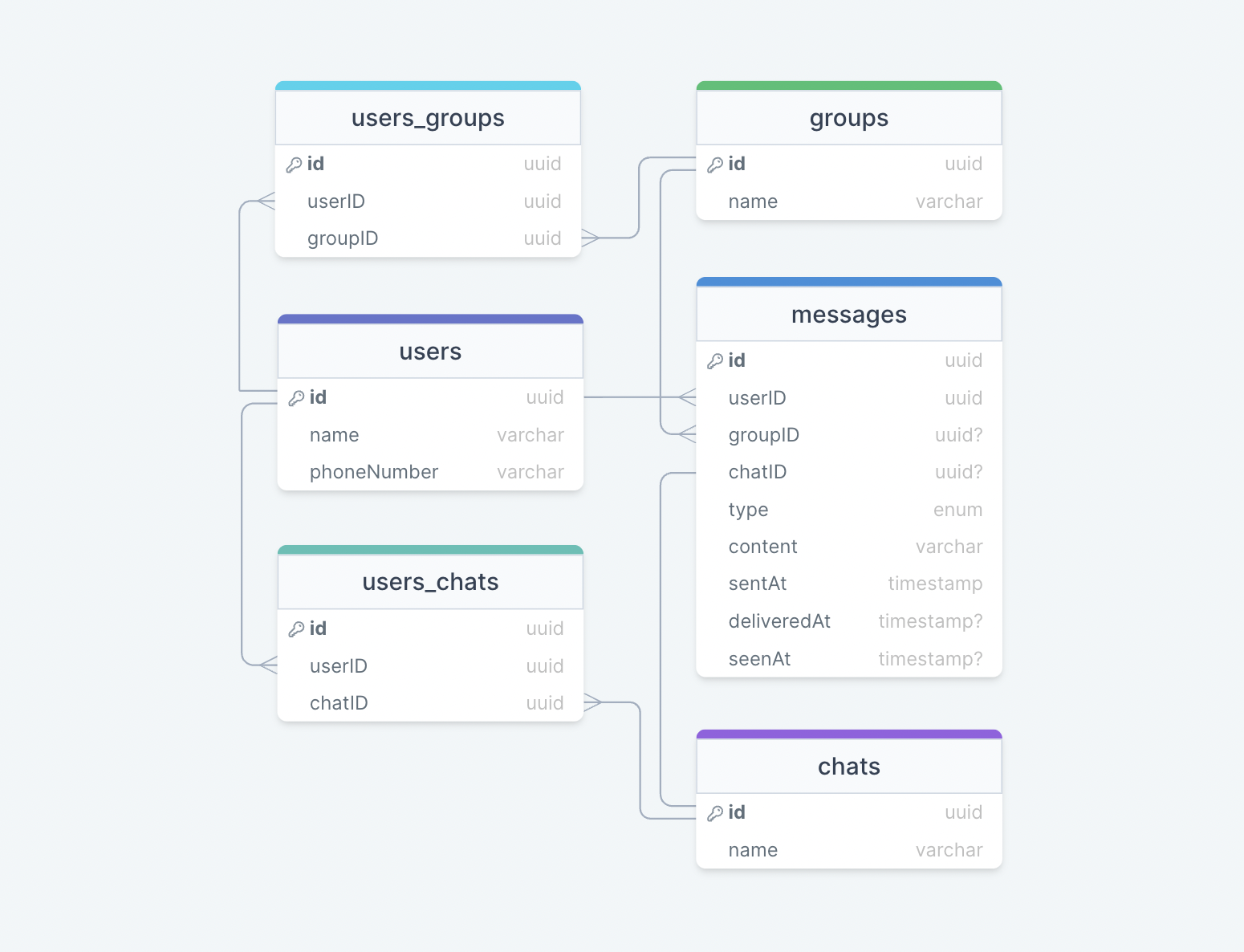
Jest to ogólny model danych, który odzwierciedla nasze wymagania. Mamy następujące tabele: użytkownicy Ta tabela będzie zawierać informacje użytkownika, takie jak nazwa, fonenaber i inne szczegóły. wiadomości Jak sama nazwa wskazuje, ta tabela będzie przechowywać wiadomości z właściwościami takimi jak typ (tekst, obraz, wideo itp.), treść i znaczniki czasu do dostarczania wiadomości. Wiadomość będzie miała również odpowiedni Chatid lub GroupID . rozmowy Ta tabela zasadniczo reprezentuje prywatny czat między dwoma użytkownikami i może zawierać wiele wiadomości. Użytkownicy_chats Ta tabela mapuje użytkowników i czaty, ponieważ wielu użytkowników może mieć wiele czatów (N: M relacje) i odwrotnie. grupy Ta tabela reprezentuje grupę między wieloma użytkownikami. Users_groups Ta tabela mapuje użytkowników i grupy, ponieważ wielu użytkowników może być częścią wielu grup (N: M Relacje) i odwrotnie.
