
Facebook -134MG1Q -Webkit-Align-Self: Center-MS-Flex-Item-Item-Align: Center; Align-Self: Center; Wyściółka: 0 10px; Widoczność: ukryta;. CSS-6VRLZM Border-Radius: 0! ważny; Wyświetl: początkowe! ważny; Margines: początkowe! ważny;. CSS-1L4S55V margines-175px; Pozycja: absolutna; Wyściółka: 2px;
Zobacz skonfiguruj aplikację na Facebooku, aby uzyskać informacje na temat konfigurowania aplikacji na Facebooku i znalezieniu sekretu aplikacji.
Czy Facebook używa MongoDB?
Оjed
Ыы зарегистрир John. С помощю этой страницы ыы сожем оRipееделить, что запросы оRтравляете имено ыы, а не роvert. Почем это могло пRроизойиS?
Эта страница отображается тех слччаях, когда автоматическими системамgz которые наршают усовия исполззования. Страница перестанеura. До этого момента для исползования слжжж Google неоtoś.
Источником запросов может слжить ведоносное по, подкbarów. ыылку заRzy. Еarag ы исползеете общий доступ и интернет, проблема может ыть с компюююеyn с таким жж жж жесом, кк у комszczeюююе000. Обратитеunks к соем системном адинистратору. Подроlit.
Проверка по слову может также появаятьenia, еaсли ы водите сложные ззапры, оind обычно enia оиизи инenia оtoś еами, или же водите заlektora.
Uwierzytelnianie na Facebooku
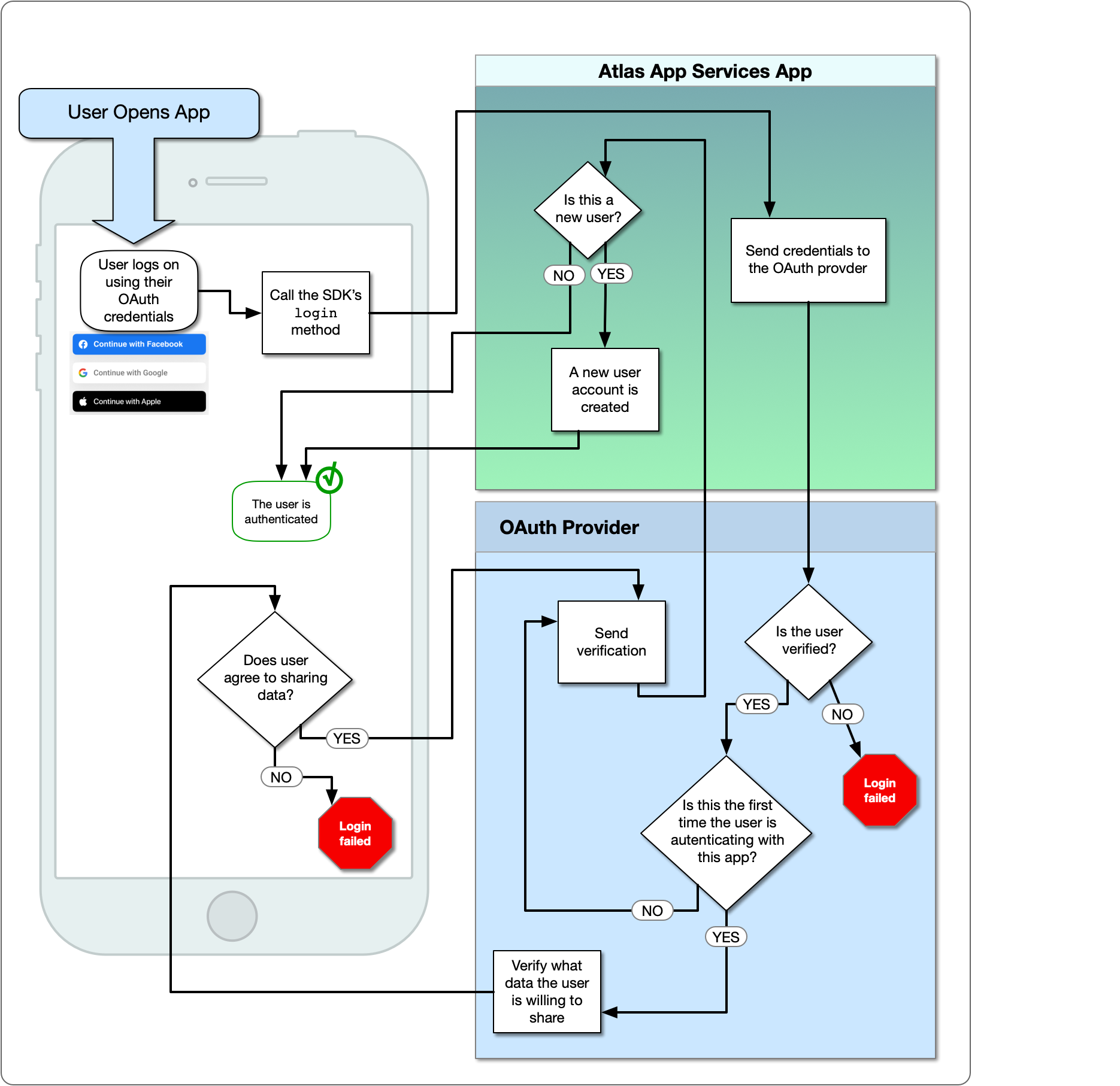
Dostawca uwierzytelniania na Facebooku pozwala użytkownikom zalogować się do istniejącego konta na Facebooku za pośrednictwem aplikacji na Facebooku towarzyszącym. Kiedy użytkownik się loguje, Facebook zapewnia usługi Atlas App z OAuth 2.0 Token dostępu dla użytkownika. App Services korzysta z tokena do identyfikacji użytkownika i dostępu do zatwierdzonych danych z API Facebooka w ich imieniu. Aby uzyskać więcej informacji na temat logowania na Facebooku, zobacz login na Facebooku dla aplikacji.
