
Streszczenie:
– Google buduje własny sprzęt sieciowy i oprogramowanie do sieci centrów danych.
– Ich obecne pokolenie, Jupiter Fabrics, może dostarczyć ponad 1 petabit/s całkowitej przepustowości bisekcji.
– Google korzysta z topologii Clos, scentralizowanego stosu kontroli oprogramowania i niestandardowych protokołów do zaprojektowania sieci centrów danych.
– Od dekady wdrażają i cieszą się korzyściami z sieci zdefiniowanych przez oprogramowanie (SDN).
– Sieci Google Datacenter Setworks są zbudowane dla prędkości, modułowości i dostępności i są udostępnioną infrastrukturą.
– Andromeda jest najnowszym stosem sieci Platformu Google Cloud, opartego na definiowanych oprogramowaniach sieciowych (SDN).
– Google buduje nowe centrum danych w Nebrasce w ramach 9 USD.5 miliardów inwestycji w centra danych i biura.
Unikalne pytania:
. Jak Google budował infrastrukturę sieci danych?
Google buduje własny sprzęt sieciowy i oprogramowanie, aby połączyć wszystkie serwery w swoich centrach danych, zasilając ich rozproszone systemy komputerów i pamięci. Robią to od ostatniej dekady.
2. Jaka jest pojemność bieżącej sieci danych ocen generacji?
. Ta pojemność wystarcza, aby 100 000 serwerów wymienił informacje przy 10 GB/s każda.
3. Jak Google projektuje swoje sieci centrum danych?
Google korzysta z topologii Clos, która polega na zorganizowaniu sieci wokół kolekcji mniejszych przełączników, aby zapewnić właściwości znacznie większego przełącznika logicznego. Używają również scentralizowanego stosu kontroli oprogramowania do zarządzania tysiącami przełączników w centrum danych, dzięki czemu działają jako jedna duża tkanina. Ponadto budują własne oprogramowanie i sprzęt za pomocą niestandardowych protokołów dostosowanych do centrum danych.
4. Jak długo Google wdraża i cieszył się korzyściami z definiowanego oprogramowania sieci (SDN)?
Google wdraża i cieszy się korzyściami z SDN od dekady. Wykorzystali SDN do zasilania swojego centrum danych WAN, B4, i stosu wirtualizacji sieci SDN, Andromeda.
5. Jakie są kluczowe funkcje sieci danych Google?
Sieci Google Oace Dacenter zapewniają bezprecedensową szybkość, modułowość i dostępność. Są one stale zaktualizowane, aby spełnić wymagania przepustowości ich najnowszej generacji serwerów. Sieci te są również udostępnioną infrastrukturą, zasilając zarówno wewnętrzną infrastrukturę i usługi Google, jak i Google Cloud Platform.
6. Co to jest Andromeda i jak odnosi się do Google Cloud Platform?
Andromeda to podłoże oparte na sieciach sieciowych (SDN) do wysiłków wirtualizacji sieci Google. Jest to punkt orkiestrowy dla udostępniania, konfigurowania i zarządzania sieciami wirtualnymi i przetwarzaniem pakietów w sieci w Google Cloud Platform.
7. Jaki jest plan inwestycyjny Google dla centrów danych i biur?
Google planuje zainwestować 9 USD.5 miliardów w centrach danych i biurach, a w ramach tego planu budują nowe centrum danych w Nebrasce.
8. Dlaczego Google buduje własny sprzęt sieciowy i oprogramowanie do sieci centrów danych?
Google zaczęło budować własny sprzęt sieciowy i oprogramowanie, ponieważ nie było żadnych rozwiązań, które mogłyby spełnić ich rozproszone wymagania dotyczące komputerów. Kontynuowali to, aby zapewnić świetną infrastrukturę obliczeniową dla swoich centrów danych.
9. ?
Google użył trzech kluczowych zasad projektowania sieci centrów danych: układanie sieci wokół topologii Clos, korzystanie z scentralizowanego stosu sterowania oprogramowaniem oraz budowanie własnego oprogramowania i sprzętu za pomocą niestandardowych protokołów dostosowanych do centrum danych.
10. Dlaczego sieci Datacenter Google są uważane za infrastrukturę udostępnioną?
Datacenter Datacenter Google zasilaj zarówno infrastrukturę wewnętrzną, jak i usługi, a także Google Cloud Platform. Oznacza to, że te same sieci są dostępne dla programistów na całym świecie, umożliwiając im wykorzystanie światowej klasy infrastruktury sieciowej bez konieczności budowania.
11. ?
Zespół operacyjny Google wdrożył i ponownie wdrożył wiele pokoleń swojej sieci w całej infrastrukturze, aby zaspokoić potrzeby przepustowości ich systemów rozproszonych. Ściśle współpracują z najlepszym na świecie zespołem inżynierii i operacji sieciowych, aby zapewnić dostępność swoich sieci.
12. Jaki jest cel Andromedy w Google Cloud Platform?
Andromeda służy jako punkt orkiestracji do udostępniania, konfigurowania i zarządzania sieciami wirtualnymi i przetwarzaniem pakietów w sieci w Google Cloud Platform. Jest kluczowym elementem możliwości sieciowych platformy.
13. W jaki sposób infrastruktura sieci danych Google wykorzystuje sieci definiowane oprogramowanie (SDN)?
Google od dekady wdraża SDN w swojej infrastrukturze sieci danych. Wykorzystali SDN do zasilania swojego centrum danych WAN, B4, a także stosu wirtualizacji sieciowej, Andromeda. Przyjęli architektoniczne idee SDN w swoich systemach sieciowych.
14. Jakie jest znaczenie inwestycji Google w centra danych i biura?
Inwestycja Google w wysokości 9 USD.5 miliardów centrów danych i biur odzwierciedla ich zaangażowanie w rozszerzenie infrastruktury i możliwości. To pokazuje ich zaufanie do rozwoju ich usług i rosnące zapotrzebowanie na Google Cloud.
15. W jaki sposób infrastruktura sieci danych Google przyczynia się do Google Cloud Platform?
Infrastruktura sieci danych Google jest współdzieloną infrastrukturą, która zasila zarówno wewnętrzną infrastrukturę Google, jak i Platform Google Cloud Platform. Pozwala to programistom na całym świecie wykorzystać światowej klasy infrastrukturę sieciową bez konieczności budowania jej samej, umożliwiając im tworzenie innowacyjnych usług i platform internetowych.
Google zaprezentuje nowe centrum danych o wartości 750 mln USD w ramach 9 USD.5B Gol
Uczenie maszynowe jest integralną częścią dużych zbiorów danych. Jak powiedział Ryan Den Rooijen, Global Możilności, Insights & Innovation, powiedział przed szczytem innowacji Big Data w Londynie (marzec 2017 r.), “Większość problemów, które zaobserwowałem, dotyczy tego, jak sprawić, by te dane były przydatne… w celu zwiększenia znaczącego wpływu na biznes.” Dlatego oprócz korzystania z uczenia maszynowego do produktów takich jak Google Translate, Google wykorzystuje również swoje sieci neuronowe do przewidywania PUE swoich centrów danych.