Jakiej bazy danych powinniśmy użyć?
Chociaż nasz model danych wydaje się dość relacyjny, niekoniecznie musimy przechowywać wszystko w jednej bazie danych, ponieważ może to ograniczyć naszą skalowalność i szybko stać się wąskim gardłem. Podzielmy dane między różne usługi posiadające własność w określonej tabeli. Następnie możemy użyć relacyjnej bazy danych, takiej jak PostgreSQL lub rozproszonej bazy danych NoSQL, takiej jak Apache Cassandra dla naszego przypadku użycia.
Projekt API
Wykonajmy podstawowy projekt interfejsu API dla naszych usług:
Zdobądź wszystkie czaty lub grupy
Ten interfejs API otrzyma wszystkie czaty lub grupy dla danego użytkownika .
Getall(identyfikator użytkownika: Uuid): Czat[] [] | Grupa[] [] Wprowadź tryb pełnego ekranu
Wyjdź z trybu pełnego ekranu
Parametry Identyfikator użytkownika (UUID): ID bieżącego użytkownika. Zwroty Wynik (chat [] | grupa []): Wszystkie czaty i grupy użytkownika są częścią.
Uzyskaj wiadomości
Pobierz wszystkie wiadomości dla użytkownika, biorąc pod uwagę kanałd (identyfikator czatu lub grupy).
GetMessages(identyfikator użytkownika: Uuid, ID kanału: Uuid): Wiadomość[] [] Wprowadź tryb pełnego ekranu
Wyjdź z trybu pełnego ekranu
Parametry Identyfikator użytkownika (UUID): ID bieżącego użytkownika. Identyfikator kanału (UUID): Identyfikator kanału (czat lub grupa), z którego wiadomości należy pobrać. Zwroty Wiadomości (wiadomość []): Wszystkie wiadomości na danym czacie lub grupie.
Wyślij wiadomość
Wyślij wiadomość od użytkownika na kanał (czat lub grupa).
Wyślij wiadomość(identyfikator użytkownika: Uuid, ID kanału: Uuid, wiadomość: Wiadomość): Boolean Wprowadź tryb pełnego ekranu
Wyjdź z trybu pełnego ekranu
Parametry Identyfikator użytkownika (UUID): ID bieżącego użytkownika. Identyfikator kanału (UUID): ID użytkownika kanału (czat lub grupa) chce wysłać wiadomość do. Wiadomość (wiadomość): wiadomość (tekst, obraz, wideo itp.) że użytkownik chce wysłać. Zwroty Wynik (boolean): reprezentuje, czy operacja się powiodła, czy nie.
