
Prezentujący Apache Kafka w Netflix Studio i Finance World
Streszczenie:
W Netflix większość aplikacji korzysta z biblioteki klientów Java do tworzenia danych do rurociągu Keystone. Rurociąg polega na frontowaniu klastrów Kafka, odpowiedzialnych za gromadzenie i buforowanie danych, a także klastry konsumenckie Kafka, zawierające tematy dla konsumentów w czasie rzeczywistym. Netflix obsługuje w sumie 36 klastrów Kafka, które codziennie obsługują ponad 700 miliardów wiadomości. Aby osiągnąć bezstronną dostawę, rurociąg umożliwia szybkość utraty danych mniejszą niż 0.01%. Producenci i brokerzy są skonfigurowani tak, aby zapewnić dostępność i dobre wrażenia użytkownika.
Kluczowe punkty:
- Aplikacje Netflix używają biblioteki klientów Java do tworzenia danych do rurociągu Keystone
- W każdej instancji aplikacji istnieje wielu producentów Kafka
- Fronting Kafka Klastry zbiera i buforuj wiadomości
- Klastry konsumenckie Kafka zawierają tematy dla konsumentów w czasie rzeczywistym
- Netflix obsługuje 36 klastrów Kafka z ponad 700 miliardami wiadomości dziennie
- Wskaźnik utraty danych jest mniejszy niż 0.01%
- Producenci i brokerzy są skonfigurowani, aby zapewnić dostępność
- Producenci używają dynamicznej konfiguracji do routingu tematu i izolacji
- Aplikacje inne niż Java mogą wysyłać zdarzenia do punktów końcowych REST w Keystone
- Zamawianie wiadomości jest ustalane w warstwie przetwarzania wsadowego lub routingu
Pytania:
- W jaki sposób aplikacje Netflix tworzą dane do rurociągu Keystone?
- Jakie są role frontowania klastrów kafki?
- Jakie rodzaje klastrów Kafka istnieją w rurociągu Keystone?
- Ile klastrów Kafka działa Netflix?
- Jaki jest średnia wskaźnik przyjmowania danych dla Netflix?
- Jaka jest obecna wersja Kafka używana przez Netflix?
- W jaki sposób Netflix osiąga bezstronną dostawę w rurociągu?
- Jaka jest konfiguracja dla producentów i brokerów, aby zapewnić dostępność?
- Jak utrzymywane są zamawianie wiadomości?
- Dlaczego aplikacje klienckie nie spożywają bezpośrednio z frontowych klastrów Kafka?
- Jakie wyzwania pojawiają się podczas uruchamiania Kafki w chmurze?
- Jak replikacja wpływa na dostępność Kafki?
- Co zrobił Netflix, aby zająć się incydentami i utrzymać stabilność klastra?
- Jaka jest strategia wdrażania Netflix dla klastrów Kafka?
Większość aplikacji Netflix używa biblioteki klientów Java do tworzenia danych do rurociągu Keystone. Każda instancja aplikacji ma wielu producentów Kafka.
Fronting Kafka Klastery zbiera i buforują wiadomości od producentów. Służą jako brama do iniekcji wiadomości.
Kluczowy rurociąg składa się z frontowania klastrów Kafki i klastrów konsumenckich Kafka.
Netflix obsługuje 36 klastrów Kafka.
Netflix codziennie spożywa ponad 700 miliardów wiadomości.
Netflix przechodzi z Kafka wersja 0.8.2.1 do 0.9.0.1.
Rozliczając ogromny wolumen danych, Netflix współpracował z zespołami, aby zaakceptować akceptowalną liczbę utraty danych, co skutkuje dzienną szybkością utraty danych wynoszącą mniej niż 0.01%.
Producenci i brokerzy są skonfigurowani z blokiem „ACKS = 1”, ”.NA.bufor.Full = False ”i„ Unclean.lider.wybór.enable = true “.
Producenci nie używają kluczowych komunikatów, a zamawianie wiadomości jest przywracane w warstwie przetwarzania wsadowego lub warstwie routingu.
Aplikacje klientów nie mogą bezpośrednio konsumować z frontowania klastrów Kafka, aby zapewnić przewidywalne obciążenie i stabilność.
Uruchomienie Kafki w chmurze stanowi wyzwania, takie jak nieprzewidywalna instancja cyklu życia, przejściowe problemy z nawiązywaniem kontaktów i wartości odstające powodujące problemy z wydajnością.
Replikacja poprawia dostępność, ale broker odstający może powodować efekty kaskadowe i spadek wiadomości z powodu opóźnienia replikacji i wyczerpania bufora.
Netflix zmniejszył państwowość i złożoność, wdrożył wykrywanie wartości odstających i opracował środki w celu szybkiego odzyskania po incydentach.
Netflix sprzyja wielu małym klastrom kafki nad jednym gigantycznym klastrem, aby zmniejszyć zależności i poprawić stabilność.
Kafka w rurociągu Keystone
Mamy dwa zestawy klastrów Kafka w rurociągu Keystone: Fronting Kafka i konsumenckie Kafka. Fronting Kafka Klastry są odpowiedzialne za otrzymanie wiadomości od producentów, które są praktycznie każdą instancją aplikacji w Netflix. Ich role to gromadzenie danych i buforowanie systemów niższych. Klastry konsumenckie Kafka zawierają podzbiór tematów kierowanych przez Samza dla konsumentów w czasie rzeczywistym.
Obecnie obsługujemy 36 klastrów Kafka składających się z ponad 4000 instancji brokera zarówno dla Kafki, jak i Kafka konsumenckiego. Ponad 700 miliardów wiadomości jest spożywanych średnio w ciągu dnia. Obecnie przechodzimy z Kafka wersja 0.8.2.1 do 0.9.0.1.
Zasady projektowania
Biorąc pod uwagę obecną architekturę Kafka i nasz ogromny wolumen danych, aby osiągnąć bezstronną dostawę dla naszego rurociągu danych, jest kosztowy w AWS EC2. Rozliczanie tego, my’Współpracował z zespołami, które zależą od naszej infrastruktury, aby osiągnąć akceptowalną liczbę utraty danych, a koszty równoważenia. My’Osiągnięto dzienny wskaźnik utraty danych wynoszący mniej niż 0.01%. Wskaźniki są gromadzone dla upuszczonych wiadomości, abyśmy mogli podjąć działania w razie potrzeby.
Rurociąg Keystone produkuje komunikaty asynchroniczne bez blokowania aplikacji. W przypadku, gdy nie można dostarczyć wiadomości po próbach, zostanie zrzucony przez producent, aby zapewnić dostępność aplikacji i dobre wrażenia użytkownika. Właśnie dlatego wybraliśmy następującą konfigurację dla naszego producenta i brokera:
- ACK = 1
- blok.NA.bufor.Full = False
- nieczysty.lider.wybór.enable = true
Większość aplikacji w Netflix używa naszej biblioteki klientów Java do produkcji do rurociągu Keystone. W każdym przypadku tych aplikacji istnieje wielu producentów Kafka, przy czym każdy produkuje na frontowym klastrze Kafka do izolacji poziomu zlewu. Producenci mają elastyczną konfigurację tematu i konfigurację zlewu, które są kierowane przez konfigurację dynamiczną, którą można zmienić w czasie wykonywania bez konieczności ponownego ponownego uruchomienia procesu aplikacji. To umożliwia rzeczy takie jak przekierowanie ruchu i migracja tematów w klastrach Kafka. W przypadku aplikacji innych niż Java mogą wysyłać zdarzenia do punktów końcowych REST w Keystone, które przekazują wiadomości do frontowania klastrów Kafka.
W przypadku większej elastyczności producenci nie używają kluczowych wiadomości. Przybliżone zamawianie wiadomości zostaje przywrócone w warstwie przetwarzania wsadowego (Hive / ElasticSearch) lub warstwie routingu dla streamingowych konsumentów.
Stanowimy stabilność naszych klastrów Kafki z wysokim priorytetem, ponieważ są one bramą do wstrzyknięcia wiadomości. Dlatego nie zezwalamy na bezpośrednie z nich aplikacje klientów, aby upewnić się, że mają przewidywalne obciążenie.
Wyzwania związane z prowadzeniem Kafki w chmurze
Kafka została opracowana z centrum danych jako cel wdrażania w LinkedIn. Podjęliśmy godne uwagi wysiłki, aby Kafka działała lepiej w chmurze.
W chmurze instancje mają nieprzewidywalny cykl życia i mogą zostać zakończone w dowolnym momencie z powodu problemów ze sprzętem. Oczekiwane są przejściowe problemy związane z nawiązywaniem kontaktów. Nie są to problemy dla usług bezstanowych, ale stanowią duże wyzwanie dla służby stanowej wymagającej Zookeeper i pojedynczego kontrolera do koordynacji.
