
Czy Facebook ma własne centra danych?
Streszczenie:
Meta (wcześniej Facebook) ma obecnie 47 centrów danych, z planami posiadania ponad 70 budynków w najbliższej przyszłości. Odzwierciedla to globalną ekspansję infrastruktury firmy, z 18 kampusami centrum danych na całym świecie wynosi 40 milionów stóp kwadratowych. Pomimo wyzwań związanych z zakłóceniami pandemii i łańcucha dostaw, Meta spodziewa się zainwestować od 29 do 34 miliardów dolarów na wydatki inwestycyjne w 2022 r.
Kluczowe punkty:
- Meta ma w budowie 47 centrów danych i planuje ponad 70 budynków w najbliższej przyszłości.
- Firma ma 18 kampusów centrum danych na całym świecie.
- Rozszerzenie podczas zakłóceń łańcucha pandemii i łańcucha dostaw jest trudne.
- Meta spodziewa się zainwestować od 29 miliardów do 34 miliardów dolarów w wydatki inwestycyjne w 2022 r.
- Operatorzy Hyperscale, tacy jak Meta i Microsoft, wlewają miliardy na rozszerzenie infrastruktury centrów danych.
- Open Compute Project, założony przez Facebook, napędza innowacje w sprzęcie.
- Konstrukcja centrum danych wymaga elastycznego wyboru miejsca i procesów budowy.
- Meta uważa dostawców i kontrahentów jako partnerów w prowadzeniu najlepszych praktyk i ciągłego doskonalenia.
- Meta i inni operatorzy hiperskalni są pionierami nowych strategii dostarczania skali i prędkości.
- Skala i wyzwanie programu Centrum danych jest siłą napędową Meta.
Pytania:
- Jaki jest obecny status budowy centrum danych?
- Ile kampusów centrum danych ma meta na całym świecie?
- Jakie wyzwania stoją przed metalem w rozszerzeniu centrum danych?
- Ile Meta planuje inwestować w wydatki inwestycyjne w 2022 r?
- Które firmy inwestują również w ekspansję infrastruktury centrów danych?
- Jaka jest rola projektu otwartego?
- Jakie czynniki są ważne w budowie centrum danych?
- W jaki sposób Meta postrzega dostawców i kontrahentów?
- Jakie strategie to meta i inni operatorzy hiperskalni pionierami?
- Co napędza program centrum danych meta?
Meta ma obecnie 47 centrów danych w budowie, z planami na ponad 70 budynków w najbliższej przyszłości.
Meta ma 18 kampusów centrum danych na całym świecie.
Rozszerzenie centrum danych podczas zakłóceń łańcucha pandemicznego i dostaw stwarza wyzwania dla meta.
Meta spodziewa się zainwestować od 29 miliardów do 34 miliardów dolarów w wydatki inwestycyjne w 2022 r.
Operatorzy Hyperscale, tacy jak Microsoft, inwestują również miliardy w rozszerzenie infrastruktury centrów danych.
Open Compute Project, założony przez Facebook, napędza innowacje w sprzęcie.
Konstrukcja centrum danych wymaga elastycznego wyboru miejsca i procesów budowy.
Meta postrzega dostawców i kontrahentów jako partnerów w prowadzeniu najlepszych praktyk i ciągłego doskonalenia.
Meta i inni operatorzy hiperskalni są pionierami nowych strategii dostarczania skali i prędkości.
Skala i wyzwanie programu Centrum danych jest siłą napędową Meta.
Czy Facebook ma własne centrum danych
Co jeszcze rozebrał się Facebook? Frankovsky powiedział, że „wiele płyt głównych ma wiele zarządzania. To jest techniczny termin, którego lubię do tego używać.„Ten goop może być zintegrowanym silnikiem zarządzania cyklem życia HP lub narzędziami do zarządzania serwerami zdalnego Dell.
Facebook ma w budowie 47 centrów danych
Firma powiedziała, że Meta ma obecnie 47 centrów danych’S cyfrowa infrastruktura.

To’S Krótkie stwierdzenie, głęboko w długiej recenzji innowacji na Facebooku’S cyfrowa infrastruktura. Ale dla każdego, kto zna branżę centrum danych, to’S prawdziwy otwieracz wzroku.
“Jak ja’P Pisanie tego, mamy 48 aktywnych budynków i kolejne 47 budynków w budowie,” powiedział Tom Furlong, prezes infrastruktury, centrów danych w Meta (wcześniej Facebook). “Więc my’w najbliższej przyszłości będzie mieć ponad 70 budynków.”
Oświadczenie odzwierciedla niezwykły zakres meta’S Global Infrastructure Expansation. Firma ma 18 kampusów centrum danych na całym świecie, które po ukończeniu będzie objęte 40 milionów stóp kwadratowych przestrzeni centrum danych.