Dołącz lub opuść grupę
Wyślij wiadomość od użytkownika na kanał (czat lub grupa).
dołączyć do grupy(identyfikator użytkownika: Uuid, ID kanału: Uuid): Boolean opuścić grupę(identyfikator użytkownika: Uuid, ID kanału: Uuid): Boolean Wprowadź tryb pełnego ekranu
Wyjdź z trybu pełnego ekranu
Parametry Identyfikator użytkownika (UUID): ID bieżącego użytkownika. Identyfikator kanału (UUID): Identyfikator kanału (czat lub grupa) użytkownik chce dołączyć lub opuścić. Zwroty Wynik (boolean): reprezentuje, czy operacja się powiodła, czy nie.
Projekt wysokiego poziomu
Teraz wykonajmy projekt naszego systemu na wysokim poziomie.
Architektura
Będziemy korzystać z architektury MicroServices, ponieważ ułatwi ona skalowanie w poziomie i oddzielić nasze usługi. Każda usługa będzie miała własność własnego modelu danych. Spróbujmy podzielić nasz system na niektóre podstawowe usługi. Usługa użytkownika Jest to usługa oparta na HTTP, która obsługuje obawy związane z użytkownikiem, takie jak uwierzytelnianie i informacje o użytkowniku. Usługa czatu Usługa czatu będzie korzystać z WebSockets i nawiązuje połączenia z klientem w celu obsługi funkcji czatu i grupy. Możemy również użyć pamięci podręcznej, aby śledzić wszystkie aktywne połączenia podobne do sesji, które pomogą nam ustalić, czy użytkownik jest online, czy nie. Usługa powiadomień Ta usługa po prostu wyśle powiadomienia push do użytkowników. Zostanie szczegółowo omówiony osobno. Usługa obecności Usługa obecności będzie śledzić ostatnio widziany status wszystkich użytkowników. Zostanie szczegółowo omówiony osobno. Usługa medialna Ta usługa będzie obsługiwać media (obrazy, filmy, pliki itp.) przesyłanie. Zostanie szczegółowo omówiony osobno. A co z komunikacją między usługami i odkryciem usług? Ponieważ nasza architektura jest oparta na mikrousługach, usługi również będą się ze sobą komunikować. Ogólnie rzecz biorąc, REST lub HTTP działa dobrze, ale możemy dodatkowo poprawić wydajność za pomocą GRPC, która jest bardziej lekka i wydajna. Odkrycie usług to kolejna rzecz, którą będziemy musieli wziąć pod uwagę. Możemy również skorzystać z siatki serwisowej, która umożliwia zarządzaną, obserwowalną i bezpieczną komunikację między poszczególnymi usługami. Uwaga: Dowiedz się więcej o REST, GHAGHQL, GRPC i tym, jak się ze sobą porównują.
Wiadomości w czasie rzeczywistym
Jak skutecznie wysyłamy i odbieramy wiadomości? Mamy dwie różne opcje: Model Pull Klient może okresowo wysyłać żądanie HTTP do serwerów, aby sprawdzić, czy są jakieś nowe wiadomości. Można to osiągnąć przez coś takiego jak długie ankiety. Model push Klient otwiera długotrwały połączenie z serwerem, a po dostępnych nowych danych zostanie popchnięty do klienta. Możemy do tego używać Websockets lub zdarzeń-serwerów (SSE). Podejście modelu ciągnięcia nie jest skalowalne, ponieważ stworzy niepotrzebne koszty ogólne na naszych serwerach, a przez większość czasu odpowiedź będzie pusta, marnując nasze zasoby. Aby zminimalizować opóźnienie, korzystanie z modelu push z WebSockets jest lepszym wyborem, ponieważ wtedy możemy nacisnąć dane do klienta, gdy będzie ono dostępne bez opóźnienia, biorąc pod uwagę, że połączenie jest otwarte z klientem. Ponadto WebSockets zapewniają komunikację pełną dupleks, w przeciwieństwie do zdarzeń Server-Sent (SSE), które są jedynie jednokierunkowe. Uwaga: Dowiedz się więcej o długich ankietach, WebSockets, zdarzeniach z serwerem (SSE).