Czy Google jest własnością centrum danych
VP i GM, infrastruktura systemów i usług
Google od dawna jest pionierem w rozproszonym przetwarzaniu i przetwarzaniu danych, od systemu plików Google po MapReduce po BigTable i Borg. Od samego początku my’wiedzą, że taka świetna infrastruktura obliczeniowa, taka jak ta wymaga świetnej technologii sieci centrów danych. Ale kiedy Google zaczynał, nikt nie stworzył sieci centrum danych, która mogłaby spełnić nasze rozproszone wymagania dotyczące obliczeń.
Tak więc przez ostatnią dekadę budowaliśmy własny sprzęt i oprogramowanie sieci. Teraz otworzyliśmy tę potężną i transformacyjną infrastrukturę do użytku przez zewnętrznych programistów za pośrednictwem Google Cloud Platform.
Na szczycie otwartego sieci w 2015 r. Po raz pierwszy ujawniliśmy szczegóły pięciu pokoleń naszej wewnętrznej technologii sieciowej. Od Firehose, naszej pierwszej wewnętrznej sieci centrum danych, dziesięć lat temu, po naszą najnowszą generację Jupiter Network, my’zwiększył pojemność pojedynczej sieci centrum danych o ponad 100x. Nasza obecna generacja – tkaniny Jupiter – może dostarczyć ponad 1 petabit/s całkowitej przepustowości bisekcji. Aby spojrzeć na to z perspektywy, taka pojemność wystarcza 100 000 serwerów do wymiany informacji po 10 GB/s, wystarczającą do przeczytania całej zeskanowanej zawartości Biblioteki Kongresu w mniej niż 1/10 sekundy.

Użyliśmy trzech kluczowych zasad projektowania naszych sieci centrum danych:
- Umieszczamy naszą sieć wokół topologii Clos, konfiguracji sieci, w której zbiór mniejszych (tańszych) przełączników jest ułożony w celu zapewnienia właściwości znacznie większego przełącznika logicznego.
- Używamy scentralizowanego stosu kontroli oprogramowania do zarządzania tysiącami przełączników w centrum danych, dzięki czemu skutecznie działają jako jedna duża tkanina.
- Budujemy własne oprogramowanie i sprzęt przy użyciu krzemowego od dostawców, opierając się mniej na standardowych protokołach internetowych, a więcej na niestandardowych protokołach dostosowanych do centrum danych.
Podsumowując, nasz stos kontroli sieci ma więcej wspólnego z Google’S rozproszone architektury obliczeniowe niż tradycyjne protokoły internetowe zorientowane na router. Niektórzy mogą nawet powiedzieć, że my’od dekady wdrażał i cieszył się korzyściami wynikającymi z korzyści wynikających z sieci zdefiniowanych przez oprogramowanie (SDN) w Google. Kilka lat temu ujawniliśmy, w jaki sposób SDN zasilał Google’S Datacenter Wan, B4, jeden ze świata’S największy WAN. W zeszłym roku pokazaliśmy szczegóły GCP’S SDN Network Stack, Andromeda. W rzeczywistości pomysły architektoniczne obu tych systemów pochodzą z naszej wczesnej pracy w sieciach danych danych.
Budowanie świetnych sieci centrów danych to nie tylko budowanie świetnego sprzętu i oprogramowania. To’o współpracy ze światem’najlepszy zespół inżynierii i operacji sieciowych od pierwszego dnia. Nasze podejście do nawiązywania kontaktów zasadniczo zmienia organizację sieci’S PLANY DANE, KONTROLA I KONTROLI. Taka fundamentalna zmiana nie przychodzi bez żadnych nierówności, ale nasz zespół operacyjny ma więcej niż wyzwanie. My’VE wdrożone i przeredagowane wiele pokoleń naszej sieci w naszej infrastrukturze na skalę planetarną, aby nadążyć za potrzebami przepustowości naszych systemów rozproszonych.
Łącząc to wszystko, nasze sieci centrum danych zapewniają niespotykaną prędkość w skali całych budynków. Są zbudowane dla modułowości, stale zaktualizowane, aby sprostać nienasyconym wymaganiom przepustowości najnowszej generacji naszych serwerów. Są zarządzane pod kątem dostępności, spełniając wymagania dotyczące czasu pracy niektórych z najbardziej wymagających usług internetowych i klientów. Co najważniejsze, nasze sieci centrów danych są współużytkowaną infrastrukturą. Oznacza to, że te same sieci, które napędzają wszystkie Google’S Wewnętrzna infrastruktura i usługi zasilaj również Google Cloud Platform. Jesteśmy najbardziej podekscytowani otwarciem tej zdolności dla programistów na całym świecie, aby kolejna świetna usługa internetowa lub platforma mogła wykorzystać światowej klasy infrastrukturę sieciową bez konieczności wymyślania.
Google Cloud
Wprowadź strefę Andromeda: najnowszy stos sieci w chmurze Google
Andromeda to podłoże oparte na sieciach sieciowych (SDN) dla naszych działań wirtualizacji sieciowej. Jest to punkt orkiestrowy do udostępniania, konfigurowania i zarządzania sieciami wirtualnymi i przetwarzaniem pakietów w sieci.
Autor: Amin Vahdat • 3-minutowy odczyt

- Google Cloud
- Infrastruktura
- Systemy
Google zaprezentuje nowe centrum danych o wartości 750 mln USD w ramach 9 USD.5B Gol
Jako popyt na Google Cloud Soars, Google buduje nowe centrum danych w Nebrasce w ramach swojej strategii inwestowania 9 USD.5 miliardów w centrach danych i biurach w 2022 r.

Google spełnia obietnicę wydania 9 USD.5 miliardów w nowych centrach danych Google i biurach w 2022 r. Z odsłonięciem nowego centrum danych o wartości 750 milionów dolarów w Nebrasce.
Ogromny nowy kampus Google w Omaha, Neb., będzie składał się z czterech budynków o łącznej wartości więcej niż 1.4 miliony stóp kwadratowych, ponieważ popyt na usługi w chmurze Google i infrastruktura. W Google Cloud’S Ostatni czwarty kwartał, firma odnotowała wzrost sprzedaży o 45 procent rok do roku do 5 USD.5 miliardów.
“[Nowe centrum danych] przyniesie więcej możliwości społeczności lokalnej i więcej zasobów dla naszych klientów do rozwoju swoich firm i korzystania z usług cyfrowych,” Stacy Trackey Meagher, dyrektor zarządzający Google Cloud’S Central Region, w oświadczeniu.
Nowe Google Data Center w Nebrasce jest częścią Mountain View w Kalifornii.-Wyszukiwanie i gigant chmurowy’S planuje zainwestować w sumie 9 USD.5 miliardów w centrach danych i u.S.-biura oparte do końca 2022 r.
Według Synergy Research Group Google jest jednym z największych wydatków na budowanie nowych centrów danych na całym świecie, inwestując miliardy w budowę i wyposażanie centrów danych hiperskalnych w celu zaspokojenia rosnących wymagań klientów w chmurze. Google, Amazon Web Services i Microsoft mają najszersze ślady centrum danych na świecie, przy czym każde hostuje co najmniej 60 lub więcej lokalizacji centrum danych.