Posiadanie 47 budynków w budowie byłoby wyzwaniem w każdym okolicznościach, ale szczególnie podczas globalnego zakłócenia pandemicznego i dostaw. To’S nie jest łatwe ani tanie. Meta twierdzi, że spodziewa się zainwestować od 29 do 34 miliardów dolarów w wydatki inwestycyjne w 2022 r., W porównaniu z 19 miliardami dolarów w ubiegłym roku.
To’S nie tylko, ponieważ najwięksi operatorzy hiperskalni wylewają miliardy dolarów na rozszerzenie infrastruktury centrów danych, aby zaspokoić popyt na swoje usługi cyfrowe. Według analizy z Synergy Research Group, która śledzi 19 dostawców hiperskalowych, którzy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy w okresie sześciu miesięcy wydali się, że wydatki kapitałowe Hyperscale wzrosły o 30 procent w pierwszej połowie 2021 r.
Te poziomy wydatków mogą łatwo wzrosnąć, w świetle Facebooka’projekcje S na przyszłe wydatki CAPEX i Microsoft’S planuje zbudować od 50 do 100 centrów danych rocznie.
Innowacje infrastrukturalne w skali epickiej
Furlong’S Post na blogu o meta’Warto czytać w podróży S Data Center, podobnie jak post towarzyszący, który patrzy na postęp projektu Open Compute, otwartej inicjatywy sprzętowej założonej przez Facebook w 2011 roku.
“Otwarte sprzęt napędza innowacje, a praca z większą liczbą dostawców oznacza więcej możliwości opracowania sprzętu nowej generacji w celu wspierania obecnych i pojawiających się funkcji w Meta’rodzina technologii.,” Furlong pisze.
Potrzeba innowacji na skalę ma również budowę centrum danych.
“Obecnie w centrum danych i branżach budowlanych jest wiele aktywności, co wywiera presję na znalezienie odpowiednich witryn i partnerów,” powiedział Furlong. “Oznacza to również, że musimy stworzyć bardziej elastyczne procesy wyboru witryny i budowy. Cały ten wysiłek polega również na tym, że w tym wszystkim patrzy na naszych dostawców i kontrahentów jako partnerów. Możemy’T Zrób to po prostu o dolarach. Musimy zrobić z wydajnością. Musimy zrobić z prowadzeniem najlepszych praktyk i ciągłym doskonaleniem.
“Ale to’nie jest tak, jak zwykle działa przemysł budowlany,” on kontynuował. “Więc my’musiałem wprowadzić wiele naszych własnych pomysłów na temat prowadzenia działalności i wprowadzania ich i zaimponowanie im firmom, z którymi współpracujemy.”
Cyfrowa infrastruktura staje się coraz ważniejsza każdego dnia, a meta i jej hiperskalne odpowiedniki są pionierami nowych strategii, aby zapewnić potrzebną skalę i prędkość, której potrzebują. To’jest trwający proces, jak odzwierciedla Furlong.
“Przeprowadzka na arenę centrum danych nigdy nie będzie łatwa,” on pisze. “Ale myślę, że my’VE skończyło się z niesamowitym programem na skalę, której nigdy nie wyobrażałbym sobie. I my’zawsze proszony o zrobienie więcej. To’jest wyzwaniem biznesowym i to’prawdopodobnie jedna z głównych rzeczy, które sprawiają, że ja i mój zespół przychodzą do pracy każdego dnia. Mamy przed nami to ogromne wyzwanie, aby zrobić coś, co jest niewiarygodnie ogromne na dużą skalę.”
Czy Facebook ma własne centrum danych


Powrót do Blog Home
сен 20 2016
Infrastruktura na Facebooku: Strategia i rozwój centrum danych
Przez meta kariery
Rachel Peterson kieruje zespołem strategii Centrum danych infrastrukturalnych na Facebooku. Jej zespół zarządza portfolio centrum danych Facebooka i zapewnia strategiczne wsparcie w celu zidentyfikowania możliwości dalszego zrównoważonego rozwoju infrastruktury, wydajności i niezawodności. Spójrz na jej doświadczenie na Facebooku i sposób, w jaki jej zespół pracuje nad połączeniem świata.
Jaka jest Twoja historia na Facebooku?
Dołączyłem do Facebooka w 2009 roku, kiedy firma miała zamiar uruchomić swoje pierwsze centrum danych w Prineville w stanie Oregon. W tym czasie cały zespół centrum danych składał się z mniej niż 30 członków zespołu, a Facebook zajmował dwa małe ślady kolokacji w USA. Dołączyłem, aby pomóc w opracowaniu programu selekcji witryn dla własnych centrów danych na Facebooku. Dziś nasz zespół składa się z ponad 100 osób w wielu lokalizacjach na całym świecie.