Ostatnio widziany
Aby wdrożyć ostatnią funkcjonalność, możemy użyć mechanizmu bicia serca, w którym klient może okresowo pingować serwery wskazujące na jego żywotność. Ponieważ musi to być tak niskie, jak to możliwe, możemy przechowywać ostatni aktywny znacznik czasu w pamięci podręcznej w następujący sposób:
| Klucz | Wartość |
|---|---|
| Użytkownik a | 2022-07-01T14: 32: 50 |
| Użytkownik b | 2022-07-05T05: 10: 35 |
| Użytkownik c | 2022-07-10T04: 33: 25 |
To da nam ostatni raz, gdy użytkownik był aktywny. Ta funkcjonalność będzie obsługiwana przez usługę obecności w połączeniu z redis lub memcached jako nasza pamięć podręczna. Innym sposobem wdrożenia tego jest śledzenie najnowszej akcji użytkownika, gdy ostatnie działanie przekroczy określony próg, taki jak „Użytkownik nie wykonał żadnej akcji w ciągu ostatnich 30 sekund”, Możemy pokazać użytkownik jako offline i ostatnio widzieć z ostatnim nagranym znacznikiem czasu. Będzie to bardziej leniwe podejście do aktualizacji, a w niektórych przypadkach może przynieść korzyści z powodu bicia serca.
Powiadomienia
Po wysłaniu wiadomości na czacie lub grupie najpierw sprawdzimy, czy odbiorca jest aktywny, czy nie, możemy uzyskać te informacje, biorąc pod uwagę aktywne połączenie użytkownika i ostatnio rozważyć. Jeśli odbiorca nie jest aktywny, usługa czatu doda zdarzenie do kolejki wiadomości z dodatkowymi metadanami, takimi jak platforma urządzeń klienta, która zostanie wykorzystana do kierowania powiadomienia do prawidłowej platformy później. Usługa powiadomień zużywa następnie zdarzenie z kolejki wiadomości i przekazuje żądanie do Cloud Messaging FireBase Cloud (FCM) lub usługi powiadomienia Push Apple (APN) w oparciu o platformę urządzeń klienta (Android, iOS, Web itp.). Możemy również dodać obsługę wiadomości e -mail i SMS -ów. Dlaczego używamy kolejki wiadomości? Ponieważ większość kolejki wiadomości zapewnia najlepsze zamówienie, które zapewnia, że wiadomości są ogólnie dostarczane w tej samej kolejności, co wysyłane, i że wiadomość jest dostarczana przynajmniej raz, co jest ważną częścią naszej funkcjonalności serwisowej. Chociaż wydaje się to klasycznym przypadkiem użycia publikacji, nie jest to tak, jak urządzenia mobilne i przeglądarki mają swój własny sposób obsługi powiadomień push. Zwykle powiadomienia są obsługiwane zewnętrznie za pośrednictwem usługi FireBase Cloud Messaging (FCM) lub Apple Push Powiadomienie (APN), w przeciwieństwie do fanowii wiadomości, które powszechnie widzimy w usługach Backend. Możemy użyć czegoś takiego jak Amazon SQS lub Rabbitmq do obsługi tej funkcji.
Przeczytaj wpływy
Obsługa rachunków odczytu może być trudne, w tym przypadku użycia możemy poczekać na jakieś potwierdzenie (ACK) od klienta, aby ustalić, czy wiadomość została dostarczona i zaktualizować odpowiednie pole dostarczające. Podobnie, zaznaczamy wiadomość widoczną, gdy użytkownik otworzy czat i zaktualizujemy odpowiednie pole Septat Timestamp.