Centra danych to “Ważne kotwice” Dla klientów i społeczności lokalnych, powiedział dyrektor generalny Google Sundar Pichai w poście na blogu w tym miesiącu.
“Nasze inwestycje w centra danych będą nadal zasilać cyfrowe narzędzia i usługi, które pomagają ludziom i firmom,” powiedział Google’S Pichai.
Google’Plany rozszerzenia centrum danych
Oprócz nowego centrum danych w Nebrasce, Google planuje wydać w tym roku miliardy na centra danych w Gruzji, Iowa, Oklahoma, Nevadzie, Tennessee, Wirginii i Teksasie.
“W u.S. W ciągu ostatnich pięciu lat my’. To’S oprócz ponad 40 miliardów dolarów w badaniach i rozwoju, które zainwestowaliśmy w U.S. w 2020 i 2021,” powiedział Pichai.
Centra danych umożliwiają usługi i infrastrukturę Google Cloud, w tym flagowa oferta Google Cloud Platform (GCP).
W 2021 r. GCP odnotowało ponad 80 procent wzrostu całkowitego objętości transakcji w porównaniu z 2020 r. I ponad 65 procent wzrostu liczby transakcji przekraczających 1 miliard dolarów.
Ogólnie rzecz biorąc, Google Cloud ma obecnie roczną stawkę przychodów 22 USD.16 miliardów.
Google Data Center FAQ Część 3
Jak Google decyduje, gdzie budować swoje centra danych?
Google wybiera lokalizacje swoich centrów danych na podstawie kombinacji czynników, które obejmują lokalizację klienta, dostępną siłę roboczą, bliskość infrastruktury transmisji, rabaty podatkowe, stawki użyteczności publicznej i inne powiązane czynniki. Jego niedawne skupienie się na rozszerzeniu infrastruktury chmurowej dodało więcej rozważań, takich jak zapotrzebowanie klientów w chmurze przedsiębiorstw w niektórych lokalizacjach i bliskość centrów populacji o dużej gęstości.
Wybór ST. Ghislain, Belgia dla centrum danych (które zostało otwarte w 2010 r.) Opierało się na połączeniu infrastruktury energetycznej, gruntów rozwojowych, silnym lokalnym wsparciem dla zaawansowanych technologii i obecności klastry technologicznej firm, które aktywnie wspierają edukację technologiczną w pobliskich szkołach i uniwersytetach.
Kolejny czynnik to pozytywny klimat biznesowy. Według Google w połączeniu z dostępną ziemią i mocą sprawiła, że Oklahoma jest szczególnie atrakcyjny’S, starszy dyrektor operacyjny, kiedy ogłoszono witrynę Pryor Creek. W Oregonie pozytywne środowisko biznesowe oznacza zlokalizowanie w stanie, który nie ma podatku od sprzedaży. Lokalni komisarze hrabstwa WASCO również zwolnili Google dla większości podatków od nieruchomości, jednocześnie wymagając od jednorazowej płatności w wysokości 1 USD.7 do samorządów i płatności w wysokości najmniej 1 miliona dolarów rocznie.
Bliskość odnawialnych źródeł energii staje się również coraz ważna. Google jest strategicznie inwestowany w zasoby odnawialne i rozważa swój ślad środowiskowy podczas umieszczania nowych centrów danych.
Czy Centra danych Google wykorzystują energię odnawialną?
Google kupuje więcej energii odnawialnej niż jakakolwiek korporacja na świecie. It 2016 Kupił wystarczającą energię, aby uwzględnić ponad połowę zużycia energii. W 2017 r. Aby to zrobić, Google podpisał 20 umów zakupu na 2.6 Gigawatts (GW) energii odnawialnej. Oznacza to, że chociaż energia odnawialna może nie być dostępna wszędzie lub w ilościach, które Google potrzebuje, Google kupuje taką samą ilość energii odnawialnej, jak zużywa.
Google również popełnił 2 USD.5 miliardów funduszy kapitałowych na rozwój energii słonecznej i wiatrowej, które można dodać do sieci energetycznej na całym świecie. Ta gotowość do finansowania projektów odnawialnych jest w celu stopniowego rozszerzenia rynku energii odnawialnej pod względem dostępnych, a także poprzez zmianę sposobów zakupu energii odnawialnej. W tym procesie korzystanie z źródeł odnawialnych staje się łatwiejsze i bardziej opłacalne dla wszystkich.

Widok Google Data Center w Hamina w Finlandii, z turbiną wiatrową obok niego
Zrównoważony rozwój jest również przedmiotem centrów danych. Św. Ghislain, Belgia, centra danych to Google’najpierw polegać całkowicie na bezpłatnym chłodzeniu. I ten obiekt’S Plant oczyszczania wody na miejscu pozwala centrom danych na recykling wody z kanału przemysłowego, a nie stuknięcie regionu’S zaopatrzenie w słodką wodę.
Ile energii wykorzystują Centra danych Google?
Zużycie energii w centrum danych reprezentuje znaczną część 5.7 Terawatt Hours jej spółka dominująca, Alphabet, używana w 2015 roku. Ze średnim pue 1.12 (w porównaniu z średnią branżową 1.7), Google twierdzi, że jego centra danych wykorzystują połowę energii typowego centrum danych. Rosnąca część tego jest odnawialna, dostarczana na podstawie umów o zakup mocy.
Jakiego rodzaju sprzętu i oprogramowania wykorzystuje Google w swoich centrach danych?
To’nie jest tajemnicą, że Google zbudowało własną infrastrukturę internetową od 2004 r. Powstały hierarchiczny projekt siatki jest standardem we wszystkich centrach danych.
Sprzęt jest zdominowany przez niestandardowe serwery zaprojektowane przez Google i Jupiter, Switch Google wprowadzony w 2012 roku. Dzięki ekonomii skali Google kontraktuje bezpośrednio z producentami, aby uzyskać najlepsze oferty.

Jevgeniy Sverdlik
Google’Przełączniki sieciowe Jowisz na wyświetlacz w Google Cloud w następnym 2017 roku w San Francisco
Google’Serwery S i oprogramowanie sieciowe uruchamiają utwardzoną wersję systemu operacyjnego Linux Open Source. Poszczególne programy zostały napisane wewnętrznie. Zgodnie z naszą najlepszą wiedzą obejmują one:
- Google Web Server (GWS)-niestandardowy serwer WWW oparty na Linux, którego Google używa do swoich usług online.
- Systemy przechowywania:
- Colossus-system plików na poziomie klastra, który zastąpił system plików Google
- Cofeine – system ciągłego indeksowania uruchomiony w 2010 roku w celu zastąpienia Teragoogle
- Hummingbird – Algorytm głównego indeksu wyszukiwania wprowadzony w 2013 roku.