Szybko do przodu, Facebook jest teraz właścicielem i obsługuje duży portfolio centrów danych, obejmujących USA, Europę i Azję. Program selekcji witryny z powodzeniem uruchomił piętnaście masowych centrów danych i jesteśmy zaangażowani w zasilanie tych centrów danych 100% energii odnawialnej. W 2012 r. Wyznaczyliśmy nasz pierwszy cel 25% czystej i odnawialnej energii w naszym mieszance dostaw energii elektrycznej w 2015 r. Dla wszystkich centrów danych. W 2017 r. Przekroczyliśmy 50% czystej i odnawialnej energii dla wszystkich operacji Facebooka. W 2018 r. Wyznaczyliśmy nasz kolejny agresywny cel – dążąc do spełnienia 100% czystej i odnawialnej energii dla wszystkich rosnących operacji na Facebooku do końca 2020 roku.
To było naprawdę ekscytujące być na czele tego rozwoju i zbudować zespół, który odegrał kluczową rolę w rozwoju infrastruktury Facebooka. W tej niesamowitej podróży nigdy nie było nudnej chwili! Wzrost Facebooka sprawił, że był to zarówno trudne, jak i zabawne, i nie sądzę, że dzień minął, gdzie się nie uczyłem. Uwielbiam to, co robię i mam szczęście pracować z tak niesamowitym, zabawnym zespołem. Kultura Facebooka umożliwia mój zespół do wywarcia dalekosiężnego wpływu, a razem sprawia, że świat jest bardziej otwarty i połączony. jedno centrum danych na raz.

Misją Facebooka jest uczynienie świata bardziej otwartym i powiązanym, jaką rolę odgrywa twój zespół?
Prowadzi globalną strategię lokalizacji Facebooka i wysiłki wyboru witryny w oparciu o szereg krytycznych kryteriów lokalizacji, w tym nową energię odnawialną do obsługi witryn.
Zarządza globalnymi programami zgodności ze środowiskiem na Facebooku, z wyboru witryn w trakcie operacji, w tym zgodności z lotem i wodą.
Prowadzi globalne programy energetyczne na Facebooku, od wyboru witryn w trakcie operacji, optymalizacji dostaw energii dla 100% energii odnawialnej, jednocześnie zapewniając odpowiedzialność podatkową i niezawodność.
Prowadzi planowanie strategiczne, włączanie i monitorowanie globalnej mapy drogowej.
Zapewnia wsparcie nauki danych, aby umożliwić strategiczne decyzje i optymalizację wydajności w cyklu życia centrum danych.
Prowadzi nasze zaangażowanie społeczności w lokalizacjach, w których mamy centra danych.
Opracowuje i zarządza strategiami ograniczania polityki i ryzyka, aby umożliwić globalną ekspansję Facebooka’S ślad infrastruktury.
Facebook jest zaangażowany w bycie siłą na dobre, gdziekolwiek pracujemy, zapewniając pracę, rozwijając gospodarkę i wspierając programy, które przynoszą korzyści społecznościom, w którym żyjemy.
Nasz zespół zrównoważonego rozwoju’S misja to wspieranie Facebooka’zdolność do działania i rozwoju wydajnego i odpowiedzialnego oraz umożliwiania ludziom budowania zrównoważonych społeczności.
Prowadzi strategię całej firmy w zakresie napędzania doskonałości operacyjnej z projektowania, budowy i działania naszej działalności. Priorytetowo traktujemy wydajność, ochronę wody i doskonałość łańcucha dostaw i z dumą stwierdzimy, że nasze obiekty należą do najbardziej wody i energooszczędności na świecie.
Jesteśmy zaangażowani w walkę z zmianami klimatu i ustanowiliśmy cel naukowy, aby zmniejszyć nasze emisje o 75 procent do 2020 r.

Podstawowe wartości Facebooka są szybkie poruszanie się, skupienie się na wpływie, budowanie wartości społecznej, otwarcie, odważne. Która wartość naprawdę rezonuje z Twoim zespołem?
Skoncentruj się na uderzeniu. Nasz zespół jest stosunkowo szczupły, a jednak mamy możliwość dostarczania wielu inicjatyw o dużym wpływie dla firmy.
Co jest czymś, czego większość ludzi nie wie o twoim zespole?
Mamy bardzo zróżnicowany zespół składający się z prawników, menedżerów ds. Polityki publicznej, analityków finansowych, menedżerów programów, naukowców z danych, specjalistów ds. Energii, inżynierów i ekspertów procesów biznesowych.
Czy możesz podzielić się byciem liderem w branży technologicznej i znaczeniu różnorodności na Facebooku i ogólnie technologii?
Jednym z powodów, dla których uwielbiam pracować na Facebooku, jest nasze zaangażowanie w różnorodność. Różnorodność nie jest zajęciem pozalekcyjnym na Facebooku, ale raczej czymś, co staramy się wdrożyć na wszystkich poziomach firmy. Mimo że my i branża technologiczna jako całość mamy tutaj więcej pracy, nieustannie wzmacniamy to zaangażowanie poprzez naszą kulturę, nasze produkty i nasze priorytety rekrutacyjne.