Większość naszych problemów zaczyna się od brokerów odstających. Wartość odstająca może być spowodowana nierównomiernym obciążeniem, problemami ze sprzętem lub jego konkretnym środowiskiem, na przykład hałaśliwi sąsiedzi z powodu wielozadaniowości. Broker odstający może mieć powolne odpowiedzi na żądania lub częste limity czasu/retransmisji TCP. Producenci, którzy wysyłają wydarzenia do takiego brokera, będą mieli szansę wyczerpać lokalne bufory, czekając na odpowiedzi, po których upuszczenie wiadomości staje się pewnością. Innym czynnikiem przyczyniającym się do wyczerpania buforowania jest to, że Kafka 0.8.2 producent nie’t Obsługa limitu czasu na bufor w buforze.
Kafka’replikacja S poprawia dostępność. Jednak replikacja prowadzi do wzajemnych zależności wśród brokerów, w których wartość odstająca może powodować efekt kaskadowy. Jeśli wartość odstająca zwalnie replikację, opóźnienie replikacji może się zbudować i ostatecznie spowodować, że liderzy partycji odczytają z dysku, aby służyli żądaniom replikacji. To spowalnia dotkniętych brokerów i ostatecznie powoduje, że producenci upuszczają wiadomości z powodu wyczerpanego bufora, jak wyjaśniono w poprzednim przypadku.
W naszych wczesnych dniach obsługi Kafki doświadczyliśmy incydentu, w którym producenci porzucali znaczną liczbę wiadomości do klastra Kafka z setkami instancji z powodu problemu Zookeepera, podczas gdy niewiele mogliśmy zrobić. Takie problemy debugowania w małym oknie czasowym z setkami brokerów po prostu nie jest realistyczne.
Po tym incydencie podjęto wysiłki w celu zmniejszenia państwa i złożoności naszych klastrów Kafka, wykrywania wartości odstających i znalezienia sposobu na szybki rozpoczęcie od czystego stanu, gdy nastąpi incydent.
Strategia wdrażania Kafka
Poniżej znajdują się kluczowe strategie, których użyliśmy do wdrażania klastrów Kafka:
- Faworyzuj wiele małych klastrów Kafki, w przeciwieństwie do jednego gigantycznego klastra. To zmniejsza zależność i poprawia stabilność.
- Wdrożyć mechanizmy wykrywania wartości odstających w celu identyfikacji i obsługi problematycznych brokerów.
- Opracuj środki, aby szybko odzyskać się po incydentach i rozpocząć od czystego stanu.
Prezentujący Apache Kafka w Netflix Studio i Finance World
Większość aplikacji w Netflix używa naszej biblioteki klientów Java do produkcji do rurociągu Keystone. W każdym przypadku tych aplikacji istnieje wielu producentów Kafka, przy czym każdy produkuje na frontowym klastrze Kafka do izolacji poziomu zlewu. Producenci mają elastyczną konfigurację tematu i konfigurację zlewu, które są kierowane przez konfigurację dynamiczną, którą można zmienić w czasie wykonywania bez konieczności ponownego ponownego uruchomienia procesu aplikacji. To umożliwia rzeczy takie jak przekierowanie ruchu i migracja tematów w klastrach Kafka. W przypadku aplikacji innych niż Java mogą wysyłać zdarzenia do punktów końcowych REST w Keystone, które przekazują wiadomości do frontowania klastrów Kafka.
Kafka w rurociągu Keystone
Mamy dwa zestawy klastrów Kafka w rurociągu Keystone: Fronting Kafka i konsumenckie Kafka. Fronting Kafka Klastry są odpowiedzialne za otrzymanie wiadomości od producentów, które są praktycznie każdą instancją aplikacji w Netflix. Ich role to gromadzenie danych i buforowanie systemów niższych. Klastry konsumenckie Kafka zawierają podzbiór tematów kierowanych przez Samza dla konsumentów w czasie rzeczywistym.
Obecnie obsługujemy 36 klastrów Kafka składających się z ponad 4000 instancji brokera zarówno dla Kafki, jak i Kafka konsumenckiego. Ponad 700 miliardów wiadomości jest spożywanych średnio w ciągu dnia. Obecnie przechodzimy z Kafka wersja 0.8.2.1 do 0.9.0.1.
Zasady projektowania
Biorąc pod uwagę obecną architekturę Kafka i nasz ogromny wolumen danych, aby osiągnąć bezstronną dostawę dla naszego rurociągu danych, jest kosztowy w AWS EC2. Rozliczanie tego, my’Współpracował z zespołami, które zależą od naszej infrastruktury, aby osiągnąć akceptowalną liczbę utraty danych, a koszty równoważenia. My’Osiągnięto dzienny wskaźnik utraty danych wynoszący mniej niż 0.01%. Wskaźniki są gromadzone dla upuszczonych wiadomości, abyśmy mogli podjąć działania w razie potrzeby.
Rurociąg Keystone produkuje komunikaty asynchroniczne bez blokowania aplikacji. W przypadku, gdy nie można dostarczyć wiadomości po próbach, zostanie zrzucony przez producent, aby zapewnić dostępność aplikacji i dobre wrażenia użytkownika. Właśnie dlatego wybraliśmy następującą konfigurację dla naszego producenta i brokera:
- ACK = 1
- blok.NA.bufor.Full = False
- nieczysty.lider.wybór.enable = true
Większość aplikacji w Netflix używa naszej biblioteki klientów Java do produkcji do rurociągu Keystone. W każdym przypadku tych aplikacji istnieje wielu producentów Kafka, przy czym każdy produkuje na frontowym klastrze Kafka do izolacji poziomu zlewu. Producenci mają elastyczną konfigurację tematu i konfigurację zlewu, które są kierowane przez konfigurację dynamiczną, którą można zmienić w czasie wykonywania bez konieczności ponownego ponownego uruchomienia procesu aplikacji. To umożliwia rzeczy takie jak przekierowanie ruchu i migracja tematów w klastrach Kafka. W przypadku aplikacji innych niż Java mogą wysyłać zdarzenia do punktów końcowych REST w Keystone, które przekazują wiadomości do frontowania klastrów Kafka.
W przypadku większej elastyczności producenci nie używają kluczowych wiadomości. Przybliżone zamawianie wiadomości zostaje przywrócone w warstwie przetwarzania wsadowego (Hive / ElasticSearch) lub warstwie routingu dla streamingowych konsumentów.
Stanowimy stabilność naszych klastrów Kafki z wysokim priorytetem, ponieważ są one bramą do wstrzyknięcia wiadomości. Dlatego nie zezwalamy na bezpośrednie z nich aplikacje klientów, aby upewnić się, że mają przewidywalne obciążenie.
Wyzwania związane z prowadzeniem Kafki w chmurze
Kafka została opracowana z centrum danych jako cel wdrażania w LinkedIn. Podjęliśmy godne uwagi wysiłki, aby Kafka działała lepiej w chmurze.
W chmurze instancje mają nieprzewidywalny cykl życia i mogą zostać zakończone w dowolnym momencie z powodu problemów ze sprzętem. Oczekiwane są przejściowe problemy związane z nawiązywaniem kontaktów. Nie są to problemy dla usług bezstanowych, ale stanowią duże wyzwanie dla służby stanowej wymagającej Zookeeper i pojedynczego kontrolera do koordynacji.
Większość naszych problemów zaczyna się od brokerów odstających. Wartość odstająca może być spowodowana nierównomiernym obciążeniem, problemami ze sprzętem lub jego konkretnym środowiskiem, na przykład hałaśliwi sąsiedzi z powodu wielozadaniowości. Broker odstający może mieć powolne odpowiedzi na żądania lub częste limity czasu/retransmisji TCP. Producenci, którzy wysyłają wydarzenia do takiego brokera, będą mieli szansę wyczerpać lokalne bufory, czekając na odpowiedzi, po których upuszczenie wiadomości staje się pewnością. Innym czynnikiem przyczyniającym się do wyczerpania buforowania jest to, że Kafka 0.8.2 producent nie’t Obsługa limitu czasu na bufor w buforze.
Kafka’replikacja S poprawia dostępność. Jednak replikacja prowadzi do wzajemnych zależności wśród brokerów, w których wartość odstająca może powodować efekt kaskadowy. Jeśli wartość odstająca zwalnie replikację, opóźnienie replikacji może się zbudować i ostatecznie spowodować, że liderzy partycji odczytają z dysku, aby służyli żądaniom replikacji. To spowalnia dotkniętych brokerów i ostatecznie powoduje, że producenci upuszczają wiadomości z powodu wyczerpanego bufora, jak wyjaśniono w poprzednim przypadku.