Google opracował również kilka abstrakcji, których używa do przechowywania większości swoich danych:
- Bufory protokołów-neutralne dla języka, neutralne platformy, rozszerzalny sposób serializacji danych strukturalnych do użytku w protokole komunikacji, przechowywania danych i innych
- SSTable (Tabela sortowanej Strings) – trwałość, uporządkowana, niezmienna mapa od klawiszy do wartości, w której zarówno klucze, jak i wartości są dowolnymi ciągami bajtów. Jest również używany jako jeden z elementów budulcowych Bigtable
- Recordio – plik definiujący interfejsy IO kompatybilne z Google’SPECYFIKACJE S IO
W jaki sposób Google wykorzystuje uczenie maszynowe w swoich centrach danych?
Uczenie maszynowe jest integralną częścią dużych zbiorów danych. Jak powiedział Ryan Den Rooijen, Global Możilności, Insights & Innovation, powiedział przed szczytem innowacji Big Data w Londynie (marzec 2017 r.), “Większość problemów, które zaobserwowałem, dotyczy tego, jak sprawić, by te dane były przydatne… w celu zwiększenia znaczącego wpływu na biznes.” Dlatego oprócz korzystania z uczenia maszynowego do produktów takich jak Google Translate, Google wykorzystuje również swoje sieci neuronowe do przewidywania PUE swoich centrów danych.
Google oblicza Pue co 30 sekund i ciągle śledzi obciążenie, zewnętrzną temperaturę powietrza i poziomy urządzeń mechanicznych i chłodzących. Dane te pozwalają inżynierom Google opracować model predykcyjny, który analizuje złożone interakcje wielu zmiennych w celu odkrycia wzorców, które można wykorzystać, aby poprawić zarządzanie energią. Na przykład, kiedy Google wziął kilka serwerów w trybie offline na kilka dni, inżynierowie wykorzystali ten model do dostosowania chłodzenia, aby utrzymać efektywność energetyczną i zaoszczędzić pieniądze. Model to 99.6 procent dokładnych.
W lipcu 2016 r. Google ogłosił wyniki testu systemu AI przez brytyjskie przejęcie DeepMind. System ten zmniejszył zużycie energii przez jednostki chłodzące centrum danych nawet o 40% i ogólnie PUE o 15%. System przewiduje temperatury na godzinę wcześniej, umożliwiając regulację chłodzenia w oczekiwaniu.
Czy Google wynajęło powierzchnię w innych firmach’ Centra danych?
Tak. Google wynajmuje przestrzeń od innych, gdy ma to sens. Nie każde centrum danych Google ma swoją nazwę na drzwiach. Zamiast tego firma wykorzystuje różne strategie, aby zaspokoić swoje potrzeby w centrum danych. Na przykład wynajmuje miejsce na miejsca buforowania, i wykorzystuje strategię mieszanej budowy i leasingu dla swojego globalnego wdrożenia Cloud Data Center.
Czy Google jest własnością centrum danych
Amin Vahdat
VP i GM, infrastruktura systemów i usług
Sieci centrów danych stanowią podstawę do nowoczesnego obliczeń magazynowych i przetwarzania w chmurze. Podstawowa gwarancja jednolitej, arbitralnej komunikacji między dziesiątkami tysięcy serwerów przy 100 GB/s przepustowości z opóźnieniem poniżej 100US przekształciła komputer i przechowywanie. Główną zaletą tego modelu jest prosta, ale głęboka: dodanie przyrostowego serwera lub urządzenia pamięci masowej do usługi wyższego poziomu zapewnia proporcjonalny wzrost pojemności i możliwości serwisowych. W Google nasza technologia sieci Jupiter Data Center obsługuje tego rodzaju możliwości skalowania usług fundamentalnych dla naszych użytkowników, takich jak wyszukiwanie, YouTube, Gmail i Cloud Services, takie jak AI i uczenie maszynowe, silnik Compute, BigQuery Analytic.
Ostatnie osiem lat spędziliśmy głęboko integrację przełączania obwodu optycznego (OCS) i multipleksowania podziału falowego (WDM) do Jowisza. Podczas gdy dziesięciolecia konwencjonalnej mądrości sugerowały, że było to niepraktyczne, kombinacja OCS z naszą architekturą zdefiniowaną w sieci (SDN) umożliwiła nowe możliwości: Obsługa kompilacji sieci przyrostowych z heterogenicznymi technologiami; wyższa wydajność i niższa opóźnienie, koszt i zużycie energii; priorytety i wzorce komunikacji w czasie rzeczywistym; i ulepszenia zerowego czasu. Jupiter robi to wszystko, jednocześnie zmniejszając zakończenie przepływu o 10%, poprawiając przepustowość o 30%, przy użyciu o 40% mniejszej mocy, ponosząc o 30% mniej kosztów i dostarczając 50 -krotnie mniej przestojów niż najbardziej znane alternatywy. Możesz przeczytać więcej o tym, jak to zrobiliśmy w artykule, który zaprezentowaliśmy dzisiaj na Sigcomm 2022, Jupiter Evolving: Transforming Google’s Datacenter Sieć za pomocą przełączników obwodów optycznych i sieci zdefiniowanej przez oprogramowanie.
Oto przegląd tego projektu.
Ewoluujące sieci centrum danych Jupiter
W 2015 r. Pokazaliśmy, w jaki sposób nasze sieci centrum danych Jupiter skalowały do ponad 30 000 serwerów o jednolitym łączności 40 GB/s na serwer, obsługując więcej niż 1pb/s łącznej przepustowości. Dzisiaj Jupiter obsługuje ponad 6pb/s. Dostarczyliśmy ten nigdy nie widziany poziom wydajności i skali, wykorzystując trzy pomysły:
- Oprogramowanie zdefiniowane w sieci (SDN) – logicznie scentralizowana i hierarchiczna samolot sterowania do zaprogramowania i zarządzania tysiącami układów przełączających w sieci centrum danych.
- Topologia Clos – Nie blokująca wielostopniowa topologia przełączania, zbudowana z mniejszych układów przełączników Radix, które mogą skalować się do arbitralnie dużych sieci.
- Merchant Switch Silicon – Opłacalne, komponenty przełączania Ethernet w zakresie przełączania Ethernet dla zbieżnej sieci pamięci i sieci danych.
Opierając się na tych trzech filarach, Jowisz’Podejście architektoniczne wsparło zmianę morską w architekturze systemów rozproszonych i ustanowiło ścieżkę dla tego, jak przemysł jako całość buduje i zarządza sieciami centrów danych.
Pozostały jednak dwa główne wyzwania dla centrów danych hiperskalnych. Po pierwsze, sieci centrów danych muszą być wdrażane w skali całego budynku – być może 40 MW lub więcej infrastruktury. Ponadto serwery i urządzenia do przechowywania w budynku zawsze ewoluują, na przykład przenoszą się z 40 GB/s do 100 GB/s do 200 GB/s, a dziś 400 GB/s Natywne połączenia sieciowe. Dlatego sieć centrum danych musi ewoluować dynamicznie, aby dotrzymać kroku łączeniu się z nią nowymi elementami.