Projekt
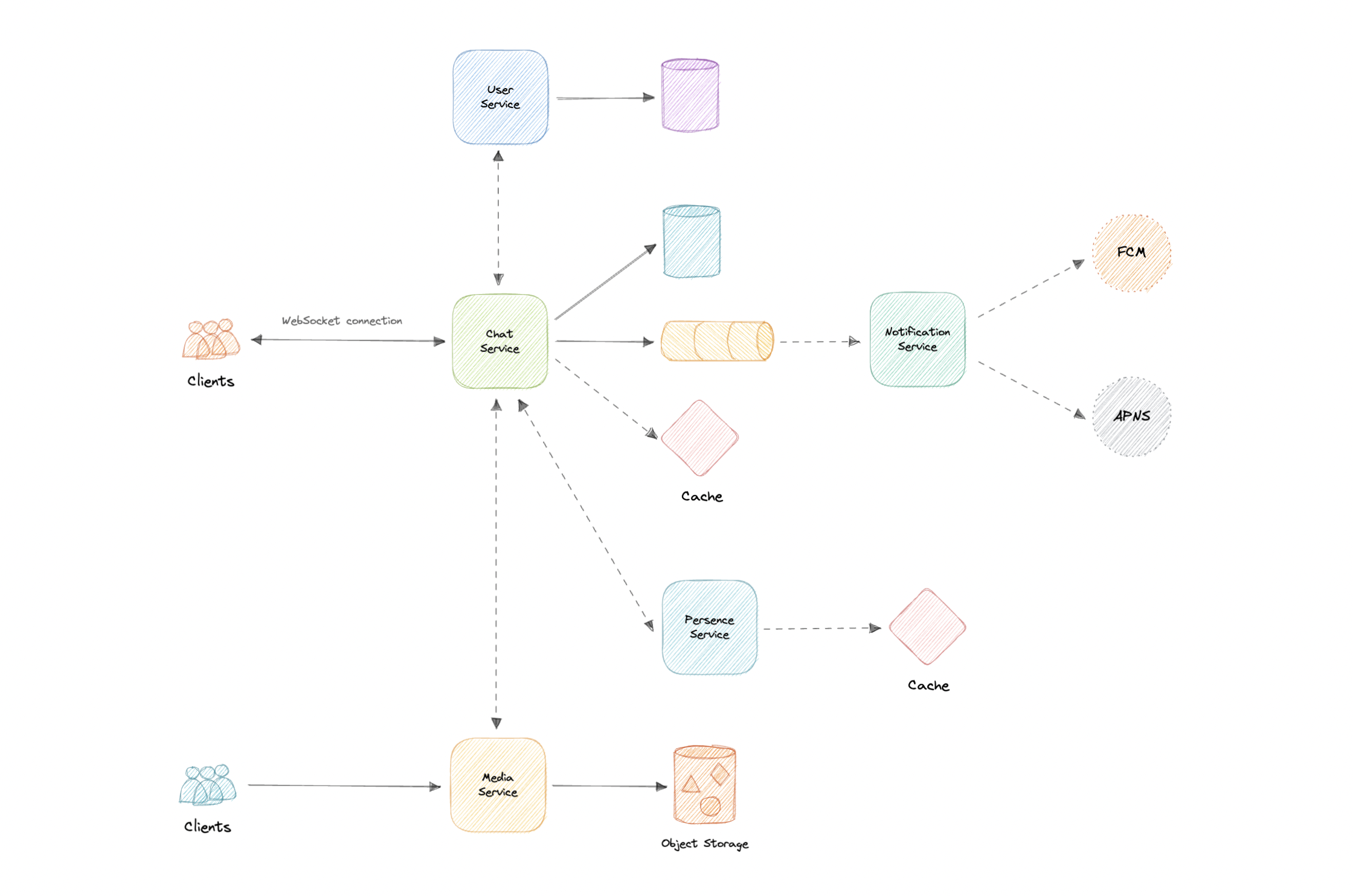
Teraz, gdy zidentyfikowaliśmy niektóre podstawowe komponenty, wykonajmy pierwszy szkic naszego projektu systemu.
Szczegółowy projekt
Czas szczegółowo omówić nasze decyzje projektowe.