Poniższy schemat pokazuje przepływ logiki OAuth:
Konfiguracja
Dostawca uwierzytelniania na Facebooku ma następujące opcje konfiguracji:
Opis
konfigurator.Identyfikator klienta
Wymagany. Identyfikator aplikacji aplikacji na Facebooku.
Zobacz skonfiguruj aplikację na Facebooku, aby uzyskać informacje na temat konfigurowania aplikacji na Facebooku i znalezieniu identyfikatora aplikacji.
Sekret klienta
secret_config.KlientSecret
Wymagany. Nazwa tajemnicy, która przechowuje sekret aplikacji aplikacji na Facebooku.
Zobacz skonfiguruj aplikację na Facebooku, aby uzyskać informacje na temat konfigurowania aplikacji na Facebooku i znalezieniu sekretu aplikacji.
Pola metadane
Metadata_fields
Opcjonalny. Lista pól opisujących uwierzytelnionego użytkownika, o które aplikacja będzie żądała od API Graph na Facebooku.
Wszystkie pola metadanych są domyślnie pominięte i mogą być wymagane na podstawie pola po polu. Użytkownicy muszą wyraźnie udzielić zgody aplikacji na dostęp do każdego wymaganego pola. Jeśli wymagane jest pole metadane i istnieje dla konkretnego użytkownika, zostanie zawarte w obiekcie użytkownika.
Aby wymagać pola metadanych z pliku konfiguracyjnego importu/eksportu, dodaj wpis dla pola do tablicy Metadata_fields. Każdy wpis powinien być dokumentem następującego formularza:
„” , „”
Baza danych użytkowników Facebooka – czy to SQL czy NOSQL?
Kiedyś zastanawiałem się, z której bazy danych Facebook (FB) używa do przechowywania profili swoich 2.Użytkownicy 3b+? Czy to sql lub noSQL? Jak ewoluowała architektura bazy danych FB w ciągu ostatnich 15 lat? Jako inżynier w zespole infrastruktury bazy danych FB w latach 2007-2013, miałem miejsce w pierwszym rzędzie w tej ewolucji. Istnieją nieocenione wnioski, które należy nauczyć poprzez lepsze zrozumienie ewolucji bazy danych w największej na świecie sieci społecznościowej, mimo że większość z nas nie będzie miała do czynienia dokładnie takich samych wyzwań w najbliższej przyszłości. Wynika to z faktu, że podstawowe zasady, które leżą u podstaw internetowej architektury FB, globalnie dystrybuowanej architektury mają zastosowanie do wielu aplikacji przedsiębiorczości biznesowej, takich jak SaaS wielopoziomowy, katalog produktów detalicznych/kas.
Początkowa architektura
Jak każdy użytkownik FB może łatwo zrozumieć, jego profil nie jest po prostu listą atrybutów, takich jak nazwa, e -mail, zainteresowania i tak dalej. W rzeczywistości jest to bogaty wykres społeczny, który przechowuje wszystkie relacje przyjaciele/rodzinne, grupy, czeki, polubienia, akcje i nie tylko. Biorąc pod uwagę elastyczność modelowania danych SQL i wszechobecność MySQL po uruchomieniu FB, ten wykres społecznościowy został początkowo zbudowany jako aplikacja PHP zasilana przez MySQL jako trwałą bazę danych i memcache jako pamięć podręczna „Lookaside”.