W naszych wczesnych dniach obsługi Kafki doświadczyliśmy incydentu, w którym producenci porzucali znaczną liczbę wiadomości do klastra Kafka z setkami instancji z powodu problemu Zookeepera, podczas gdy niewiele mogliśmy zrobić. Takie problemy debugowania w małym oknie czasowym z setkami brokerów po prostu nie jest realistyczne.
Po tym incydencie podjęto wysiłki w celu zmniejszenia państwa i złożoności naszych klastrów Kafka, wykrywania wartości odstających i znalezienia sposobu na szybki rozpoczęcie od czystego stanu, gdy nastąpi incydent.
Strategia wdrażania Kafka
Poniżej znajdują się kluczowe strategie, których użyliśmy do wdrażania klastrów Kafka
- Faworyzuj wiele małych klastrów Kafki, w przeciwieństwie do jednego gigantycznego klastra. To zmniejsza złożoność operacyjną dla każdego klastra. Nasz największy klaster ma mniej niż 200 brokerów.
- Ogranicz liczbę partycji w każdym klastrze. Każda klaster ma mniej niż 10 000 partycji. Poprawia to dostępność i zmniejsza opóźnienie żądań/odpowiedzi związanych z liczbą partycji.
- Dąży do równego dystrybucji replik dla każdego tematu. Nawet obciążenie pracą jest łatwiejsze do planowania zdolności i wykrywania wartości odstających.
- Użyj dedykowanego klastra Zookeeper dla każdego klastra Kafka, aby zmniejszyć wpływ problemów Zookeeper.
Poniższa tabela pokazuje nasze konfiguracje wdrażania.
Kafka awaryjna
Zautomatyzowaliśmy proces, w którym możemy przełączyć się zarówno producentowi, jak i konsumentowi (router) do nowego klastra Kafka, gdy główny klaster ma kłopoty. Dla każdego klastra Kafka znajduje się zimny klaster gotowości z pożądaną konfiguracją uruchomienia, ale minimalną pojemność początkową. Aby zagwarantować czysty stan na początek, klaster awaryjny nie ma żadnych tematów i nie udostępnia klastra Zookeeper z głównym klastrem Kafka. Klaster przełączania awaryjnego jest również zaprojektowany w taki sposób, aby mieć współczynnik replikacji 1, aby był wolny od wszelkich problemów z replikacją, które może mieć oryginalny klaster.
Kiedy nastąpi awaria awaryjna, podejmowane są następujące kroki w celu przekierowania ruchu producenta i konsumentów:
- Zmień rozmiar klastra awaryjnego do pożądanego rozmiaru.
- Utwórz tematy i uruchom zadania routingu dla klastra przełączania awaryjnego równolegle.
- (Opcjonalnie) Poczekaj, aż liderowie partycji zostaną ustanowione przez kontroler, aby zminimalizować początkowy spadek wiadomości podczas produkcji.
- Dynamicznie zmień konfigurację producenta, aby przełączyć ruch producenta na klaster awaryjny.
Scenariusz przełączania awaryjnego można przedstawić następującym wykresem:
Dzięki całkowitej automatyzacji procesu możemy wykonać przełączanie awaryjne w mniej niż 5 minut. Po pomyślnym zakończeniu awaryjnego możemy debugować problemy z oryginalnym klastrem za pomocą dzienników i wskaźników. Możliwe jest również całkowite zniszczenie klastra i odbudowanie z nowymi obrazami, zanim zrezygnujemy z ruchu. W rzeczywistości często wykorzystujemy strategię przełączania awaryjnego do kierowania ruchu podczas wykonywania konserwacji offline. W ten sposób aktualizujemy nasze klastry Kafka do nowej wersji Kafka bez konieczności realizacji lub ustawiania wersji protokołu komunikacji między.
Rozwój Kafki
Opracowaliśmy całkiem sporo przydatnych narzędzi dla Kafki. Oto niektóre z najważniejszych atrakcji:
Producent Sticky Partitioner
Jest to specjalny spersonalizowany partycjoner, który opracowaliśmy dla naszej biblioteki producentów Java. Jak sama nazwa wskazuje, trzyma się pewnej partycji do produkcji przez konfigurowalną ilość czasu przed losowym wyborem następnej partycji. Stwierdziliśmy, że użycie Sticky partycjoner wraz z długotrwałym pomaga poprawić partię wiadomości i zmniejszyć obciążenie brokera. Oto tabela pokazująca efekt lepkiego partytury:
Rack świadome przypisanie repliki
Wszystkie nasze klastry Kafka obejmują trzy strefy dostępności AWS. Strefa dostępności AWS to koncepcyjnie stojak. Aby zapewnić dostępność w przypadku spadku jednej strefy, opracowaliśmy przypisanie repliki stojaka (strefy), aby repliki dla tego samego tematu zostały przypisane do różnych stref. Pomaga to nie tylko zmniejszyć ryzyko awarii strefy, ale także poprawia naszą dostępność, gdy wielu brokerów zlokalizowanych w tym samym hoście fizycznym jest zakończonych z powodu problemów z gospodarzem. W tym przypadku mamy lepszą tolerancję na winy niż Kafka’s n – 1 gdzie n jest współczynnikiem replikacji.
Prace są przyczyniane do społeczności Kafka w KIP-36 i Apache Kafka Github Request #132.
Wizualizator metadanych Kafka
Kafka’S Metadata jest przechowywana w Zookeeper. Jednak widok drzewa dostarczony przez wystawcę jest trudny w nawigacji i jest czasochłonne znalezienie i skorelowanie informacji.
Stworzyliśmy własny interfejs użytkownika do wizualizacji metadanych. Zapewnia zarówno wykres, jak i widoki tabelaryczne i wykorzystuje bogate schematy kolorów, aby wskazać stan ISR. Kluczowe funkcje są następujące:
- Indywidualna karta dla widoków dla brokerów, tematów i klastrów
- Większość informacji można sortować i można przeszukiwać
- Wyszukiwanie tematów w różnych klastrach
- Bezpośrednie mapowanie z identyfikatora brokera na ID instancji AWS
- Korelacja brokerów przez relację lidera
Poniżej przedstawiono zrzuty ekranu interfejsu użytkownika:
Monitorowanie
Stworzyliśmy dedykowaną usługę monitorowania dla Kafki. Jest odpowiedzialny za śledzenie:
- Status brokera (w szczególności, jeśli jest offline od Zookeeper)
- Pośrednik’S Możliwość odbierania wiadomości od producentów i dostarczania wiadomości do konsumentów. Usługa monitorowania działa zarówno jako producent, jak i konsument pod kątem ciągłych komunikatów bicia serca i mierzy opóźnienie tych wiadomości.
- W przypadku starych konsumentów opartych na Zookeeper monitoruje liczbę partycji dla grupy konsumenckiej, aby upewnić się, że każda partycja jest konsumowana.
- W przypadku routerów Keystone Samza monitoruje przesunięcia kontrolne i porównuje z brokerem’S -rejestrowanie Sonek, aby upewnić się, że nie utkną i nie mają znaczącego opóźnienia.
Ponadto mamy obszerne pulpity nawigacyjne, aby monitorować ruch ruch’S metryki.
Plan na przyszłość
Obecnie migrujemy do Kafka 0.9, który ma sporo funkcji, których chcemy użyć, w tym nowe interfejsy konsumenckie, limit czasu wiadomości producentów i kwoty. Przeniesiemy również nasze klastry Kafka do AWS VPC i wierzymy, że jego ulepszona sieci (w porównaniu z klasykiem EC2) zapewni nam przewagę w celu poprawy dostępności i wykorzystania zasobów.
Zamierzamy przedstawić wielopoziomową SLA na tematy. W przypadku tematów, które mogą zaakceptować niewielką stratę, rozważamy użycie jednej repliki. Bez replikacji nie tylko oszczędzamy ogromną przepustowość, ale także minimalizujemy zmiany stanu, które muszą polegać na kontrolerze. To kolejny krok, aby Kafka była mniejsza w środowisku, które faworyzuje usługi bezpaństwowe. Minusem jest potencjalna utrata wiadomości, gdy broker odchodzi. Jednak wykorzystując limit czasu wiadomości producenta w 0.9 Wydanie i ewentualnie objętość AWS EBS, możemy złagodzić stratę.
Bądź na bieżąco z przyszłymi blogami Keystone na naszej infrastrukturze routingu, zarządzaniu kontenerami, przetwarzaniu strumieni i innych!