Partycjonowanie danych
- Partycjonowanie oparte na HASH
- Partycjonowanie oparte na listach
- Partycjonowanie oparte na zakresie
- Particing złożony
Powyższe podejścia mogą nadal powodować nierówne dane i rozkład obciążenia, możemy rozwiązać to za pomocą spójnego haszu.
Buforowanie
W aplikacji do przesyłania wiadomości musimy uważać na korzystanie z pamięci podręcznej, ponieważ nasi użytkownicy oczekują najnowszych danych, ale wielu użytkowników będzie żądać tych samych wiadomości, szczególnie na czacie grupowym. Aby zapobiec skokom użytkowania z naszych zasobów, możemy buforować starsze wiadomości.
Niektóre czaty grupowe mogą zawierać tysiące wiadomości, a wysyłanie tego przez sieć będzie naprawdę nieefektywne, aby poprawić wydajność, możemy dodać paginację do naszych interfejsów API systemu. Ta decyzja będzie pomocna dla użytkowników o ograniczonej przepustowości sieci, ponieważ nie będą musieli odzyskać starych wiadomości.
Które zasady eksmisji pamięci podręcznej użyć?
Możemy używać rozwiązań takich jak Redis lub Memcached i Cache 20% codziennego ruchu, ale jaka polityka eksmisji pamięci podręcznej najlepiej pasowałaby do naszych potrzeb?
Niedawno używane (LRU) może być dobrą zasadą dla naszego systemu. W tej polityce najpierw najpierw odrzucamy najdroższy Klucz.
Jak poradzić sobie z pamięcią podręczną Miss?
Ilekroć istnieje pamięć podręczna, nasze serwery mogą uderzyć w bazę danych bezpośrednio i zaktualizować pamięć podręczną o nowe wpisy.
Aby uzyskać więcej informacji, patrz buforowanie.
Dostęp do mediów i przechowywanie
Jak wiemy, większość naszej przestrzeni pamięci będzie używana do przechowywania plików multimedialnych, takich jak obrazy, filmy lub inne pliki. Nasza usługa medialna będzie obsługiwać zarówno dostęp, jak i przechowywać pliki multimedialne użytkownika.
Ale gdzie możemy przechowywać pliki na skalę? Cóż, przechowywanie obiektów jest tym, czego szukamy. Obiekt przechowuje przekładanie plików danych na elementy o nazwie obiekty. Następnie przechowuje te obiekty w jednym repozytorium, które można rozłożyć w wielu systemach sieciowych. Możemy również użyć pamięci plików rozproszonych, takich jak HDFS lub Glusterfs.
Zabawny fakt: WhatsApp usuwa media na swoich serwerach po pobraniu przez użytkownika.
Możemy używać sklepów obiektowych, takich jak Amazon S3, Azure Blob Storage lub Google Cloud Storage dla tego przypadku użycia.
Sieć dostarczania treści (CDN)
Sieć dostarczania treści (CDN) zwiększa dostępność treści i redundancję, jednocześnie zmniejszając koszty przepustowości. Zasadniczo pliki statyczne, takie jak obrazy i filmy, są obsługiwane z CDN. Możemy korzystać z usług takich jak Amazon Cloudfront lub Cloudflare CDN dla tego przypadku użycia.
Brama API
Ponieważ będziemy korzystać z wielu protokołów, takich jak HTTP, WebSocket, TCP/IP, wdrażanie wielu L4 (warstwa transportowa) lub L7 (warstwa aplikacji) typu równoważenia obciążenia osobno dla każdego protokołu będzie kosztowne. Zamiast tego możemy użyć bramy API, która obsługuje wiele protokołów bez żadnych problemów.
API Gateway może również oferować inne funkcje, takie jak uwierzytelnianie, autoryzacja, ograniczenie stawek, dławianie i wersja API, które poprawi jakość naszych usług.