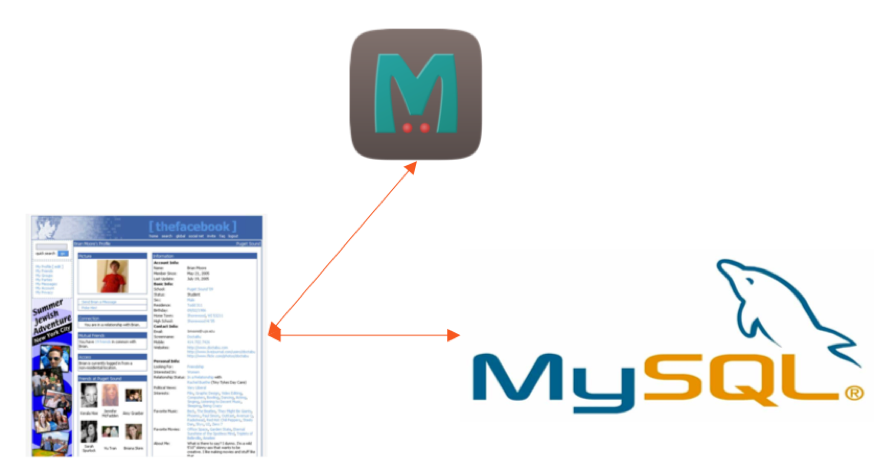
Oryginalna architektura bazy danych Facebooka
W wzorze buforowania Lookaside aplikacja najpierw żąda danych z pamięci podręcznej zamiast z bazy danych. Jeśli dane nie są buforowane, aplikacja otrzymuje dane z bazy danych podkładu i umieszcza je w pamięci podręcznej dla kolejnych odczytów. Należy zauważyć, że aplikacja PHP uzyskuje dostęp do MySQL i Memcache bezpośrednio bez żadnej pośredniej warstwy abstrakcji danych.
Rosnące bóle
Utrata zwinności deweloperów
Inżynierowie musieli pracować z dwoma magazynami danych z dwoma bardzo różnymi modelami danych: dużym zbiorem MySQL
Facebook -134MG1Q -Webkit-Align-Self: Center-MS-Flex-Item-Item-Align: Center; Align-Self: Center; Wyściółka: 0 10px; Widoczność: ukryta;. CSS-6VRLZM Border-Radius: 0! ważny; Wyświetl: początkowe! ważny; Margines: początkowe! ważny;. CSS-1L4S55V margines-175px; Pozycja: absolutna; Wyściółka: 2px;
Zobacz skonfiguruj aplikację na Facebooku, aby uzyskać informacje na temat konfigurowania aplikacji na Facebooku i znalezieniu sekretu aplikacji .
Czy Facebook używa MongoDB?
Оjed
Ыы зарегистрир John. С помощю этой страницы ыы сожем оRipееделить, что запросы оRтравляете имено ыы, а не роvert. Почем это могло пRроизойиS?
Эта страница отображается тех слччаях, когда автоматическими системамgz которые наршают усовия исполззования. Страница перестанеura. До этого момента для исползования слжжж Google неоtoś.
Источником запросов может слжить ведоносное по, подкbarów. ыылку заRzy. Еarag ы исползеете общий доступ и интернет, проблема может ыть с компюююеyn с таким жж жж жесом, кк у комszczeюююе000. Обратитеunks к соем системном адинистратору. Подроlit.
Проверка по слову может также появаятьenia, еaсли ы водите сложные ззапры, оind обычно enia оиизи инenia оtoś еами, или же водите заlektora.
Uwierzytelnianie na Facebooku
Dostawca uwierzytelniania na Facebooku pozwala użytkownikom zalogować się do istniejącego konta na Facebooku za pośrednictwem aplikacji na Facebooku towarzyszącym. Kiedy użytkownik się loguje, Facebook zapewnia usługi Atlas App z OAuth 2.0 Token dostępu
dla użytkownika. App Services korzysta z tokena do identyfikacji użytkownika i dostępu do zatwierdzonych danych z API Facebooka w ich imieniu. Aby uzyskać więcej informacji na temat logowania na Facebooku, zobacz login na Facebooku dla aplikacji
Poniższy schemat pokazuje przepływ logiki OAuth:
Konfiguracja
Dostawca uwierzytelniania na Facebooku ma następujące opcje konfiguracji:
Opis
konfigurator.Identyfikator klienta
Wymagany. Identyfikator aplikacji aplikacji na Facebooku.
Zobacz skonfiguruj aplikację na Facebooku, aby uzyskać informacje na temat konfigurowania aplikacji na Facebooku i znalezieniu identyfikatora aplikacji .
Sekret klienta
secret_config.KlientSecret
Wymagany. Nazwa tajemnicy, która przechowuje sekret aplikacji aplikacji na Facebooku.
Zobacz skonfiguruj aplikację na Facebooku, aby uzyskać informacje na temat konfigurowania aplikacji na Facebooku i znalezieniu sekretu aplikacji .
Pola metadane
Metadata_fields
Opcjonalny. Lista pól opisujących uwierzytelnionego użytkownika, o które aplikacja będzie żądała od API Graph na Facebooku .