Prezentujący Apache Kafka w Netflix Studio i Finance World
Netflix wydał około 15 miliardów dolarów na tworzenie światowej klasy oryginalnej treści w 2019 roku. Gdy stawki są tak wysokie, najważniejsze jest włączenie naszej działalności w krytycznych spostrzeżeniach, które pomagają planować, określić wydatki i rozliczać wszystkie treści Netflix. Te spostrzeżenia mogą obejmować:
- Ile powinniśmy wydać w następnym roku na międzynarodowe filmy i serie?
- Czy poprawiamy, aby przekroczyć nasz budżet produkcyjny i czy każdy musi wkroczyć, aby utrzymać sytuację?
- Jak programujemy katalog z wieloletnim wyprzedzeniem z danymi, intuicją i analizami, aby pomóc w stworzeniu najlepszego możliwego tablicy?
- Jak produkujemy finansowe treści na całym świecie i zgłaszamy się do Wall Street?
Podobnie jak VCS rygorystycznie dostrajają swoje oko do dobrych inwestycji, zespół inżynierii finansów treści’Karty jest pomaganiem Netflix w inwestowaniu, śledzeniu i uczeniu się z naszych działań, abyśmy stale dokonywali lepszych inwestycji w przyszłości.
Envace Eventing
Z punktu widzenia inżynierii każda aplikacja finansowa jest modelowana i wdrażana jako mikrousług. Netflix obejmuje rozproszone zarządzanie i zachęca do podejścia opartego na mikrousługach do aplikacji, co pomaga osiągnąć właściwą równowagę między abstrakcją danych a prędkością w miarę skalowania firmy. W prostym świecie usługi mogą oddziaływać za pośrednictwem HTTP w porządku, ale w miarę skalowania ewoluują w złożony wykres synchronicznych, opartych na żądaniach interakcji, które mogą potencjalnie prowadzić do podzielonego mózgu/stanu i zakłócać dostępność dostępności.
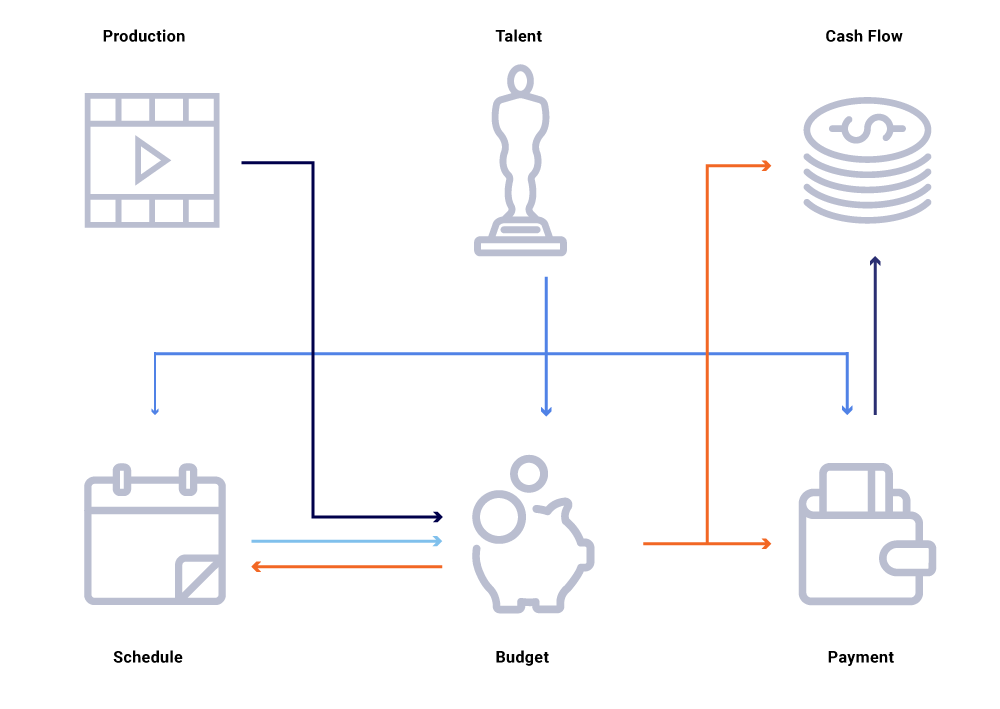
Rozważ na powyższym wykresie powiązanych podmiotów, zmiana daty produkcji programu. Wpływa to na naszą listę programowania, która z kolei wpływa na projekty przepływów pieniężnych, płatności talentów, budżety na rok, itp. Często w architekturze mikrousług, pewien odsetek awarii jest dopuszczalny. Jednak awaria dowolnego z wezwań mikrousług dla inżynierii finansowania treści doprowadziłaby do tego, że mnóstwo obliczeń nie jest zsynchronizowane i może spowodować wyłączenie danych o miliony dolarów. Prowadziłoby to również do problemów z dostępnością, ponieważ wykres połączeń się pojawia i powoduje ślepe miejsca, jednocześnie próbując skutecznie wyśledzić i odpowiadać na pytania biznesowe, takie jak: Dlaczego prognozy przepływów pieniężnych odbiegają od naszego harmonogramu uruchomienia? Dlaczego prognoza dla bieżącego roku nie uwzględnia programów, które są aktywne? Kiedy możemy oczekiwać, że nasze raporty o kosztach dokładnie odzwierciedlają zmiany w górę?
Przemyślenie interakcji usług jako strumienia wymiany zdarzeń – w przeciwieństwie do sekwencji synchronicznych żądań – ulega nam budowania infrastruktury, która jest z natury asynchroniczna. Promuje odsprzęganie i zapewnia identyfikowalność jako obywatel pierwszej klasy w sieci transakcji rozproszonych. Wydarzenia to znacznie więcej niż wyzwalacze i aktualizacje. Stają się niezmiennym strumieniem, z którego możemy zrekonstruować cały stan systemu.
Przejście w kierunku modelu publikacji/subskrypcji umożliwia każdemu usłudze opublikowanie jego zmian jako wydarzenia w magistrali dyskusyjnej, które następnie mogą być zużyte przez inną interesującą usługę, która musi dostosować swój stan świata. Taki model pozwala nam śledzić, czy usługi są zsynchronizowane w odniesieniu do zmian stanu, a jeśli nie, jak długo, zanim będą mogły być zsynchronizowane. Te spostrzeżenia są niezwykle potężne podczas obsługi dużego wykresu usług zależnych. Komunikacja oparta na zdarzeniach i zdecentralizowana konsumpcja pomaga nam przezwyciężyć problemy, które zwykle widzimy na dużych synchronicznych wykresach połączeń (jak wspomniano powyżej).
Netflix obejmuje Apache Kafka ® jako standard de-facto dla swoich potrzeb zdarzenia, przesyłania wiadomości i przetwarzania strumienia. Kafka działa jak most dla wszystkich punktów punktowych i Netflix Studio Wide Communications. Zapewnia nam wysoką trwałość i liniowo skalowalną, wielozadaniową architekturę wymaganą dla systemów operacyjnych w Netflix. Nasza wewnętrzna Kafka jako oferta serwisowa zapewnia tolerancję błędów, obserwowalność, wdrożenia wielofunkcyjne i samoobsługę. Ułatwia to całkowitemu ekosystemowi mikrousystemu łatwiejsze tworzenie i spożywanie znaczących zdarzeń oraz uwolnienie siły komunikacji asynchronicznej.
Typowa wymiana wiadomości w ekosystemie Netflix Studio wygląda tak:
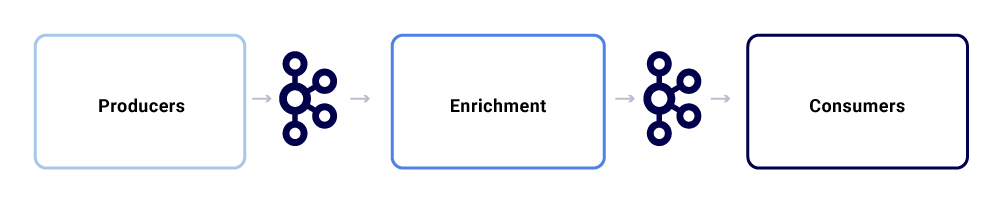
Możemy je rozbić jako trzy główne podgajniki.