Możemy korzystać z usług takich jak Amazon API Gateway lub Azure API Gateway dla tego przypadku użycia.
Zidentyfikuj i rozwiąż wąskie gardła
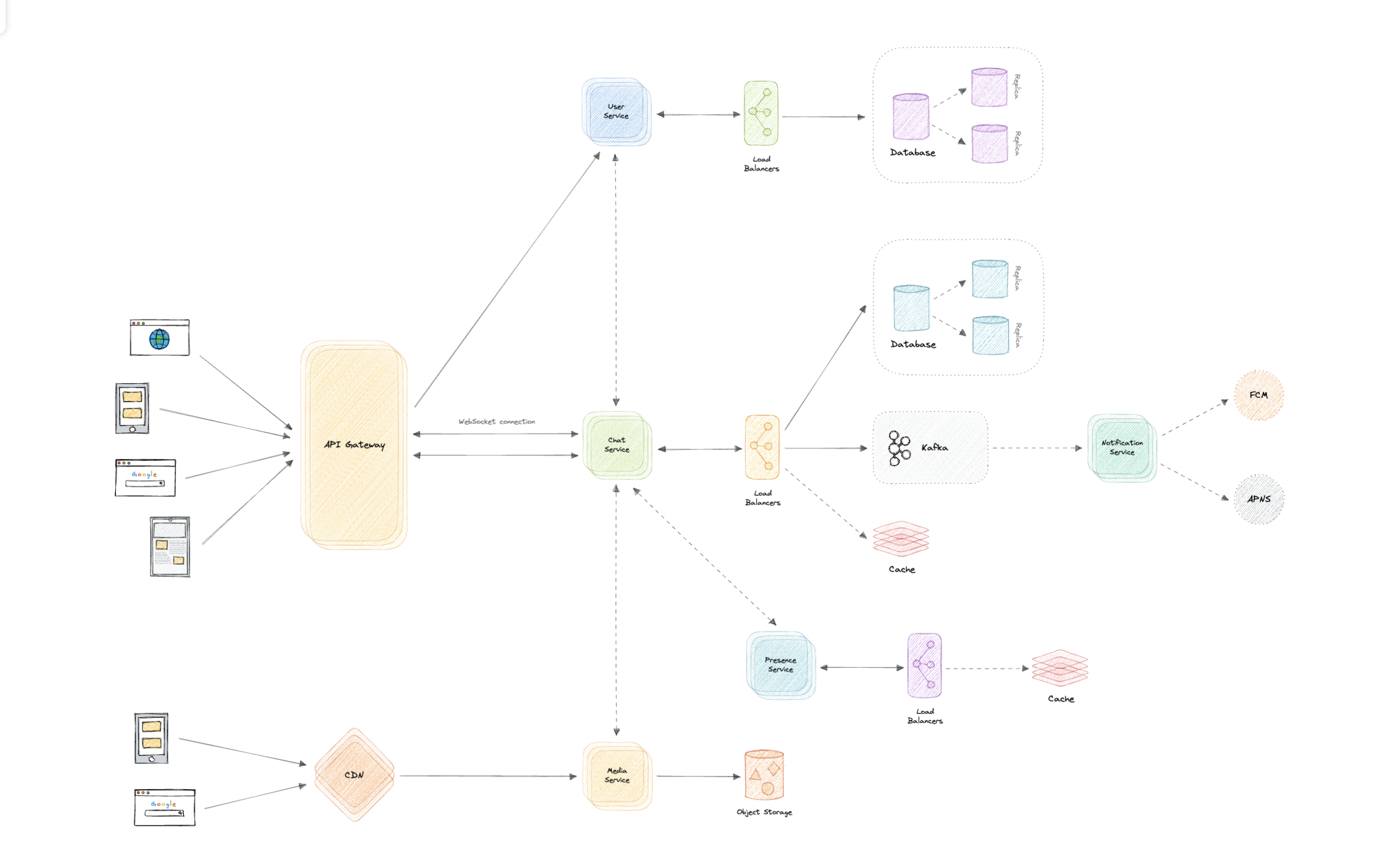
Zidentyfikujmy i rozwiążmy wąskie gardła, takie jak pojedyncze punkty awarii w naszym projekcie:
- „Co się stanie, jeśli jedna z naszych usług zawiedzie?”