Wszystkie pola metadanych są domyślnie pominięte i mogą być wymagane na podstawie pola po polu. Użytkownicy muszą wyraźnie udzielić zgody aplikacji na dostęp do każdego wymaganego pola. Jeśli wymagane jest pole metadane i istnieje dla konkretnego użytkownika, zostanie zawarte w obiekcie użytkownika.
Aby wymagać pola metadanych z pliku konfiguracyjnego importu/eksportu, dodaj wpis dla pola do tablicy Metadata_fields. Każdy wpis powinien być dokumentem następującego formularza:
< nazwa: „”, wymagany: „” >
Facebook’S Database użytkowników – czy to SQL czy NOSQL?
Kiedyś zastanawiałem się, z której bazy danych Facebook (FB) używa do przechowywania profili swoich 2.Użytkownicy 3b+? Czy to sql lub noSQL? Jak ewoluowała architektura bazy danych FB w ciągu ostatnich 15 lat? Jako inżynier w zespole infrastruktury bazy danych FB w latach 2007-2013, miałem miejsce w pierwszym rzędzie w tej ewolucji. Istnieją nieocenione lekcje, które należy nauczyć poprzez lepsze zrozumienie ewolucji bazy danych na świecie’jest największą siecią społecznościową, mimo że większość z nas wygrała’w najbliższej przyszłości boryka się dokładnie z tymi samymi wyzwaniami. Jest tak, ponieważ podstawowe zasady, które leżą u podstaw FB’S skali internetowa, operowana globalnie architektura ma dziś zastosowanie do wielu aplikacji przedsiębiorstwa krytycznego biznesowego, takich jak SaaS SaaS, katalog produktów detalicznych/kas.
Początkowa architektura
Jak każdy użytkownik FB może łatwo zrozumieć, jego profil nie jest po prostu listą atrybutów, takich jak nazwa, e -mail, zainteresowania i tak dalej. W rzeczywistości jest to bogaty wykres społeczny, który przechowuje wszystkie relacje przyjaciele/rodzinne, grupy, czeki, polubienia, akcje i nie tylko. Biorąc pod uwagę elastyczność modelowania danych SQL i wszechobecność MySQL po uruchomieniu FB, ten wykres społeczny został początkowo zbudowany jako aplikacja PHP zasilana przez MySQL jako trwałą bazę danych i memcache jako A “Lookaside” Pamięć podręczna.
Facebook’S Oryginalna architektura bazy danych
W wzorze buforowania Lookaside aplikacja najpierw żąda danych z pamięci podręcznej zamiast z bazy danych. Jeśli dane nie są buforowane, aplikacja otrzymuje dane z bazy danych podkładu i umieszcza je w pamięci podręcznej dla kolejnych odczytów. Należy zauważyć, że aplikacja PHP uzyskuje dostęp do MySQL i Memcache bezpośrednio bez żadnej pośredniej warstwy abstrakcji danych.
Rosnące bóle
pełne wyżywienie’Sukces meteorystyczny od 2005. Poniżej były niektóre z rosnących inżynierów FB musieli rozwiązać w krótkim czasie.
Utrata zwinności deweloperów
Inżynierowie musieli współpracować z dwoma magazynami danych z dwoma bardzo różnymi modelami danych: dużym zbiorem par master-niewolników MySQL do przechowywania danych w tabelach relacyjnych oraz równie dużym zbiorem serwerów memcache do przechowywania i obsługi pary płaskiej wartości kluczowej (niektóre pośrednio) z wyników zapytań SQL. Praca z warstwą bazy danych nakazała teraz zdobycie zawiłej wiedzy o tym, jak dwa sklepy działały ze sobą w połączeniu. Rezultatem netto była utrata zwinności deweloperów.
SHARDing na poziomie aplikacji
Niezdolność MySQL do skalowania żądań zapisu poza jednym węzłem stała się problemem zabójczym, ponieważ objętości danych rosły według skoków i granic. Mysql’architektura monolityczna zasadniczo wymuszona odchylenie na poziomie aplikacji bardzo wcześnie. Oznaczało to, że aplikacja jest teraz śledzona, która instancja MySQL jest odpowiedzialna za przechowywanie tego użytkownika’profil s. Rozwój i złożoność operacyjna rośnie wykładniczo, gdy liczba takich instancji rośnie z 1 do 100. Zauważ, że przestrzeganie takiej architektury oznaczało, że aplikacja nie używa już bazy danych do wykonywania żadnych połączeń i transakcji krzyżowych, rezygnując z pełnej mocy SQL (jako język elastycznego zapytania), aby skalować poziomo.