Niestety, jak pokazano poniżej, topologie Clow wymagają warstwy kręgosłupa z jednolitym wsparciem dla najszybszych urządzeń, które mogą się z nim połączyć. Wdrożenie sieci centrum danych w skali budowlanej oznaczało wstępne wdrożenie bardzo dużej warstwy kręgosłupa, która trwała ze stałą prędkością najnowszej generacji dnia. Dzieje się tak, ponieważ z natury wymagają topologie zamykania wszystko do wszystkich fanout z bloków agregacji 1 do kręgosłupa; Dodanie do kręgosłupa stopniowo wymagałoby ponownego połączenia całego centrum danych. Jednym ze sposobów obsługi nowych urządzeń działających w szybszych prędkościach linii byłoby zastąpienie całej warstwy kręgosłupa na obsługę nowszej prędkości, ale byłoby to niepraktyczne, biorąc pod uwagę setki poszczególnych stojaków, które znajdują się przełączniki i dziesiątki tysięcy par włókien biegających po całym budynku.
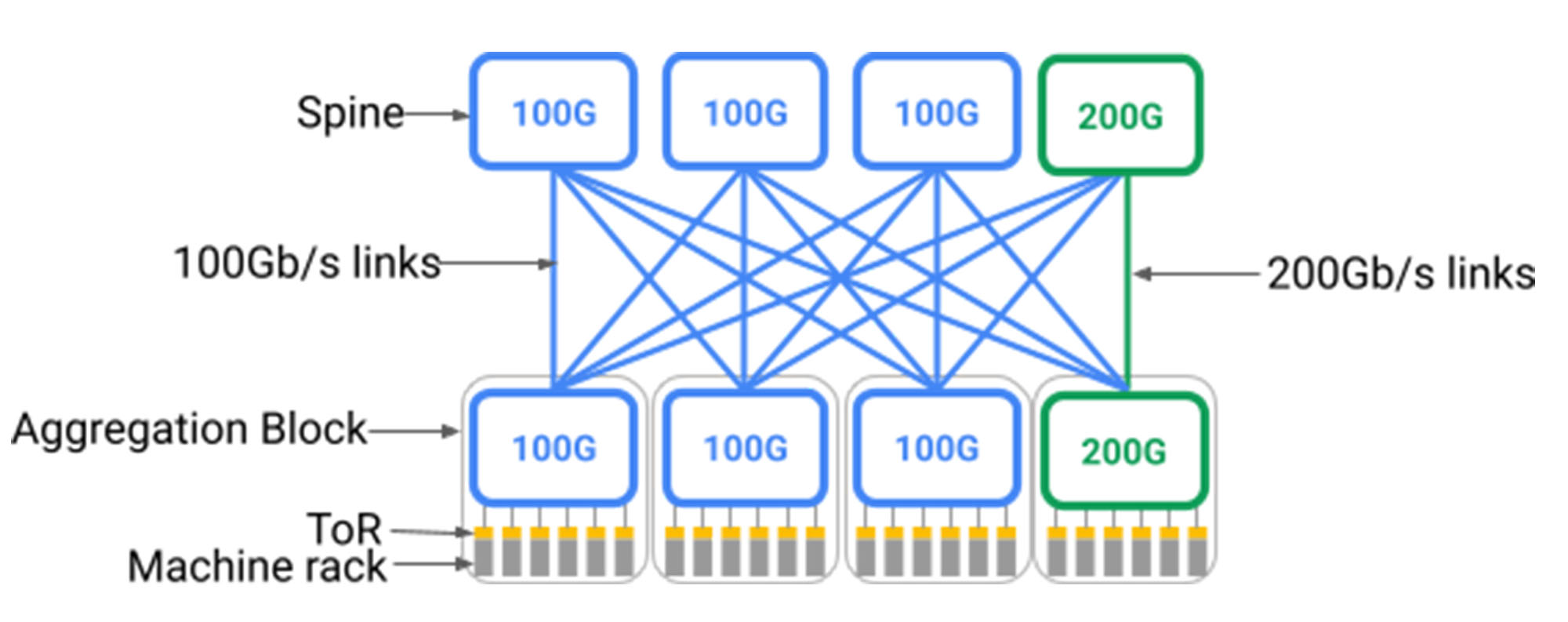
Figa. Nowy blok agregacji (zielony) z prędkością portu 200 GB/s jest podłączony do 3 starych bloków kręgosłupa (niebieski) o prędkości portu 100 GB/s i jednego nowego bloku kręgosłupa (zielony) z prędkością portu 200 GB/s. W tym modelu tylko 25% linków z nowego bloku agregacji i nowego bloku kręgosłupa biegnie przy 200 GB/s.
Idealnie, sieć centrum danych obsługiwałaby heterogeniczne elementy sieciowe w “płacić w miarę uprawy” Model, dodanie elementów sieciowych tylko w razie potrzeby i wspieranie najnowszej generacji technologii stopniowo. Sieć obsługiwałaby ten sam wyidealizowany model skalowania, który umożliwia serwerom i magazynie, umożliwiając przyrostowe dodanie pojemności sieci-nawet jeśli z innej technologii niż wcześniej wdrożone-w celu zapewnienia proporcjonalnej wzrostu pojemności i natywnej interoperacyjności dla całego budowy urządzeń.
Po drugie, podczas gdy jednolita przepustowość w skali budynku jest siłą, staje się ona ograniczającą, gdy weźmie się pod uwagę, że sieci centrów danych są z natury wielopoziomowe i stale podlegają konserwacji i zlokalizowanemu awarie. Pojedyncza sieć centrum danych prowadzi setki poszczególnych usług o różnych poziomach priorytetu i wrażliwości na zmianę przepustowości i opóźnienia. Na przykład obsłużenie wyników wyszukiwania sieci w czasie rzeczywistym może wymagać gwarancji opóźnień w czasie rzeczywistym i przydziału przepustowości, podczas gdy wielogodzinne zadanie analizy partii może mieć bardziej elastyczne wymagania przepustowości na krótki czas. Biorąc to pod uwagę, sieć centrum danych powinna przydzielić przepustowość i ścieżkę usług opartych na wzorcach komunikacji w czasie rzeczywistym i optymalizacji sieci świadomej aplikacji. Idealnie, jeśli 10% pojemności sieci musi zostać tymczasowo usunięte w celu ulepszenia, wówczas 10% nie powinno być równomiernie rozmieszczone na wszystkich najemcach, ale podzielone na podstawie indywidualnych wymagań aplikacji i priorytetu.
Rozwiązanie tych pozostałych wyzwań wydawało się początkowo niemożliwe. Sieci centrów danych zostały zbudowane wokół hierarchicznych topologii w masywnej skali fizycznej, tak że nie mogły być włączone do projektu przyrostowej heterogeniczności i dynamicznej adaptacji aplikacji. Złamaliśmy ten impas, rozwijając i wprowadzając Przełączanie obwodu optycznego (OCS) do architektury Jowisza. Przełącznik obwodu optycznego (przedstawiony poniżej) mapuje dynamicznie port wejściowy światłowodowy do portu wyjściowego przez dwa zestawy luster systemów mikroelektromechanicznych (MEMS), które można obrócić w dwóch wymiarach, aby utworzyć dowolne mapowania portu do portu.