Producenci
Producent może być dowolnym systemem, który chce opublikować cały stan lub wskazówka, że krytyczny element jego stanu wewnętrznego zmienił się dla konkretnego podmiotu. Oprócz ładunku zdarzenie musi przestrzegać znormalizowanego formatu, co ułatwia śledzenie i zrozumienie. Ten format obejmuje:
- UUID: Uniwersalny identyfikator
- Typ: Jeden z typów tworzenia, czytania, aktualizacji lub usuwania (crud)
- TS: Znacznik czasu wydarzenia
Zmień narzędzia do przechwytywania danych (CDC) to kolejna kategoria producentów zdarzeń, którzy wyprowadzają zdarzenia ze zmian w bazie danych. Może to być przydatne, gdy chcesz udostępnić zmiany bazy danych wielu konsumentom. Używamy również tego wzorca do replikacji tych samych danych między centrami danych (dla pojedynczych podstawowych baz danych). Przykładem jest to, że mamy dane w MySQL, które należy indeksować w ElasticSearch lub Apache Solr ™. Zaletą korzystania z CDC jest to, że nie nakłada on dodatkowego obciążenia na aplikację źródłową.
W przypadku zdarzeń CDC pole typu w formacie zdarzenia ułatwia dostosowanie i przekształcenie zdarzeń zgodnie z wymaganiami odpowiednich zlewów.
Wzbogacacie
Gdy dane istnieją w Kafka, można zastosować do nich różne wzorce zużycia. Zdarzenia są wykorzystywane na wiele sposobów, w tym jako wyzwalacze obliczeń systemowych, przesyłanie ładunku w celu komunikacji w czasie w czasie rzeczywistym oraz wskazówki w celu wzbogacenia i zmaterializowania widoków danych w pamięci.
Wzbogacanie danych staje się coraz bardziej powszechne, gdy mikrousługi potrzebują pełnego widoku zestawu danych, ale część danych pochodzi z innej usługi’S Zestaw danych. Połączony zestaw danych może być przydatny do poprawy wydajności zapytań lub w zapewnieniu widoku zagregowanych danych w czasie rzeczywistym. Aby wzbogacić dane dotyczące zdarzeń, konsumenci odczytają dane z Kafka i wywołać inne usługi (przy użyciu metod obejmujących GRPC i GraphQL) w celu zbudowania połączonego zestawu danych, które są później podawane do innych tematów Kafka.
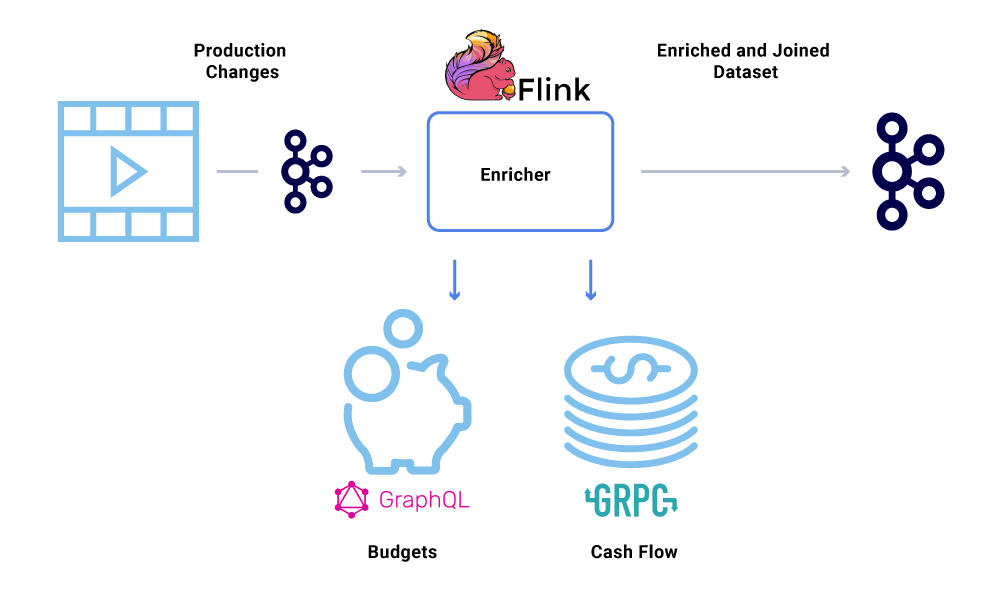
Wzbogacanie można uruchomić jako osobną mikrousługę w sobie, która jest odpowiedzialna za wykonywanie wachlarza i zmaterializowanie zestawów danych. Są przypadki, w których chcemy wykonać bardziej złożone przetwarzanie, takie jak okna, sesje i zarządzanie państwem. W takich przypadkach zaleca się użycie dojrzałego silnika przetwarzania strumienia na Kafka do budowy logiki biznesowej. W Netflix używamy Apache Flink ® i RockSDB do przetwarzania strumienia. My’Re też rozważanie KSQLDB do podobnych celów.
Zamawianie wydarzeń
Jednym z kluczowych wymagań w ramach zestawu danych finansowych jest ścisłe uporządkowanie zdarzeń. Kafka pomaga nam to osiągnąć, wysyłając kluczowe wiadomości. Każde wydarzenie lub wiadomość wysłana z tym samym kluczem, będzie miał gwarantowane zamówienie, ponieważ zostaną wysyłane na tę samą partycję. Jednak producenci mogą nadal zepsuć zamawianie wydarzeń.
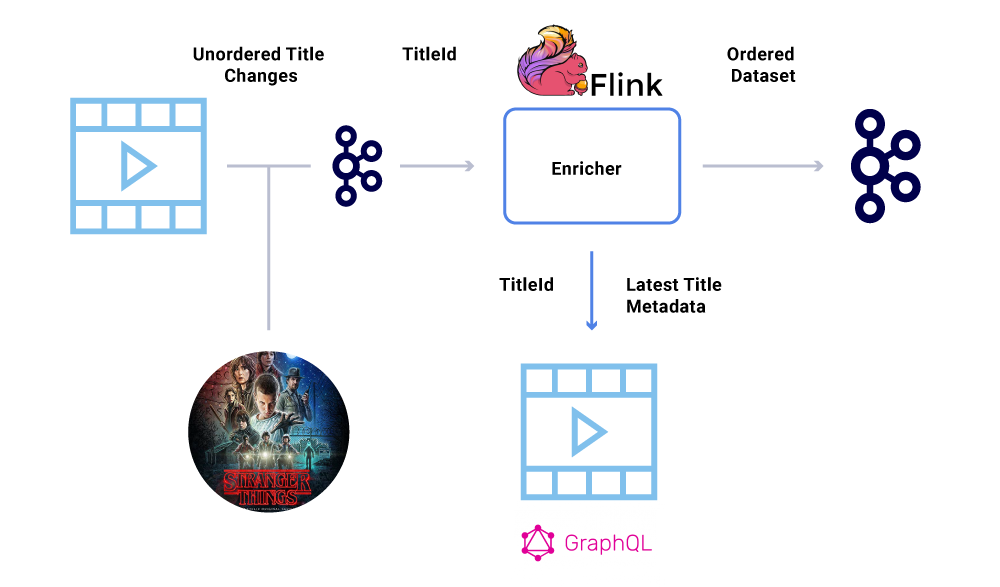
Na przykład data uruchomienia “Dziwniejsze rzeczy” został pierwotnie przeniesiony od lipca do czerwca, ale potem od czerwca do lipca. Z różnych powodów zdarzenia te można zapisać w niewłaściwej kolejności Kafce (limit czasu sieciowego, gdy producent próbował dotrzeć do Kafki, błędu współbieżności w kodzie producenta itp.). Czkawka zamawiająca mogła mieć duży wpływ na różne obliczenia finansowe.
Aby obejść ten scenariusz, producenci są zachęcani do wysyłania jedynie głównego identyfikatora jednostki, który się zmienił, a nie pełny ładunek w wiadomości Kafka. Proces wzbogacania (opisany w powyższej sekcji) zapytania o usługę źródłową z identyfikatorem jednostki w celu uzyskania najbardziej aktualnego stanu/ładunku, zapewniając w ten sposób elegancki sposób obejścia wydania poza zamówieniem. Nazywamy to jako opóźniona materializacja, i gwarantuje zamówienie zestawów danych.
Konsumenci
Używamy Spring Boot do wdrożenia wielu zużywających mikrousług, które odczytywane z tematów Kafka. Spring Boot oferuje świetnych wbudowanych konsumentów Kafka o nazwie Spring Kafka złącza, które sprawiają, że zużycie jest bezproblemowe, zapewniając łatwe sposoby podłączenia adnotacji w celu zużycia i deserializacji danych.