- „Jak rozdzielimy nasz ruch między naszymi komponentami?”
- „Jak możemy zmniejszyć obciążenie naszej bazy danych?”
- „Jak poprawić dostępność naszej pamięci podręcznej?”
- „Czy brama API nie byłaby jednym punktem niepowodzenia?”
- „Jak możemy uczynić nasz system powiadomień bardziej solidny?”
- „Jak możemy obniżyć koszty przechowywania mediów”?
- „Czy usługa czatu ma zbyt dużą odpowiedzialność?”
Aby nasz system był bardziej odporny, możemy zrobić:
- Uruchamianie wielu instancji każdej z naszych usług.
- Wprowadzenie równoważenia obciążenia między klientami, serwerami, bazami danych i serwerami pamięci podręcznej.
- Korzystanie z wielu replików odczytu dla naszych baz danych.
- Wiele instancji i replik dla naszej rozproszonej pamięci podręcznej.
- Możemy mieć rezerwową replikę naszej bramy API.
- Dokładnie, gdy dostawa i zamówienie wiadomości będą trudne w systemie rozproszonym, możemy użyć dedykowanego brokera wiadomości, takiego jak Apache Kafka lub NATS, aby nasz system powiadomień był bardziej niezawodny.
- Możemy dodać możliwości przetwarzania multimediów i kompresji do usługi multimedialnej, aby kompresować duże pliki podobne do WhatsApp, które zaoszczędzą dużo miejsca do przechowywania i obniży koszty.
- Możemy utworzyć usługę grupową osobną od usługi czatu, aby dalej oddzielić nasze usługi.
Ten artykuł jest częścią mojego kursu projektowego systemu open source dostępnego na GitHub.
Karanpratapsingh / system systemowy
Dowiedz się, jak projektować systemy na dużą skalę i przygotować się do wywiadów projektowych
Kurs projektowania systemu
Hej, witaj na kursie. Mam nadzieję, że ten kurs stanowi świetne doświadczenie edukacyjne.
Ten kurs jest również dostępny na mojej stronie internetowej i jako ebook na LeanPub. Proszę, zostaw ⭐ jako motywację, jeśli było to pomocne!
Spis treści
- Rozpoczęcie pracy
- Co to jest projektowanie systemu?
- Ip
- Model OSI
- TCP i UDP
- System nazwy domeny (DNS)
- Równoważenie obciążenia
- Grupowanie
- Buforowanie
- Sieć dostarczania treści (CDN)
- Pełnomocnik
- Dostępność
- Skalowalność
- Składowanie
- Bazy danych i DBMS
- Bazy danych SQL
- Bazy danych NOSQL
- Bazy danych SQL vs NoSQL
- Replikacja bazy danych
- Indeksy
- Normalizacja i denormalizacja
- Modele spójności kwasu i podstawy
- Twierdzenie o czapce
- Twierdzenie Pacelc
- Transakcje
- Transakcje rozproszone
- Sharding
- Spójne mieszanie
- Federacja bazy danych
- Architektura poziomu N
- Brokerzy wiadomości
- Kolejki wiadomości
- Publikuj subskrypcję
- Enterprise Service Bus (ESB)
- Monolity i mikrousług
- Architektura oparta na wydarzeniach (EDA)
- Pozyskiwanie zdarzeń
- Segregacja odpowiedzialności za dowództwo i zapytanie (CQRS)
- Brama API
- REST, GraphQL, GRPC
- Długie ankiety, WebSockets, zdarzenia Server-Sent (SSE)