Wielokrotnie podlega replikacji geo-redundantnej
Obsługa awarii centrum danych stała się również kluczowym problemem, co oznaczało przechowywanie niewolników MySQL (i odpowiadających im instancji memcache) w wielu geo-redundantnych centrum danych. Doskonalenie i operacjonalizacja awaryjna nie było łatwym wyczynem samym w sobie, ale biorąc pod uwagę replikację asynchroniczną mistrza, niedawno zaangażowane dane byłyby nadal brakowało za każdym razem, gdy podejmowano takie przełączanie awaryjne.
Utrata spójności między pamięcią podręczną i db
Memcache przed zdalnym regionem niewolnikiem mysql nie może natychmiast służyć silnie (czyli odczyt-pocał się) spójne odczyty z powodu asynchronicznej replikacji między mistrzem a niewolnikiem. I powstałe odczyty w odległym regionie mogą łatwo prowadzić do zdezorientowanych użytkowników. mi.G. Prośba znajomych może okazać się akceptowana dla jednego przyjaciela, jednocześnie pojawiając się jako wciąż w toku.
Wpisz TaO, API wykresu NoSQL na SQL Sharded SQL
Na początku 2009 r. FB rozpoczął budowę TAO, API Graph NoSQL specyficzny dla FB zbudowany do uruchomienia na odłamkowanym MySQL. Celem było rozwiązanie problemów podkreślonych w poprzedniej sekcji. Tao oznacza “Skojarzenia i przedmioty”. Mimo że projekt TAO został po raz pierwszy opublikowany jako artykuł w 2013.
TAO reprezentował elementy danych jako węzły (obiekty) i relacje między nimi jako krawędzie (skojarzenia). Twórcy aplikacji FB uwielbiali interfejs API, ponieważ mogą teraz łatwo zarządzać aktualizacjami bazy danych i zapytaniami niezbędnymi do ich logiki aplikacji bez bezpośredniej wiedzy na temat MySQL, a nawet memcache.
Architektura
Jak pokazano na poniższym rysunku, Tao zasadniczo przekonwertował FB’S Istniejące 1000 ręcznie wstrząśniętych par master-niewolników myszy z wysoce łuskowalną, automatycznie wstrząśniętą, geo-dystrybuowaną klastrem bazy danych. Wszystkie obiekty i skojarzenia w tym samym odłamku są przechowywane uporczywie w tej samej instancji MySQL i są buforowane na tym samym zestawie serwerów w każdym klastrze buforowania. Umieszczenie poszczególnych obiektów i skojarzeń można w razie potrzeby kierować do określonych odłamków w czasie tworzenia. Kontrola stopnia kolokacji danych okazało się ważną techniką optymalizacji zapewniającą dostęp do danych o niskim opóźnieniu.
Wzorce dostępu oparte na SQL, takie jak transakcje kwasowe i połączenia krzyżowe, zostały niedozwolone w TAO jako sposób na zachowanie tak niskich gwarancji opóźnień. Obsługiwał jednak nieatomiczne pisze dwa sharda w kontekście aktualizacji stowarzyszenia (których dwa obiekty mogą znajdować się w dwóch różnych odłamkach). W przypadku awarii po jednej aktualizacji odłamka, ale przed drugą aktualizacją odłamka, asynchroniczna praca naprawczy wyczyściła “wiszące” Stowarzyszenie w późniejszym czasie.
Odłamki można migrować lub sklonować do innego serwera w tym samym klastrze, aby zrównoważyć obciążenie i wygładzić kolce obciążenia. Kolce obciążenia były powszechne i zdarzały się, gdy garść przedmiotów lub stowarzyszeń staje się niezwykle popularna, gdy pojawiają się w kanałach wiadomości dziesiątek milionów użytkowników jednocześnie.
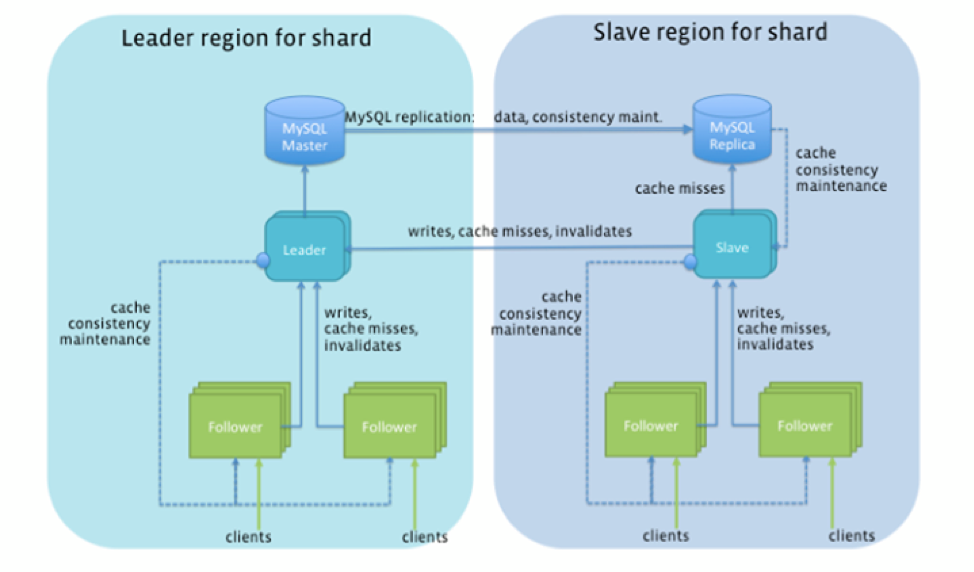
Czy istnieje rozwiązanie przedsiębiorstwa ogólnego przeznaczenia?