Jeden aspekt danych, które mamy’T omówiono jeszcze umowy. Gdy skalujemy nasze użycie strumieni zdarzeń, kończymy z różnorodną grupą zestawów danych, z których niektóre są zużyte przez dużą liczbę aplikacji. W takich przypadkach zdefiniowanie schematu na wyjściu jest idealne i pomaga zapewnić kompatybilność wsteczną. Aby to zrobić, wykorzystujemy rejestr Confluent Scheme i Apache Avro ™, aby zbudować nasze schematyzowane strumienie do wersji strumieni danych.
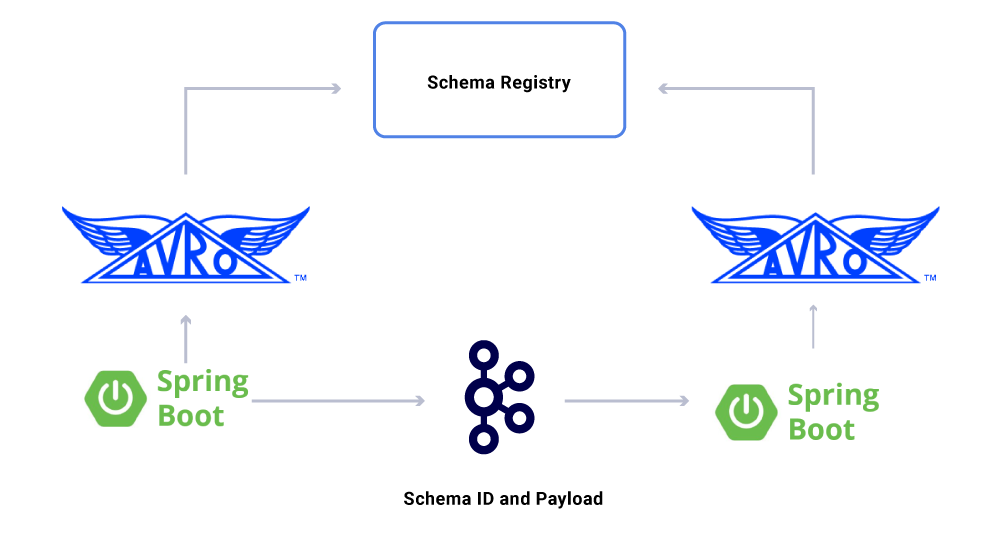
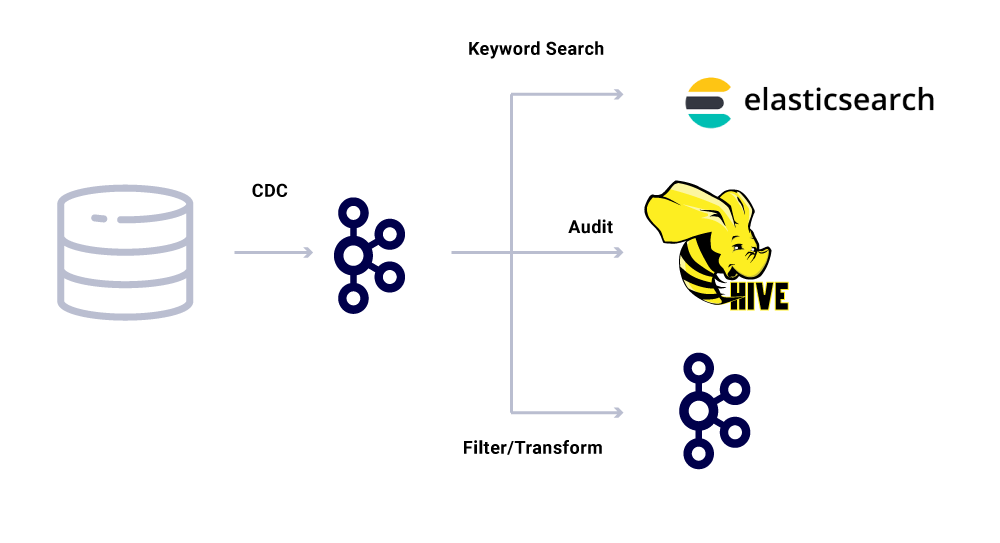
Oprócz dedykowanych konsumentów mikrousług, mamy również zlewozmywaki CDC, które indeksują dane do różnych sklepów w celu dalszej analizy. Obejmują one ElasticSearch w celu wyszukiwania słów kluczowych, Apache Hive ™ do kontroli i sam Kafka w celu dalszego przetwarzania poniżej. Ładunek takich zlewów pochodzi bezpośrednio z komunikatu Kafka za pomocą pola identyfikatora jako klucza podstawowego i typu do identyfikacji operacji CRUD.
Gwarancje dostarczania wiadomości
Gwarancja dokładnie, gdy dostawa w systemie rozproszonym jest nietrywialna ze względu na złożoność i mnóstwo ruchomych części. Konsumenci powinni mieć identyczne zachowanie, aby uwzględnić wszelkie potencjalne wpadki infrastruktury i producentów.
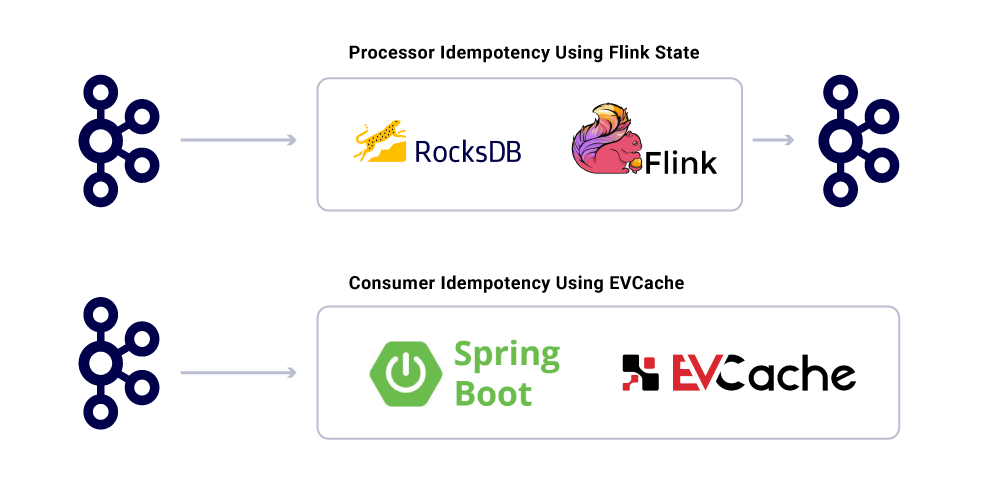
Pomimo faktu, że aplikacje są idempotentne, nie powinny one powtarzać ciężkich operacji dla już przetwarzanych wiadomości. Popularnym sposobem upewnienia się, że jest to śledzenie UUID wiadomości zużywanych przez usługę w rozproszonej pamięci podręcznej z rozsądnym wygaśnięciem (zdefiniowane na podstawie umów na poziomie usług (SLA). Za każdym razem, gdy ten sam UUID jest napotykany w przedziale wygaśnięcia, przetwarzanie jest pomijane.
Przetwarzanie w FLink zapewnia tę gwarancję, korzystając z wewnętrznego zarządzania stanem RockSDB, przy czym kluczowym jest UUID wiadomości. Jeśli chcesz to zrobić wyłącznie za pomocą Kafki, Kafka Streams oferuje również sposób na zrobienie tego. Konsumowanie aplikacji na podstawie Spring Boot używa Evcache, aby to osiągnąć.
Monitorowanie poziomów usług infrastrukturalnych
To’jest kluczowe dla Netflix, aby mieć widok na poziomie usług w czasie rzeczywistym w ramach infrastruktury. Netflix napisał Atlas do zarządzania danymi o wymiarowych szeregach czasowych, z których publikujemy i wizualizujemy wskaźniki. Korzystamy z różnych wskaźników opublikowanych przez producentów, procesorów i konsumentów, aby pomóc nam w skonstruowaniu obrazu całej infrastruktury w czasie rzeczywistym.
Niektóre z kluczowych aspektów, które monitorujemy, to:
- Świeżo SLA
- Jaki jest koniec czasu do końca od produkcji zdarzenia, dopóki nie dotrze do wszystkich zlewów?
- Jakie jest opóźnienie przetwarzania każdego konsumenta?
- Jak duży z ładunku jesteśmy w stanie wysłać?
- Czy powinniśmy skompresować dane?
- Czy skutecznie wykorzystujemy nasze zasoby?
- Czy możemy spożywać szybciej?
- Czy możemy utworzyć punkt kontrolny dla naszego stanu i wznowić w przypadku awarii?
- Jeśli nie jesteśmy w stanie nadążyć za Firehose z zdarzenia, czy możemy zastosować ciśnienie wsteczne do odpowiednich źródeł bez awarii naszej aplikacji?