Jako kobieta w technologii wiem z pierwszej ręki, jak ważna jest różnorodność dla naszej branży i jak różnorodne perspektywy zwiększają lepsze wyniki. Niezwykle ważne jest, abyśmy zrobili wszystko, co w naszej mocy, aby poprawić zatrudnienie różnych kandydatów i zachęcić kobiety do dołączenia do sektorów, które są zwykle zdominowane przez mężczyzn. Znalazłem karierę w wyborze witryn nieruchomości, tradycyjnie zdominowanej przez mężczyzn przemysłu, i znalazłem inspirację dzięki wielu utalentowanym kobietom, które inspirowały mnie i mentorowały po drodze. Dzisiaj, jako liderka w dziedzinie technologii, moim obowiązkiem i przywilejem jest być mentorem dla kobiet i robić, co w mojej mocy, aby aktywnie wspierać rozwój i rozwój kobiet w tej branży.
Moja rada dla kobiet? Znajdź swoje pasje i podążaj za nimi, nawet jeśli skończysz w miejscu, w którym ty’normalnie jedyną kobietą w pokoju. Twoje mocne strony rozwiną się przez twoje pasje i ciebie’Pracuj ciężej nad Twoim rzemiosłem. Twoja kariera znajdzie własną trajektorię. Co najważniejsze, pozwól sobie na porażkę, i od razu wrócisz, jeśli potkniesz się po drodze.
Czy Facebook ma własne centrum danych

Facebook’Usługi S opierają się na flotach serwerów w centrach danych na całym świecie – wszystkie uruchomione aplikacje i dostarczające wyniki potrzebne nasze usługi. Właśnie dlatego musimy upewnić się, że nasz sprzęt serwerowy jest niezawodny i że możemy zarządzać niepowodzeniami sprzętu serwera na naszej skali, z jak największym zakłóceniami w naszych usługach.