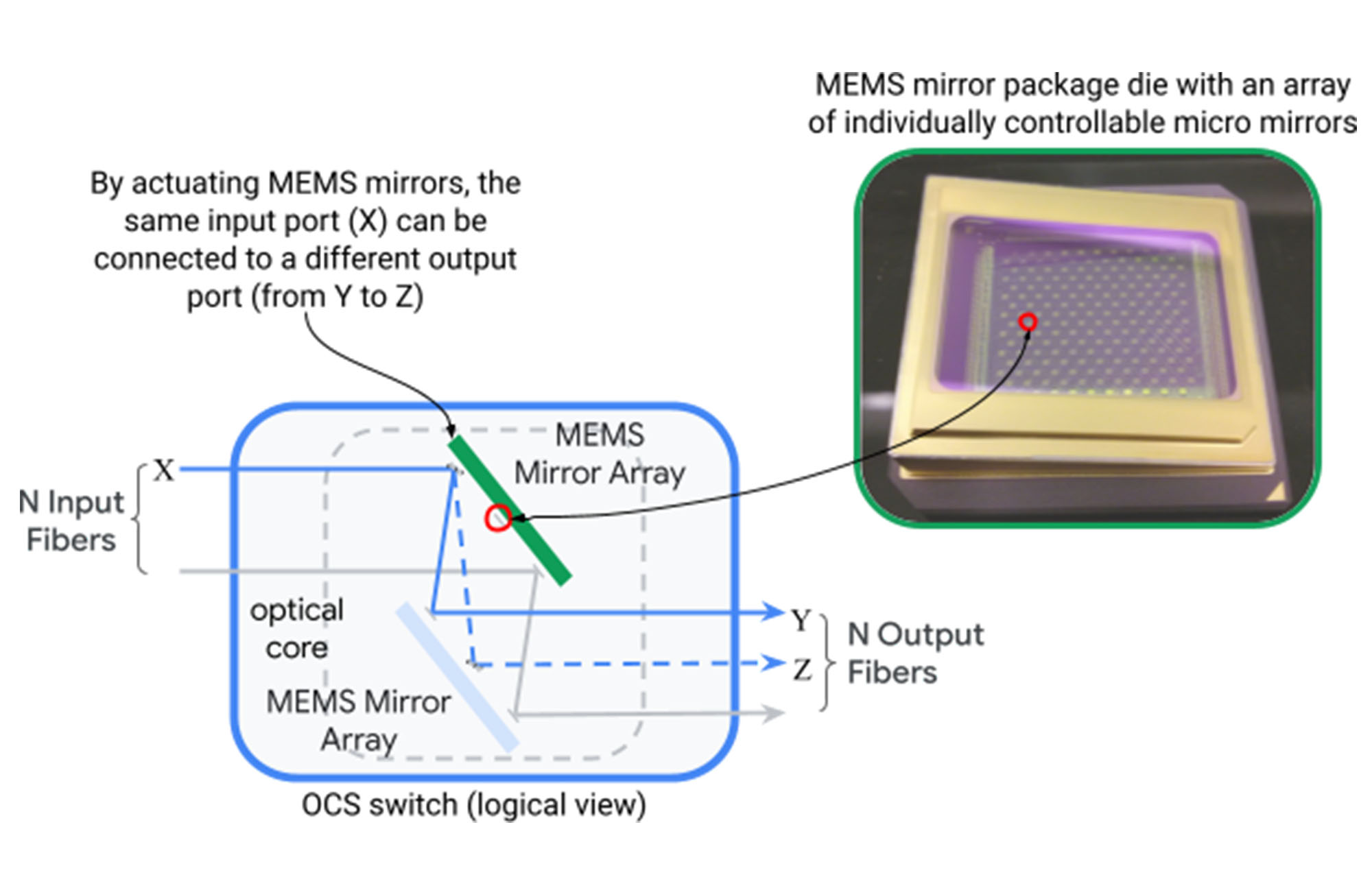
Figa. Działanie pojedynczego mapowania urządzenia OCS n wejściowe na N Włókna wyjściowe za pośrednictwem MEMS Mirrors.
Mieliśmy wgląd, że moglibyśmy stworzyć dowolne logiczne topologie dla sieci centrów danych, wprowadzając warstwę pośredniczącego OCS między przełącznikami pakietów centrum danych, jak pokazano poniżej.
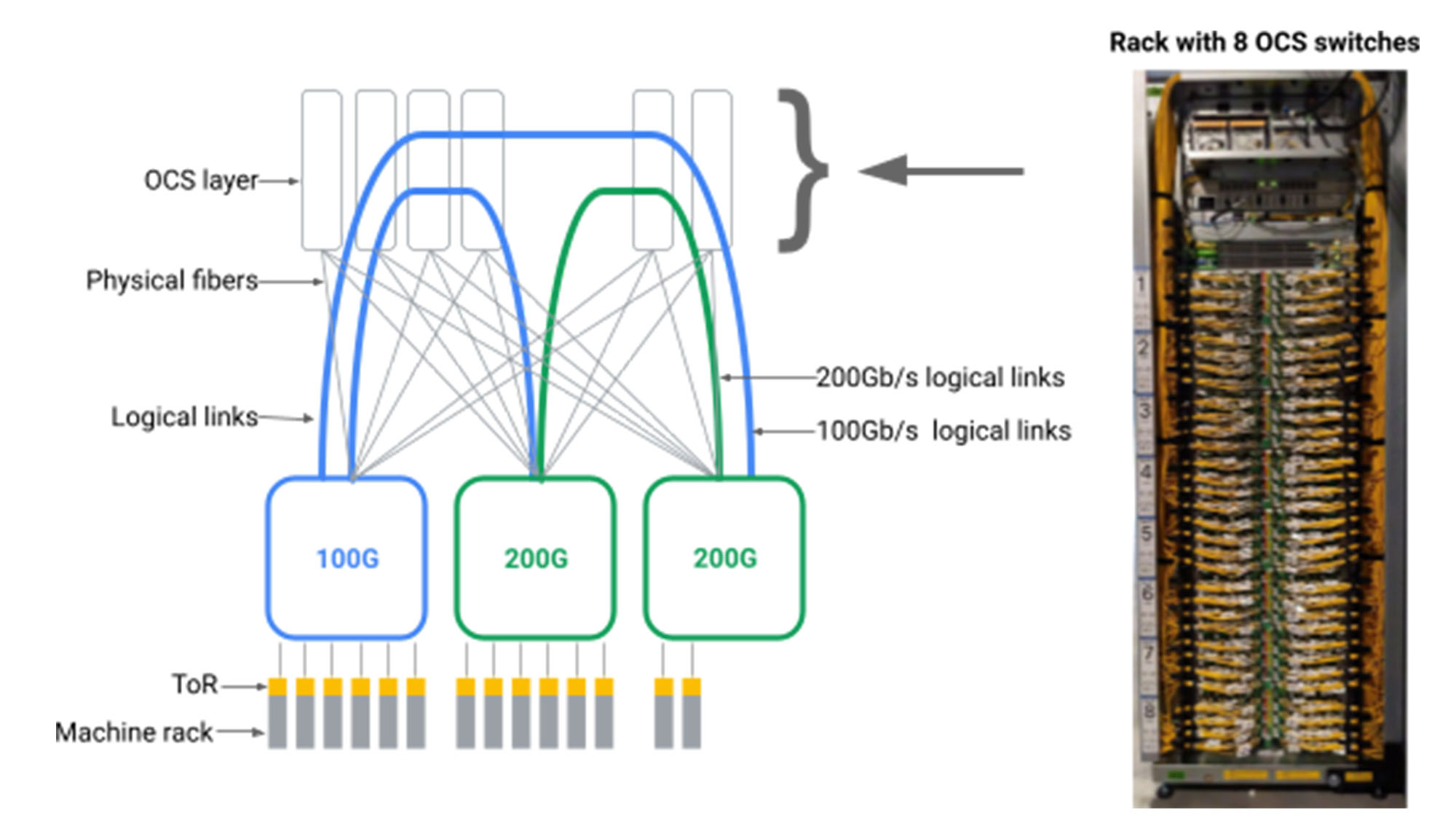
Figa. Bloki agregacyjne fizycznie podłączone za pomocą włókien do przełączników OCS. .