- Jak radzimy sobie z seriami wydarzeń?
- Czy jesteśmy wystarczająco udostępnieni, aby spotkać się z SLA?
Streszczenie
Zespół Netflix Studio Productions and Finance obejmuje rozproszone zarządzanie jako sposób systemów architektowych. Używamy Kafki jako naszej platformy z wyboru do pracy z wydarzeniami, które są niezmiennym sposobem rejestrowania i uzyskania stanu systemu. Kafka pomogła nam osiągnąć większy poziom widoczności i oddzielenia w naszej infrastrukturze, jednocześnie pomagając nam w zakresie działalności. Serce rewolucjonizowania infrastruktury studyjnej Netflix, a wraz z nią przemysł filmowy.
Zainteresowany więcej?
Jeśli ty’D Chciad się wiedzieć, możesz zobaczyć nagranie i slajdy mojego Kafka Summit San Francisco Prezentacja wydarzeń – oryginał Netflix!
Netflix: Jak Apache Kafka zamienia dane z milionów w inteligencję
Netflix wydał 16 miliardów dolarów na produkcję treści w 2020 roku. W styczniu 2021 r. Aplikacja mobilna Netflix (iOS i Android) została pobrana 19 milionów razy i miesiąc później firma ogłosiła, że osiągnęła 203.66 milionów subskrybentów na całym świecie. To’jest bezpieczne do założenia, że skala danych, którą firma gromadzi, a procesy jest ogromne. Pytanie brzmi –
W jaki sposób Netflix przetwarza miliardy danych danych i wydarzeń w celu podejmowania krytycznych decyzji biznesowych?
Z rocznym budżetem treści o wartości 16 miliardów dolarów, decydenci w Netflix Aren’nie zamierzam podejmować decyzji związanych z treścią w oparciu o intuicję. Zamiast tego ich kuratorzy treści używają najnowocześniejszej technologii, aby zrozumieć ogromne ilości danych na temat zachowania subskrybenta, preferencji treści użytkownika, kosztów produkcji treści, rodzajów działającej treści itp. Ta lista jest długa.
Użytkownicy Netflix wydają średnio 3.2 godziny dziennie na swojej platformie i są stale karmione najnowszymi zaleceniami Netflix’S WSPÓŁPRODZIE Silnik rekomendacji. Zapewnia to, że odejście subskrybentów jest niskie i zachęca nowych subskrybentów do zarejestrowania się. Dostarczanie treści opartych na danych znajduje się z przodu i środka tego.
Więc co leży pod maską z perspektywy przetwarzania danych?
Innymi słowy, w jaki sposób Netflix zbudował szkielet technologiczny, który umożliwił podejmowanie decyzji opartych na danych na tak ogromną skalę? Jak ma sens zachowania użytkownika 203 milionów subskrybentów?
Netflix używa tego, co nazywa rurociągiem danych Keystone. W 2016 r. Rurociąg ten przetwarzał 500 miliardów zdarzeń dziennie. Zdarzenia te obejmowały dzienniki błędów, działania użytkowników, działania interfejsu użytkownika, zdarzenia związane z rozwiązywaniem problemów i wiele innych cennych zestawów danych.
Według Netflix, opublikowano na blogu technicznym:
Keystone Pipeline to zunifikowana infrastruktura wydawania wydarzeń, kolekcji i routingu zarówno dla przetwarzania wsadowego, jak i strumieniowego.
Klastry Kafka są podstawową częścią rurociągu danych Keystone w Netflix. W 2016 r. Rurociąg Netflix wykorzystał 36 klastrów Kafka do przetwarzania miliardów wiadomości dziennie.
Więc czym jest Apache Kafka? I dlaczego stało się tak popularne?
Apache Kafka to platforma przesyłania strumieniowego typu open source, która umożliwia opracowanie aplikacji, które spożywają duży ilość danych w czasie rzeczywistym. Został pierwotnie zbudowany przez geniuszów w LinkedIn i jest teraz używany w Netflix, Pinterest i Airbnb, aby wymienić kilka.
Kafka konkretnie robi cztery rzeczy:
- Umożliwia aplikacjom publikowanie lub subskrybowanie danych lub strumieni zdarzeń
- Dokładnie przechowuje rekordy danych i jest wysoce odporna na uszkodzenia
- Jest zdolny do przetwarzania danych w czasie rzeczywistym, o dużej objętości.
- Jest w stanie przyjmować i przetwarzać tryliony danych dziennie, bez żadnych problemów z wydajnością
Zespoły programistyczne są w stanie wykorzystać Kafkę’możliwości z następującymi interfejsami API:
- API producenta: Ten interfejs API umożliwia mikrousługę lub aplikację publikowanie strumienia danych do konkretnego tematu Kafka. Temat Kafka to dziennik, który przechowuje dane i rekordy zdarzeń w kolejności, w jakiej wystąpiły.
- API Consumer: Ten interfejs API pozwala aplikacji subskrybować strumienie danych z tematu Kafka. Korzystając z interfejsu API konsumenckiego, aplikacje mogą spożywać i przetwarzać strumień danych, który będzie służył jako dane wejściowe do określonej aplikacji.
- API Streams: Ten interfejs API ma kluczowe znaczenie dla wyrafinowanych aplikacji do przesyłania strumieniowego zdarzeń. Zasadniczo zużywa strumienie danych z różnych tematów Kafka i jest w stanie przetworzyć lub przekształcić je w razie potrzeby. Ten strumień danych jest publikowany na inny temat Kafka, który ma być używany w dół i/lub przekształcić istniejący temat.
- API złącza: W nowoczesnych aplikacjach istnieje ciągła potrzeba ponownego wykorzystania producentów lub konsumentów i automatycznego integracji źródła danych z klastrem Kafka. Kafka Connect sprawia, że to niepotrzebne jest łączenie Kafki z systemami zewnętrznymi.
Kluczowe korzyści Kafki
Według strony internetowej Kafka 80% wszystkich firm Fortune 100 korzysta z Kafki. Jednym z największych powodów tego jest to, że dobrze pasuje do zastosowań o krytycznych misjach.
Główne firmy korzystają z Kafki z następujących powodów:
- Z łatwością umożliwia oddzielenie strumieni danych i systemów
- Jest zaprojektowany tak, aby był rozpowszechniany, odporny i tolerujący usterki
- Poziome skalowalność Kafki jest jedną z jej największych zalet. Może skalować do 100s klastrów i milionów wiadomości na sekundę
- Umożliwia wysokowydajne przesyłanie danych w czasie rzeczywistym, krytyczną potrzebę w aplikacjach opartych na danych, opartych na danych
Sposoby, w jakie Kafka służy do optymalizacji przetwarzania danych
Kafka jest używana w różnych branżach do różnych celów, w tym między innymi
- Przetwarzanie danych w czasie rzeczywistym: Oprócz wykorzystania w firmach technologicznych, Kafka jest integralną częścią przetwarzania danych w czasie rzeczywistym w branży produkcyjnej, w której dane o dużej objętości pochodzą z dużej liczby urządzeń i czujników IoT
- Monitorowanie strony internetowej na skalę: Kafka służy do śledzenia zachowań użytkowników i aktywności witryny na stronach internetowych o wysokim ruchu. Pomaga w monitorowaniu w czasie rzeczywistym, przetwarzaniu, łączeniu z hadoopem i magazynowaniu danych offline
- Śledzenie kluczowych wskaźników: Ponieważ Kafka może być używana do agregowania danych z różnych aplikacji do scentralizowanego kanału, ułatwia monitorowanie danych operacyjnych o dużej objętości
- Agregacja dziennika: Umożliwia agregowanie danych z wielu źródeł w dzienniku, aby uzyskać jasność w zakresie rozproszonego zużycia
- System wiadomości: Automatyzuje aplikacje do przetwarzania wiadomości na dużą skalę
- Przetwarzanie strumienia: Po zużywaniu tematów Kafka jako surowych danych w przetwarzaniu rurociągów na różnych etapach, są one agregowane, wzbogacone lub w inny sposób przekształcane w nowe tematy w celu dalszego zużycia lub przetwarzania
- Zależności systemu odkładania
- Integratacje Z Spark, Flink, Storm, Hadoop i innymi technologiami Big Data
Firmy, które używają Kafki do przetwarzania danych
W wyniku jego wszechstronności i funkcjonalności Kafka jest używana przez część świata’najszybciej rozwijające się firmy technologiczne do różnych celów:
- Uber-Zbierz dane użytkownika, taksówce i podróży w czasie rzeczywistym, aby obliczyć i prognozować ceny popytu oraz obliczyć ceny w czasie rzeczywistym
- LinkedIn-zapobiega spamowi i zbiera interakcje użytkowników, aby uzyskać lepsze zalecenia dotyczące połączenia w czasie rzeczywistym
- Twitter – część infrastruktury przetwarzania strumieniowego strumienia
- Spotify – część jego systemu dostarczania dziennika
- Pinterest – część jego rurociągu zbierania dziennika
- Airbnb – rurociąg zdarzeń, śledzenie wyjątków itp.