Same komponenty sprzętowe mogą zawieść z dowolnej liczby powodów, w tym degradacja materiałów (e.G., Mechaniczne elementy wirującego dysku twardego), urządzenie używane poza jego poziomem wytrzymałości (e.G., NAND Flash Urządzenia), wpływ na środowisko (e.G., korozja z powodu wilgotności) i wad produkcyjnych.
Ogólnie rzecz biorąc, zawsze oczekujemy pewnego stopnia awarii sprzętu w naszych centrach danych, dlatego wdrażamy systemy takie jak system zarządzania klastrami, aby zminimalizować przerwy w zakresie usług. W tym artykule’Wprowadzenie czterech ważnych metodologii, które pomagają nam utrzymać wysoki stopień dostępności sprzętu. Zbudowaliśmy systemy, które mogą wykrywać i naprawić problemy . Monitorujemy i naprawiamy zdarzenia sprzętowe bez negatywnego wpływu na wydajność aplikacji . Przyjmujemy proaktywne podejścia do naprawy sprzętu i używamy metodologii prognozowania do napraw . I automatyzujemy analizę głównych przyczyn dla awarii sprzętu i systemu na dużą skalę, aby szybko dotrzeć do dolnej części problemów.
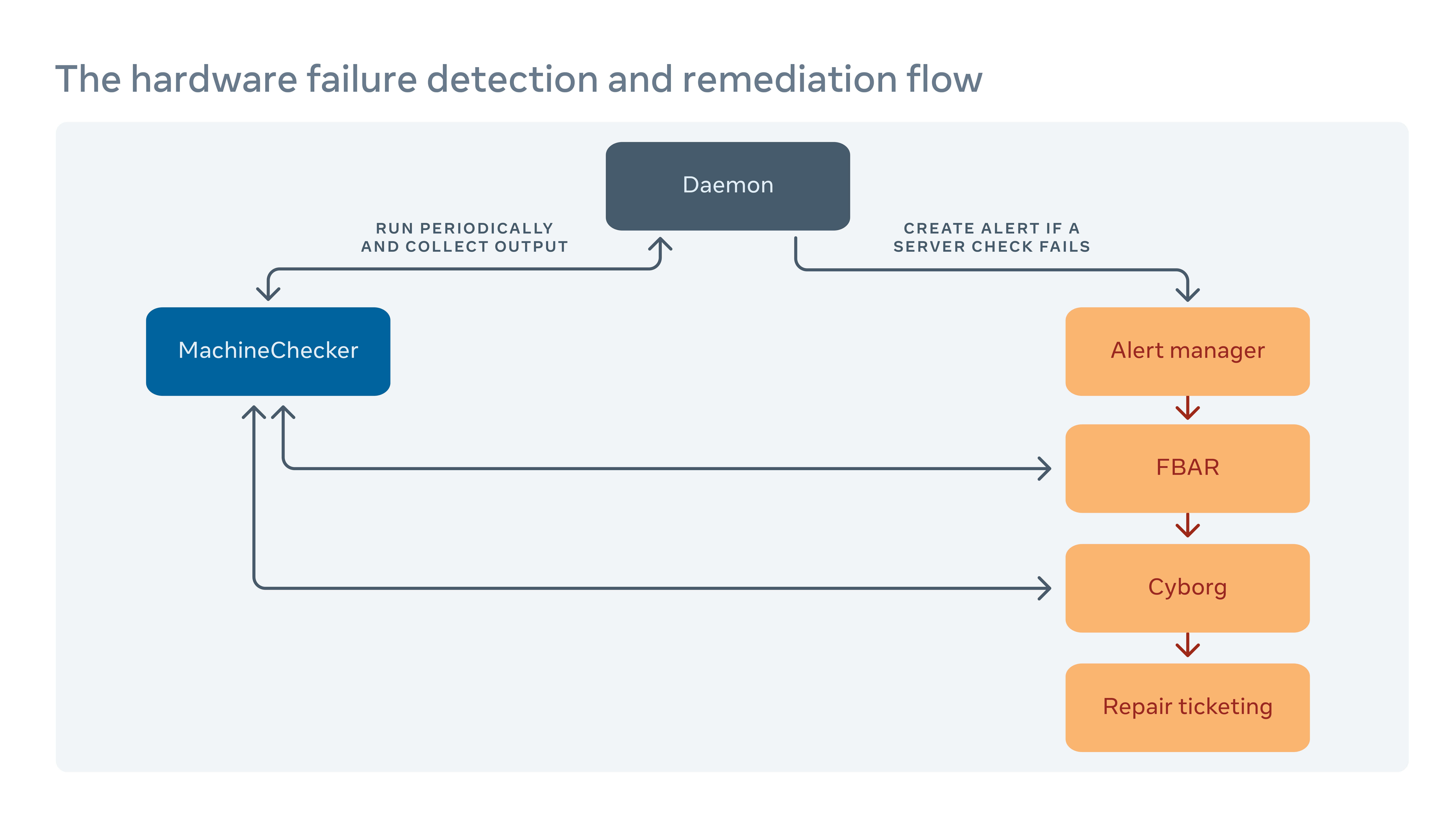
Jak radzimy sobie z naprawą sprzętu
Okresowo uruchamiamy narzędzie o nazwie MachineChecker na każdym serwerze, aby wykryć awarie sprzętu i łączności. Gdy MachineChecker tworzy alert w scentralizowanym systemie obsługi alertów, narzędzie o nazwie Facebook Auto-Remediation (FBAR) następnie podnosi alert i wykonuje konfigurowalne środki do naprawienia błędu. Aby to tam upewnić’S wciąż wystarczająca pojemność na Facebooku’usługi S, możemy również ustalić limity stawek, aby ograniczyć liczbę serwerów naprawianych jednocześnie.
Jeśli FBAR może’T Przywróć serwer do zdrowego stanu, awaria jest przekazywana do narzędzia o nazwie Cyborg. Cyborg może wykonywać środki zaradcze na niższym poziomie, takie jak modernizacje oprogramowania lub jądra, i ponowne ponowne. Jeśli problem wymaga ręcznej naprawy technika, system tworzy bilet w naszym systemie biletów na naprawę.