W ten sposób wymagało od nas budowania OCS i natywnych transceiverów WDM o poziomach skali, możliwości produkcji, programowalności i niezawodności nigdy wcześniej nie osiągnięte. Podczas gdy badania akademickie badały korzyści płynące z przełączników optycznych, konwencjonalna mądrość sugerowała, że technologia OCS nie była opłacalna komercyjnie. Przez wiele lat zaprojektowaliśmy i zbudowaliśmy Apollo OCS To teraz stanowi podstawę dla zdecydowanej większości naszych sieci centrów danych.
Jedną istotną zaletą OCS jest to, że w jego działaniu nie biorą udział. OCS po prostu odbija światło z portu wejściowego do portu wyjściowego z niesamowitą precyzją i niewielką stratą. Światło jest generowane poprzez konwersję elektrooptyczną w transceiverach WDM już wymaganych do niezawodnego i wydajnego przesyłania danych w budynkach centrów danych. Stąd OCS staje się częścią Infrastruktura budowlana, jest agnostyka prędkości danych i długości fali i nie wymaga aktualizacji, nawet gdy infrastruktura elektryczna przenosi się z szybkości transmisji i kodowania 40 GB/s do 100 GB/s do 200 GB/s – i nie tylko.
Z warstwą OCS wyeliminowaliśmy warstwę kręgosłupa z naszych sieci centrów danych, zamiast tego łącząc heterogeniczne bloki agregacji w bezpośredniej siatce, po raz pierwszy wykraczając poza topologie Clos w centrum danych. Stworzyliśmy dynamiczne logiczne topologie, które odzwierciedlały zarówno pojemność fizyczną, jak i wzorce komunikacji aplikacji. Ponowna konfiguracja łączności logicznej obserwowanej przez przełączniki w naszej sieci jest teraz standardową procedurą operacyjną, dynamicznie ewoluując topologię z jednego wzorca do drugiego bez wpływu na aplikację. Zrobiliśmy to, koordynując dreny linków z oprogramowaniem routingowym i rekonfiguracją OCS, polegając na naszym oprogramowaniu Orion zdefiniowanym przez płaszczyznę sterowania sieciowego, aby płynnie zorganizować tysiące operacji zależnych i niezależnych.
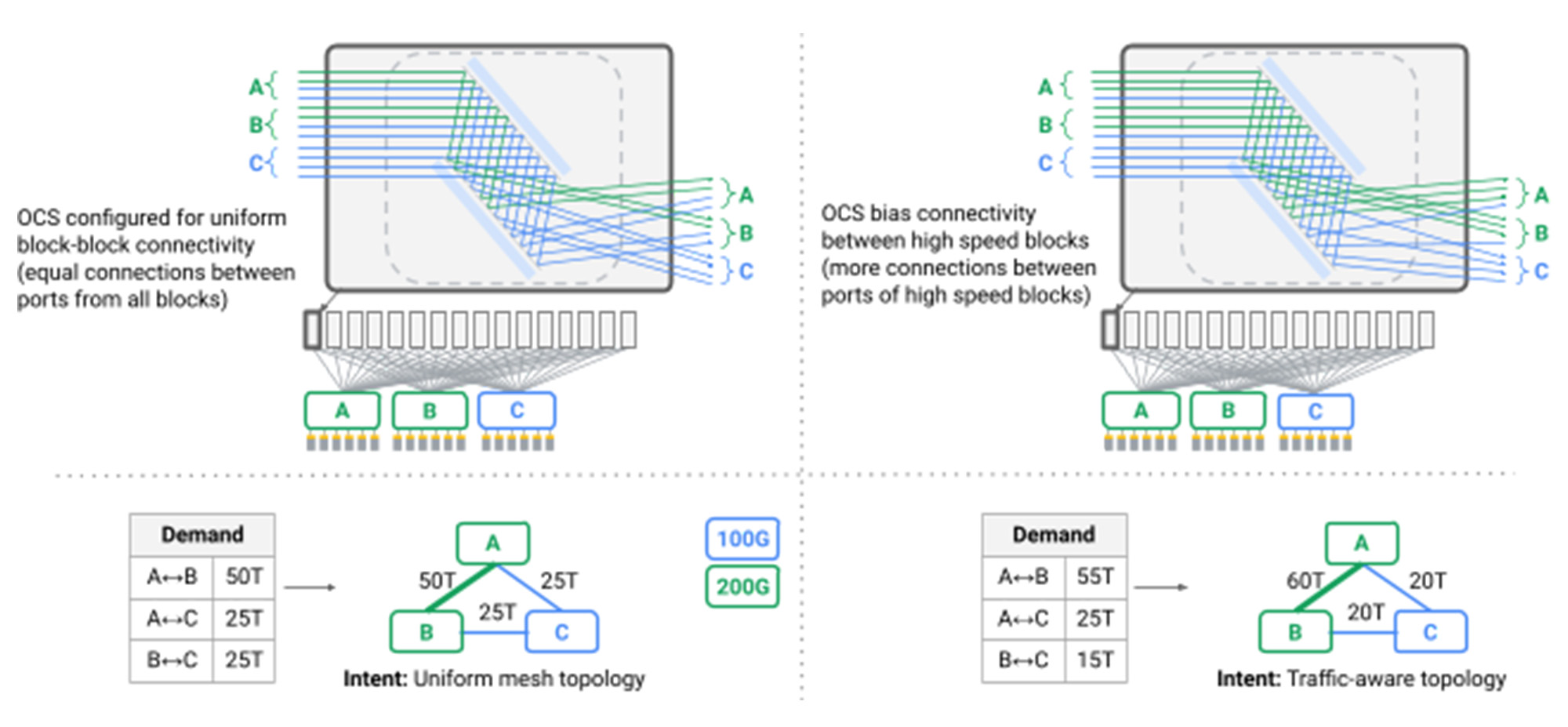
Figa. Wiele OC osiągając inżynierię topologiczną
Szczególnie interesującym wyzwaniem było to, że po raz pierwszy najkrótsza ścieżka routing przez topologie siatki nie mogło już zapewnić wydajności i odporności wymaganej przez nasze centrum danych. Efektem ubocznym typowych topologii Clow jest to, że chociaż wiele ścieżek jest dostępnych za pośrednictwem sieci, wszystkie z nich mają taką samą długość i pojemność łącza, taką, że nieświadomy rozkład pakietów, lub Dzielny równoważenie obciążenia, zapewnia wystarczającą wydajność. W Jupiter wykorzystujemy naszą płaszczyznę kontrolną SDN, aby wprowadzić dynamikę Inżynieria ruchu, przyjmowanie technik pionierskich dla Google’S B4 WAN: Podzielamy ruch między wieloma najkrótszymi i niekorcjalnymi ścieżkami, obserwując pojemność łącza, wzorce komunikacji w czasie rzeczywistym i indywidualne priorytet aplikacji (czerwone strzałki na poniższym rysunku).