- Cisco – dla OpenSoc (Centrum Operacji Bezpieczeństwa)
Grupa zasług’S wiedza specjalistyczna w Kafce
W Merit Group współpracujemy z niektórymi światami’wiodące firmy wywiadowcze B2B, takie jak Wilmington, Dow Jones, Glenigan i Haymarket. Nasze zespoły danych i inżynierii ściśle współpracują z naszymi klientami w celu tworzenia produktów danych i narzędzi wywiadu biznesowego. Nasza praca bezpośrednio wpływa na rozwój biznesu, pomagając naszym klientom w identyfikowaniu możliwości wzrostu wzrostu.
Nasze konkretne usługi obejmują wysoką liczbę gromadzenia danych, transformacja danych za pomocą sztucznej inteligencji i ML, oglądanie sieci i dostosowywane tworzenie aplikacji.
Nasz zespół wnosi również głęboką wiedzę specjalistyczną w zakresie budowania strumieniowego przesyłania danych i przetwarzania danych w czasie rzeczywistym. Nasza wiedza na temat Kafki jest szczególnie przydatna w tym kontekście.
Пбликация ччастника zbiegu
Do systemów architektowych, które rejestrują i wyprowadzają stan systemu, Netflix wykorzystuje Apache Kafka i rozproszone zarządzanie. Nitin s. dzieli to, w jaki sposób pomaga im osiągnąć widoczność i oddzielenie w infrastrukturze, jednocześnie ekologiczne operacje: https: // lnkd.w/gfxaa6g
Jak Netflix używa Kafka do rozproszonego strumieniowania
dopływ.io
- Коubliровать
- Świergot
Wierzący, mąż, ojciec 5, kierownik infrastruktury i usług IT, lider zespołu, deweloper.
Netflix buduje niezawodną, skalowalną platformę z pozyskiwaniem zdarzeń, MQTT i Alpakka-Kafka
Netflix opublikował niedawno post na blogu opisujący, w jaki sposób zbudował niezawodną platformę zarządzania urządzeniami za pomocą implementacji zdarzeń opartych na MQTT. Aby skalować swoje rozwiązanie, Netflix wykorzystuje Apache Kafka, Alpakka-Kafka i karaachdb.
Platforma zarządzania urządzeniami Netflix to system zarządzający urządzeniami sprzętowymi używanymi do automatycznego testowania swoich aplikacji. Netflix Inżynierowie Benson Ma i Alok Ahuja opisują podróż, przez którą przeszedł platforma:
Przetwarzanie strumieni Kafka może być trudne do zrobienia. (. ) Na szczęście prymitywy dostarczone przez Akka Streams i Alpakka-Kafka umożliwiają nam to osiągnięcie, umożliwiając budowanie rozwiązań strumieniowych pasujących do przepływów pracy biznesowej, jednocześnie zwiększając produktywność programistów w tworzeniu i utrzymaniu tych rozwiązań. Z procesorem opartym na Alpakka-Kafka (. ), zapewniliśmy tolerancję błędów po stronie konsumenckiej płaszczyzny sterowania, co jest kluczem do umożliwienia dokładnej i niezawodnej agregacji stanu urządzenia na platformie zarządzania urządzeniami.
(. ) Wiarygodność platformy i jej samolotu kontrolnego opiera się na znacznych pracach wykonanych w kilku obszarach, w tym w transporcie MQTT, uwierzytelnianiu i autoryzacji oraz monitorowaniu systemów. (. ) W wyniku tej pracy możemy spodziewać się, że platforma zarządzania urządzeniami będzie nadal skalować zwiększenie obciążeń z czasem, ponieważ na pokładzie coraz więcej urządzeń do naszych systemów.
Poniższy schemat przedstawia architekturę.

Źródło: https: // netflixtechblog.COM/w kierunku realizacji urządzeń do zarządzania-platform-4F86230CA623
Komputer wbudowany lokalne środowisko automatyzacji referencyjnej (RAE) łączy się z kilkoma testami (DUT). Lokalna usługa rejestru jest odpowiedzialna za wykrywanie, wdrażanie i utrzymanie informacji o wszystkich podłączonych urządzeniach na RAE. Gdy atrybuty i właściwości urządzenia zmieniają się z czasem, zapisuje te zmiany w rejestrze lokalnym i jednocześnie opublikowane w górę do opartej na chmurze płaszczyzny sterowania. Oprócz zmian atrybutów, lokalny rejestr publikuje pełną migawkę rekordu urządzenia w regularnych odstępach czasu. Te zdarzenia punktu kontrolnego umożliwiają szybszą rekonstrukcję stanu przez konsumentów kanału danych, chroniąc przed pominiętymi aktualizacjami.
Aktualizacje są publikowane w chmurze za pomocą MQTT. MQTT to protokół przesyłania wiadomości Oasis Standard dla Internetu rzeczy (IoT). Jest to lekka, ale niezawodna publikacja/subskrybowanie przesyłania wiadomości Ideał do łączenia zdalnych urządzeń z małym kodem i minimalnym przepustowością sieciową. Broker MQTT jest odpowiedzialny za odbieranie wszystkich wiadomości, filtrowanie ich i wysyłanie odpowiednio do subskrybowanych klientów.
Netflix używa Apache Kafka w całej organizacji. W związku z tym most przekształca wiadomości MQTT w Kafka Records. Ustawia klucz rekordu na temat MQTT, który przypisano wiadomość. Ma i Ahuja opisują, że „Ponieważ aktualizacje urządzeń opublikowane na MQTT zawierają device_session_id W temacie wszystkie aktualizacje informacji o urządzeniu dla danej sesji urządzenia będą skutecznie pojawić się na tej samej partycji Kafka, co daje nam dobrze zdefiniowane zamówienie wiadomości do konsumpcji.”
Rejestr w chmurze spożywa opublikowane wiadomości, przetwarza je i przekształca zmaterializowane dane do danych danych wspieranych przez karachdb. KarroACHDB to implementacja klasy RDBMS Systems o nazwie NewsQL. Ma i Ahuja wyjaśniają wybór Netflix:
KarroAChDB jest wybierany jako magazyn danych podkładowych, ponieważ oferował możliwości SQL, a nasz model danych dla rekordów urządzeń został znormalizowany. Ponadto, w przeciwieństwie do innych sklepów z SQL, CaracRachdb jest zaprojektowany od podstaw jako skalowalny w poziomie, co dotyczy naszych obaw dotyczących zdolności rejestru w chmurze do skalowania z liczbą urządzeń na pokładzie platformy zarządzania urządzeniami.
Poniższy schemat pokazuje rurociąg przetwarzania Kafka obejmujący rejestr chmur.
Źródło: https: // netflixtechblog.COM/w kierunku realizacji urządzeń do zarządzania-platform-4F86230CA623
Netflix rozważał wiele ram do wdrożenia rurociągów przetwarzania strumienia przedstawionych powyżej. Ramy te obejmują strumienie Kafka, Spring Kafkalistener, Reaktor Project i Flink. W końcu wybrał Alpakka-Kafka. Powodem tego wyboru jest to, że Alpakka-Kafka zapewnia integrację Spring Boot wraz z „drobnoziarnistą kontrolą nad przetwarzaniem strumienia, w tym automatyczne wsparcie i nadzór nad strumieniami.„Ponadto, według Ma i Ahuja, Akka i Alpakka-Kafka są bardziej lekkie niż alternatywy, a ponieważ są bardziej dojrzałe, koszty utrzymania w czasie będą niższe.
Implementacja oparta na Alpakka-Kafka zastąpiła wcześniejsze wiosenne wdrażanie oparte na kafkalisterze. Metryki mierzone na nowej wdrożeniu produkcji ujawniają, że natywne wsparcie wsteczne Alpakka-Kafka może dynamicznie skalować zużycie Kafka. W przeciwieństwie do Kafkalistener, Alpakka-Kafka nie jest podsumowuje ani nie przesłaga wiadomości Kafka. Ponadto spadek maksymalnych wartości opóźnienia konsumenckiego po wydaniu ujawnił, że Alpakka-Kafka i możliwości przesyłania strumieniowego AKKA działają dobrze na skalę, nawet w obliczu nagłych obciążeń wiadomości.