Zagłębiamy się w ten proces w naszym artykule “Remediacja sprzętowa na dużą skalę.”
Jak minimalizujemy negatywny wpływ raportowania błędów na wydajność serwera
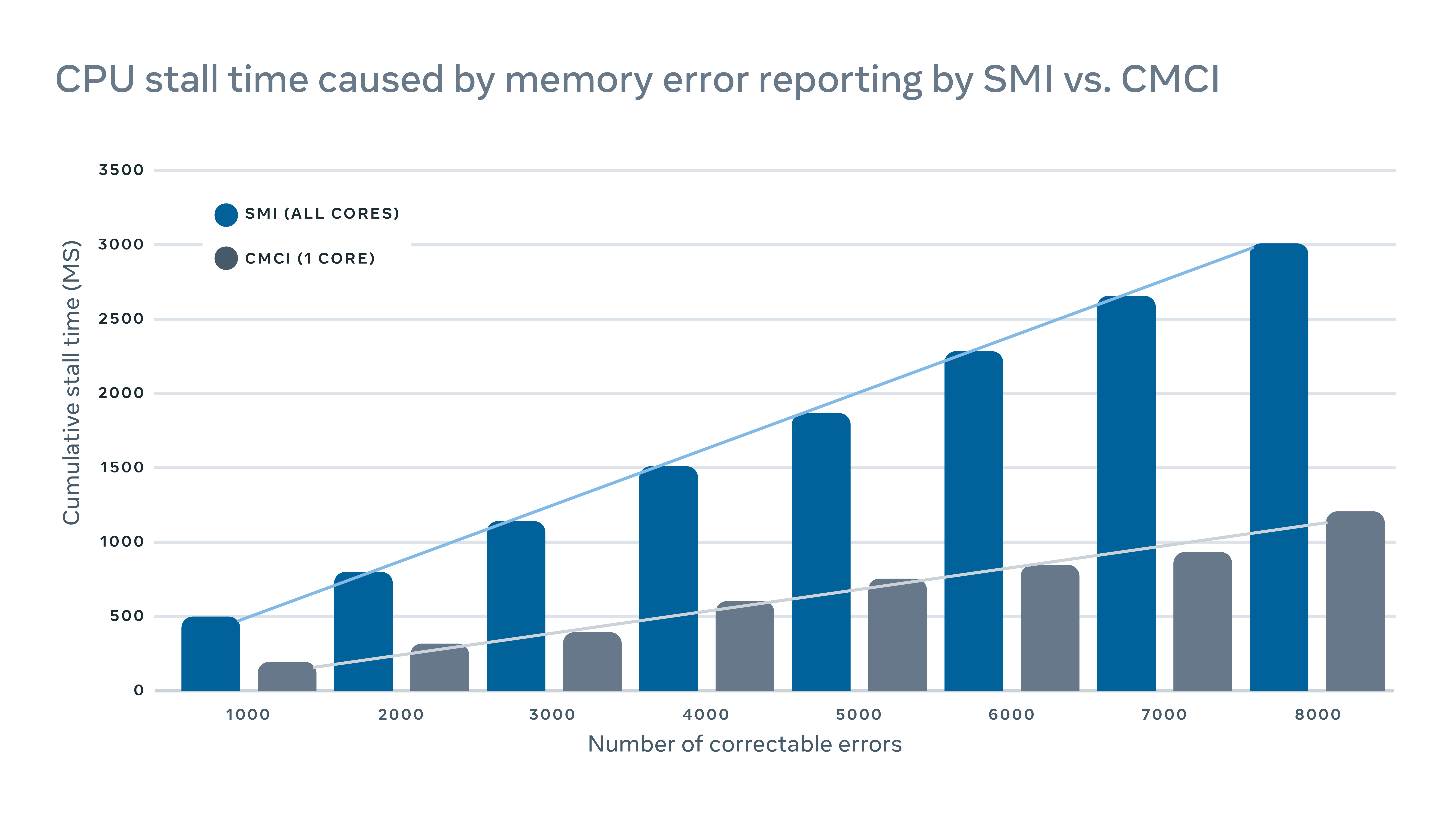
MachineChecker wykrywa awarie sprzętowe, sprawdzając różne dzienniki serwerów pod kątem raportów o błędach. Zazwyczaj, gdy wystąpi błąd sprzętowy, zostanie wykryty przez system (e.G., Niepowodzenie kontroli parytetu), a sygnał przerwania zostanie wysłany do procesora w celu obsługi i rejestrowania błędu.
Ponieważ te sygnały przerwań są uważane za sygnały o wysokim priorytecie, procesor zatrzyma normalną operację i poświęci swoją uwagę na obsługę błędu. Ale ma to negatywny wpływ na wydajność na serwer. Na przykład w celu rejestrowania błędów pamięci, na przykład tradycyjne przerwanie zarządzania systemem przerwań (SMI) zatrzymałoby wszystkie rdzenie procesora, podczas gdy religijna kontrola maszyny (CMCI) zatrzymałby tylko jeden z rdzeni CPU, pozostawiając resztę rdzeni CPU dostępnych do normalnej operacji.
Chociaż stragany procesora zwykle trwają tylko kilka setek milisekund, nadal mogą zakłócać usługi wrażliwe na opóźnienie. Na skalę oznacza to, że przerwania kilku maszyn mogą mieć kaskadowy wpływ na wydajność na poziomie usług.
Aby zminimalizować wpływ wydajności spowodowany raportowaniem błędów, wdrożyliśmy hybrydowy mechanizm raportowania błędów pamięci, który wykorzystuje zarówno CMCI, jak i SMI bez utraty dokładności pod względem liczby błędów pamięci prawidłowej.