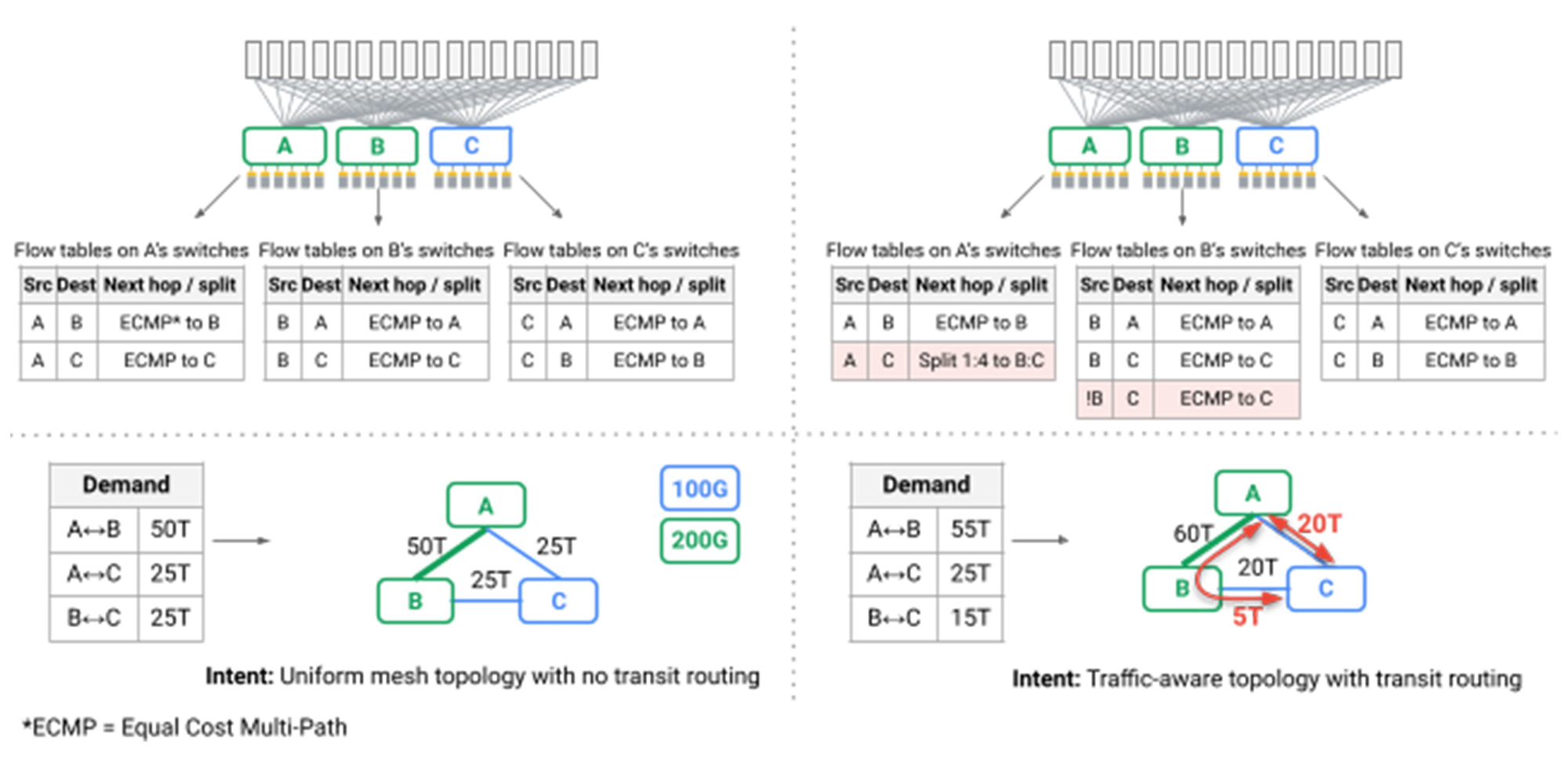
. Tabele przepływu na przełącznikach wykonują inżynierię ruchu
Podsumowując, iteracyjnie ponownie zaprogramowaliśmy sieci centrum danych Jupiter, które napędzają Google’Komputery w skali magazynowej, wprowadzające po drodze szereg pierwszych branży:
- Przełączniki obwodu optycznego jako punkt interoperacyjności sieci w skali budowlanej, płynnie obsługujący heterogeniczne technologie, aktualizacje i wymagania dotyczące usług.
- Bezpośrednie topologie sieciowe dla wyższej wydajności, niższe opóźnienia, niższe koszty i niższe zużycie energii.
- .
- Ulepszenia sieci bezczelnych z zlokalizowanym dodatkiem/usuwaniem pojemności, eliminując potrzebę drogich i trudnych “wszystkie usługi” Ulepszenia stylu, które wcześniej wymagały setek indywidualnych klientów i usług w celu przeniesienia swoich usług w celu przedłużonego budowania przestojów.
Podczas gdy technologia podstawowa jest imponująca, celem końcowym naszej pracy jest dalsze dostarczanie wydajności, wydajności i niezawodności, które razem zapewniają transformacyjne możliwości dla najbardziej wymagających usług rozproszonych zasilających Google i Google Cloud. Jak wspomniano powyżej, nasza sieć Jupiter zużywa o 40% mniej energii, ponosi o 30% mniej kosztów i zapewnia 50 razy mniej przestojów niż najlepsze alternatywy, o których jesteśmy świadomi, jednocześnie zmniejszając zakończenie przepływu o 10% i poprawiając przepustowość o 30%. Z dumą dzielimy się szczegółami tego technologicznego wyczynu w Sigcomm i czekamy na omówienie naszych ustaleń ze społecznością.
Gratulacje i dziękuję niezliczonym Googlerom, którzy codziennie pracują nad Jowiszem i autorom tych najnowszych badań: Leon Poutievski, Omid Mashayekhi, Joon Ong, Arjun Singh, Mukarram Tariq, Rui Wang, Jianan Zhang, Virginia Beauregarard, Patrick Conner, Steve Gribble, Rishi Kapoor, Stephen Kratzer, Nanfang Li, Karthik Nagaraj, Jason Ornstein, Samir Sawhney, Ryohei Urata, Lorenzo Vicisano, Kevin Yasumura, Shidong Zhang, Junlan Zhou, Amin Vahdat.
1. Blok agregacji zawiera zestaw komputerów (komputer/magazyn/akcelerator), w tym przełączniki górnej (TOR) podłączone warstwą typowo zlokalizowanych przełączników.