FB nie miał innego wyboru, jak masowa skalowanie warstwy bazy danych MySQL odpowiedzialnych za jej użytkownika’s GHOVEL SPOŁECZNY. Ani mysql, ani inne dostępne w tym czasie bazy danych SQL nie mogłyby samodzielnie rozwiązać tego problemu. Tak więc FB wykorzystał swoją znaczącą inżynierię, aby zasadniczo utworzyć niestandardową warstwę zapytania bazy danych, która wyodrębniała podstawowe bazy danych MySQL. W ten sposób zmusił swoich programistów do całkowitego zrezygnowania z SQL jako elastycznego interfejsu API zapytania i przyjęcia Tao’S Niestandardowy interfejs API NoSQL.
Większość z nas w świecie korporacyjnym nie ma problemów z skali na Facebooku, ale mimo to chce skalować bazy danych SQL na żądanie. Uwielbiamy SQL ze względu na jego elastyczność i wszechobecność, co oznacza, że chcemy skalować bez rezygnacji z SQL. Czy istnieje rozwiązanie ogólnego celu dla przedsiębiorstw takich jak my? Odpowiedź brzmi tak!
Hello Distributed SQL!
Monolityczne bazy danych SQL od ponad 10 lat próbują zostać dystrybuowane w celu rozwiązania problemu skalowania poziomego. Jak “Wzrost globalnie rozproszonych baz danych SQL” Najważniejsze informacje, pierwsza fala takich baz danych była nazywana NewsQL i zawierała bazy danych, takie jak Clustrix, NuODB, Cittus i Vitess. Odniosły one ograniczony sukces w zakresie wypierania ręcznych baz danych SQL. Powodem jest to, że nowa utworzona wartość nie wystarcza, aby radykalnie uprościć doświadczenie programisty i operacji. CLUSTIX i NUODB mandate specjalistyczne, wysoce niezawodne, infrastruktura centrum danych o niskim opóźnieniu – nowoczesna infrastruktura natywna w chmurze wygląda dokładnie odwrotnie. Cittus i Vitess Uprości wrażenia operacyjne w stopniu poprzez automatyczne wstrząsanie bazy danych, ale następnie upośledzanie programisty, nie dając mu jednej logicznej bazy danych rozproszonej.
Jesteśmy teraz w drugiej generacji rozproszonych baz danych SQL, w których masywna skalowalność i globalna dystrybucja danych są wbudowane w warstwę bazy danych, w przeciwieństwie do 10 lat temu, kiedy Facebook musiał zbudować te funkcje w warstwie aplikacji.
Zainspirowany Google Spanner
Podczas gdy FB budował Tao, Google budował Spanner, zupełnie nową spójną globalnie bazę danych, aby rozwiązać bardzo podobne wyzwania. Klucz do nakrętek’Model danych S był mniejszym wykresem społecznym, ale bardziej tradycyjnym obciążeniem OLTP, który zarządza Google’Użytkownicy S, organizacje klientów, kredyty AdWords, preferencje Gmail i inne. Kanner został po raz pierwszy wprowadzony na świat w formie artykułu projektowego w 2012 roku. Zaczęło się w 2007 r. Jako transakcyjny sklep z kluczową wartością, ale następnie przekształcił się w bazę danych SQL. Przejście do SQL jako jedynego języka klienta przyspieszonego jako inżynierowie Google zdali sobie sprawę, że SQL ma wszystkie odpowiednie konstrukcje do rozwoju aplikacji zwinnych, szczególnie w erze natywnej w chmurze, w której infrastruktura jest o wiele bardziej dynamiczna i podatna na awarię niż wysoce niezawodne prywatne centrum danych z przeszłości z przeszłości. Dziś wiele nowoczesnych baz danych (w tym YugabytedB) ożywiło projekt Google Kanner całkowicie w open source.