Jak wykorzystujemy uczenie maszynowe do przewidywania napraw
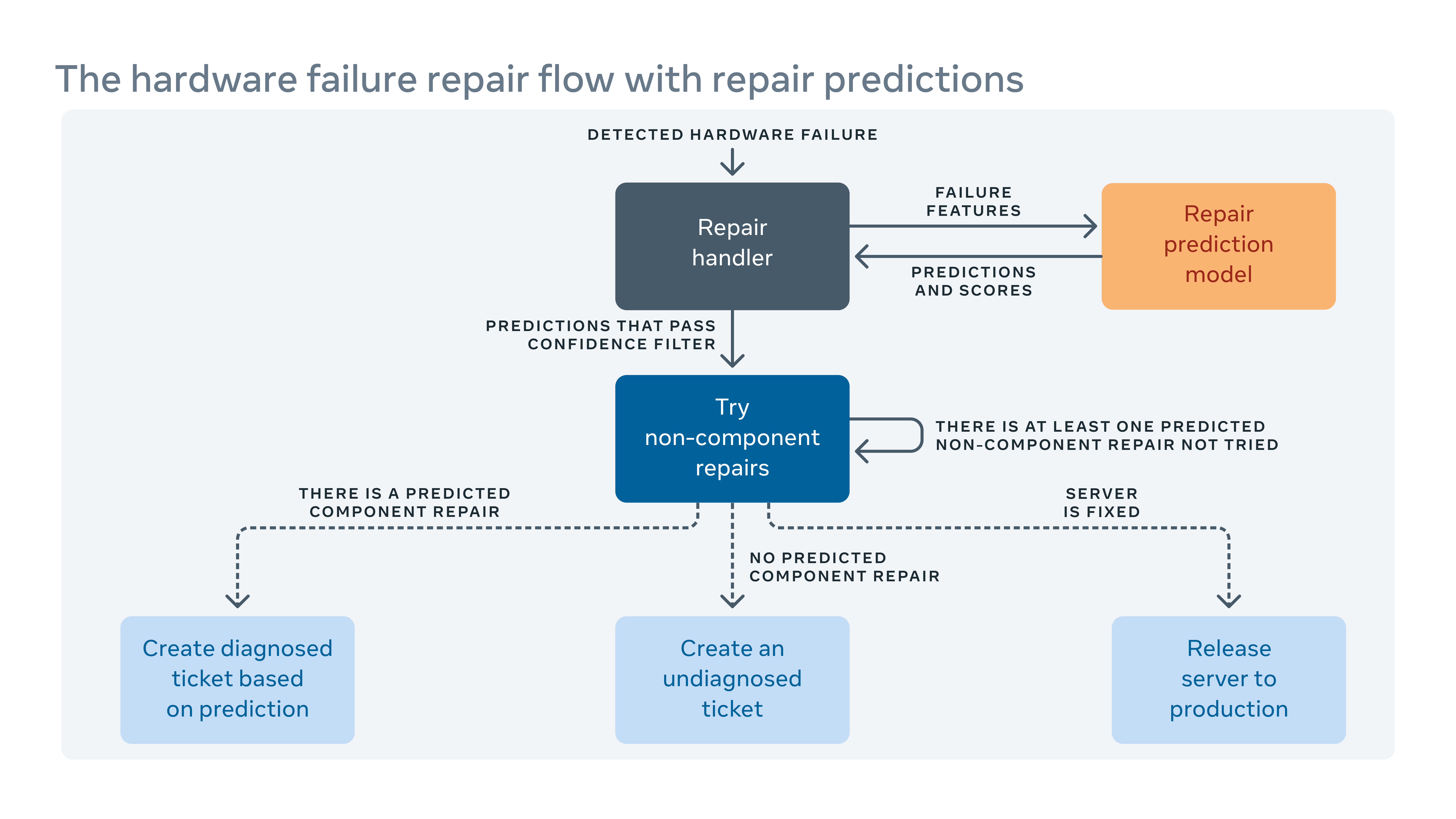
Ponieważ często wprowadzamy nowe konfiguracje sprzętowe i oprogramowania do naszych centrów danych, musimy również tworzyć nowe reguły dla naszego systemu automatycznego rekultywacji.
Gdy zautomatyzowany system nie może naprawić awarii sprzętowych, problemem jest bilet do ręcznej naprawy. Nowy sprzęt i oprogramowanie oznaczają nowe rodzaje potencjalnych awarii, które należy rozwiązać. Ale może istnieć luka między tym, kiedy zaimplementowany jest nowy sprzęt lub oprogramowanie i kiedy jesteśmy w stanie uwzględnić nowe reguły remediacyjne. Podczas tej luki niektóre bilety naprawcze mogą być klasyfikowane jako “niezdiagnozowany,” co oznacza, że system’t zasugerował działanie naprawcze, lub “źle zdiagnozowane,” co oznacza sugerowane działanie naprawcze’t skuteczne. Oznacza to więcej przestojów pracy i systemu, podczas gdy technicy muszą sami zdiagnozować problem.
Aby zamknąć lukę, zbudowaliśmy ramę uczenia maszynowego, która dowiaduje się, jak awarie zostały naprawione w przeszłości i próbuje przewidzieć, jakie naprawy byłyby konieczne dla obecnych niezdiagnozowanych i błędnie rozpoznanych biletów naprawczych. Na podstawie kosztów i korzyści z niepoprawnych i poprawnych prognoz przypisujemy próg zaufania do przewidywania dla każdego działania naprawy i optymalizujemy kolejność działań naprawczych. Na przykład w niektórych przypadkach wolelibyśmy najpierw wypróbować ulepszenie ponownego uruchomienia lub oprogramowania układowego, ponieważ tego rodzaju naprawy Don’t Wymagaj wszelkiej fizycznej naprawy sprzętu i zajęcia mniej czasu, więc algorytm powinien najpierw zalecić tego rodzaju działanie. Najwyraźniej uczenie maszynowe pozwala nam nie tylko przewidzieć, jak naprawić problem niezdiagnozowany lub źle zdiagnozowany, ale także priorytetowo traktować najważniejsze.