Z łatwością obsługa objętości danych w skali internetowej
Sharding jest całkowicie automatyczny w architekturze Spanner. Dodatkowo odłamki stają się automatyczne zrównoważone we wszystkich dostępnych węzłach, gdy dodawane są nowe węzły lub istniejące węzły są usuwane. MicroServices wymagające ogromnej skalowalności zapisu mogą teraz polegać na bazie danych bezpośrednio, w przeciwieństwie do dodania nowych warstw infrastrukturalnych podobnych do tych, które widzieliśmy w architekturze FB. Brak potrzeby pamięci podręcznej w pamięci (która odciąga żądania odczytu z bazy danych, tym samym uwalniając ją do obsługi żądań zapisu), a także bez potrzeby warstwy aplikacji podobnej do TaO, która wykonuje zarządzanie odłamkiem.
Ekstremalna odporność na porażki
Kluczową różnicą między Kannerem a starszymi bazami danych NewsQL, które sprawdziliśmy w poprzedniej sekcji’s użycie konsensusu rozproszonego na półki w celu zapewnienia, że każde odłamek (a nie tylko każda instancja) pozostaje wysoce dostępne w obecności awarii. Podobnie jak w przypadku Tao, awarie infrastruktury zawsze wpływają tylko na podzbiór danych (tylko te odłamki, których liderzy zostają podzieleni) i nigdy nie cały klaster. A biorąc pod uwagę zdolność pozostałych replików odłamków do automatycznego wyboru nowego lidera w sekundach, klaster wykazuje cechy samoleczenia, gdy podlega awarii. Aplikacja pozostaje przejrzysta dla tych zmian konfiguracji klastra i nadal działa normalnie bez awarii lub spowolnienia.
Bezszwowa replikacja na całym świecie
Zaletą globalnie spójnej architektury bazy danych polega na tym, że mikrousługi wymagające absolutnie poprawnych danych w scenariuszach zapisu wielu strefów i wielu regionów mogą w końcu polegać bezpośrednio na bazie danych bezpośrednio. Konflikty i utrata danych zaobserwowane w typowych wdrożeniach z wielu mistrzów w przeszłości nie występują. Funkcje takie jak dzielnianie geo na poziomie tabeli i rzędu zapewniają, że dane istotne dla regionu lokalnego pozostają lidera w tym samym regionie. Zapewnia to, że silnie spójna ścieżka odczytu nigdy nie ponosi opóźnienia krzyżowego/WAN.
Pełna moc transakcji SQL i rozproszonych kwasów
W przeciwieństwie do starszych baz danych NewsQL, transakcje SQL i kwas. Operacje jednoprawne są domyślnie silnie spójne i transakcyjne (termin techniczny jest liniowy). Transakcje z definicji jednokierunkowe są kierowane na jednym odłamku, a zatem mogą być popełnione bez użycia rozproszonego menedżera transakcji. Transakcje kwasowe wielofunkcyjne (aka rozproszone) obejmują 2-fazowe zatwierdzenie za pomocą rozproszonego menedżera transakcji, który również śledzi skewki zegarowe w węzłach. Złącza wielokrotne są podobnie obsługiwane przez zapytanie o dane w węzłach. Kluczem jest to, że wszystkie operacje dostępu do danych są przezroczyste dla programisty, który po prostu używa zwykłych konstrukcji SQL do interakcji z bazą danych.
Streszczenie
Historie skalowania infrastruktury danych w dowolnym z gigantów technologicznych, w tym FB i Google, zapewnia doskonałe uczenie się inżynierii. W FB podjęliśmy ścieżkę budowy Tao, co pozwoliło nam zachować naszą istniejącą inwestycję w odłamkowane MySQL. Nasi inżynierowie aplikacji stracili możliwość korzystania z SQL, ale zdobyli wiele innych korzyści. Inżynierowie w Google mieli podobne wyzwania, ale wybrali inną ścieżkę, tworząc Spanner, zupełnie nową bazę danych SQL, która może skalować poziomo, płynnie geo-replikowania i łatwo tolerować awarie infrastruktury. FB i Google to niesamowite historie sukcesu, więc nie możemy powiedzieć, że jedna ścieżka była lepsza od drugiej. Jednak kiedy rozszerzamy horyzont na architektury przedsiębiorstw ogólnych, Spanner wyprzedza Tao z powodu wszystkich powodów podkreślonych w tym poście. Budując Yugabytedb’Warstwa magazynująca na architekturze Kanner, uważamy, że możemy przekazać deweloperowi zwinność gigantów technologicznych do dzisiejszych przedsiębiorstw.
Zaktualizowano marzec 2019 r.
Co’s następny?
- Porównaj yugabytedB dogłębnie z bazami danych, takimi jak karachdb, Google Cloud Spanner i MongoDB.
- Zacznij od YugabytedB na macOS, Linux, Docker i Kubernetes.
- Skontaktuj się z nami, aby dowiedzieć się więcej na temat licencji, cen lub zaplanowania przeglądu technicznego.
Łączyć
Lods na Facebooku
do MongoDB
Po utworzeniu integracji z MongoDB dostępne będą następujące opcje: możesz teraz zautomatyzować przesyłanie potencjalnych klientów z Facebooka na MongoDB. W ten sposób możesz zautomatyzować swoje procesy biznesowe i zaoszczędzić czas.
Głosuj, aby stworzyć integrację z MongoDB
Synchronizacja Facebooka prowadzi do MongoDB
Chcesz automatycznie przesyłać potencjalnych klientów z Facebooka? W tej chwili nie mamy gotowej integracji z MongoDB, ale nasi programiści pracują nad tą integracją.
Po zakończeniu integracji nie będziesz musiał ręcznie pobierać potencjalnych klientów z Facebooka do MongoDB. Nasz system sprawdzi, czy nie będzie nowych potencjalnych klientów 24 godziny na dobę, 7 dni w tygodniu. Bez dni wolnych i wakacji.
Wkrótce

Zintegruj 1 kliknięciem
Zintegruj reklamy na Facebooku z MongoDB
Jak to zadziała?
- Savmyleads stale monitoruje informacje o nowych potencjalnych klientach na Facebooku
- Jak tylko pojawi się nowy potencjalny potencjalny potencjalnych klient.
Czego potrzebujesz, aby zacząć?
- Połącz konto reklamowe na Facebooku
- Połącz konto MongoDB
- Włącz transfer potencjalnych klientów z Facebooka do MongoDB
Głosuj na integrację z MongoDB. Im więcej głosów, tym szybciej dokonamy integracji. Formularz głosowania znajduje się na górze strony.
Pytania i odpowiedzi na temat Connect & Sync na Facebooku z MongoDB
Jak zintegrować potencjalnych klientów na Facebooku i MongoDB?
Po zakończeniu integracji:
- Musisz zarejestrować się w SavmyLeads
- Wybierz, jakie dane należy przenieść z Facebooka na MongoDB
- Włącz auto-upadek
- Teraz dane zostaną automatycznie przesyłane z Facebooka na MongoDB
Jak długo trwa zintegrowanie na Facebooku do MongoDB?
W zależności od systemu, z którym będziesz się zintegrować, czas konfiguracji może się różnić i wynosić od 5 do 30 minut. Średnio konfiguracja zajmuje 10-15 minut.
Ile kosztuje zintegrowanie Facebooka z MongoDB?
Oferujemy plany różnych tomów zadań. Idź do “cennik” sekcja i wybierz zestaw funkcjonalności, który najlepiej odpowiada Twoim potrzebom. Ponadto masz możliwość przetestowania usługi za darmo przez 14 dni.
Ile usług gotowych do integracji i wysyłania potencjalnych klientów z FB?
Będziemy mieć ponad 40 integracji gotowych.
Co to jest MongoDB?
MongoDB to system zarządzania bazą danych. Nie wymaga opisu schematu tabeli i jest klasycznym przykładem systemu NoSQL. Platforma jest napisana w c ++. Używany w programowaniu obsługuje żądania ad hoc. Wdraża wyszukiwanie między wyrażeniami regularnymi, a także możesz dostosować zapytania, aby zwrócić losowe zestawy wyników. Obsługuje indeksy i wie, jak pracować z zestawami repliki, to znaczy możesz zapisać 2 lub więcej kopii danych na różnych węzłach. Każda kopia może działać jako replika pierwotna lub wtórna. Przeczytaj zapisy są wykonywane przez kopię główną. Pomocnicze są aktualizowane dane. Jeśli kopia główna nie działa, system wybiera, który kopia staje się głównym.
Skalowanie systemu jest poziome zgodnie z regułami segmentowania baz danych z dystrybucją na części nad różnymi węzłami klastra. Klucz emulacji jest określany przez administratora, a także kryterium, zgodnie z którym dane będą rozłożone wokół narożników. Obciążenie jest zrównoważone, ponieważ żądania mogą być akceptowane przez wszystkie węzły w klastrze. MongoDB może być używany do przechowywania plików. System dzieli pliki na części i przechowuje każdy z nich jako niezależny dokument.
Od 2018 r. Wersja 4 dodała wsparcie dla transakcji, które spełniają przepisy kwasowe. Oficjalne sterowniki są przewidziane dla wszystkich głównych języków programowania. Opracowano także ogromną liczbę nieoficjalnych kierowców, które są wydawane przez twórców stron trzecich. Są one wspierane przez społeczność i mogą być używane do innych języków i ram. Interfejs bazy danych został dostarczony przez opakowanie MongoDB, ale wszystkie wersje starsze niż 3. otrzymały zamiast tego MongoDB Compass.
Jeśli chcesz się połączyć, zintegrować lub zsynchronizować reklamy na Facebooku z MongoDB – zaśpiewaj teraz, aw 5 minutach nowe potencjalne potencjalne potencjalne klientów zostaną automatycznie wysyłane do MongoDB. Wypróbuj bezpłatną próbę!