Jak my’Analiza zautomatyzowanego poziomu przyczyny na poziomie floty
Oprócz dzienników serwerów, które rejestrują ponowne uruchomienie, jądra panika nie jest poza pamięcią itp., W naszym systemie produkcyjnym istnieją również dzienniki oprogramowania i narzędzi. Ale skala i złożoność tych wszystkich oznacza’trudno zbadać wszystkie kłody wspólnie w celu znalezienia korelacji między nimi.
Zaimplementowaliśmy skalowalne narzędzie do analizy korzeniowej (RCA), które sortuje miliony wpisów dziennika (każde opisane przez potencjalnie setki kolumn), aby znaleźć łatwe do zrozumienia korelacje i wykonalne korelacje.
Dzięki wstępnie agregacji danych przy użyciu SCUBA, bazie danych w czasie rzeczywistym, znacznie poprawiliśmy skalowalność tradycyjnego algorytmu wydobywania wzorców, FP-Browth, w celu znalezienia korelacji w tym Frameworku RCA. Dodaliśmy również zestaw filtrów zgłoszonych korelacji w celu poprawy interpretacji wyniku. Wdrożyliśmy ten analizator szeroko w Facebooku dla RCA na temat awarii komponentów sprzętowych, nieoczekiwanego ponownego uruchamiania serwera i awarii oprogramowania.
Kto potrzebuje HP i Dell? Facebook projektuje teraz wszystkie własne serwery
Najnowsze centrum danych Facebooka nie będzie miało żadnych serwerów OEM.
Jon Brodkin – 14 lutego 2013 22:35 UTC

Komentarze czytelnika
Prawie dwa lata temu Facebook zaprezentował to, co nazwał projektem Otwartych komputerów. Pomysł polegał na udostępnieniu projektów sprzętu do centrum danych, takich jak serwery, pamięć i stojaki, aby firmy mogły budować własny sprzęt zamiast polegać na wąskich opcjach dostarczanych przez dostawców sprzętu.
Podczas gdy każdy mógłby skorzystać, Facebook kierował wdrażaniem niestandardowego sprzętu we własnych centrach danych. Projekt awansował do tego stopnia, że wszystkie nowe serwery wdrożone przez Facebook zostały zaprojektowane przez sam Facebooka lub zaprojektowane przez innych do wymagających specyfikacji Facebooka. Niestandardowy sprzęt dziś zajmuje ponad połowę sprzętu w centrach danych na Facebooku. Następnie Facebook otworzy centrum danych o powierzchni 290 000 stóp kwadratowych w Szwecji w całości z serwerami własnego projektu, pierwszego dla firmy.
„To pierwszy, w którym będziemy mieć 100 procent otwartych serwerów obliczeniowych” – powiedział ARS w wywiadzie telefonicznym w wywiadzie telefonicznym w wywiadzie telefonicznym w tym tygodniu Frank Frankovsky, wiceprezes ds.
Podobnie jak istniejące centra danych na Facebooku w Karolinie Północnej i Oregonie, ten, który pojawi się online tego lata w Luleå, Szwecja będzie miała dziesiątki tysięcy serwerów. Facebook umieszcza również swój sprzęt w wynajętym przestrzeni centrum danych, aby utrzymać obecność w pobliżu użytkowników na całym świecie, w tym w 11 witrynach kolokacji w USA. Różne czynniki przyczyniają się do wyboru lokalizacji: podatki, dostępna praca techniczna, źródło i koszt energii oraz klimat. Facebook nie korzysta z tradycyjnej klimatyzacji, zamiast tego polegać całkowicie na „powietrzu zewnętrznym i unikalnym systemie chłodzenia odparowującego, aby nasze serwery były wystarczająco chłodne”, powiedział Frankovsky.
Oszczędzając pieniądze, usuwając to, co nie’t potrzebę
Zauważył, że w skali Facebooka taniej jest utrzymywać własne centra danych niż polegać na dostawcach usług w chmurze. Ponadto tańsze jest również, aby Facebook unikał tradycyjnych dostawców serwerów.
Podobnie jak Google, Facebook projektuje własne serwery i ma je zbudowane przez ODM (oryginalnych producentów projektów) na Tajwanie i Chinach, a nie producenci producentów OEM (oryginalnych urządzeń), takich jak HP lub Dell. Rzucając własne, Facebook eliminuje to, co Frankovsky nazywa „nieuzasadnionym zróżnicowaniem”, funkcjami sprzętowymi, które sprawiają, że serwery są wyjątkowe, ale nie korzystają z Facebooka.
Może to być tak proste, jak plastikowa ramka na serwerze z logo marki, ponieważ ten dodatkowy materiał zmusza fanów do cięższej pracy. Frankovsky powiedział, że badanie wykazało standardowy serwer OEM o wielkości 1U „użył 28 watów mocy wentylatora do przeciągania powietrza przez impedancję spowodowaną przez tę plastikową ramkę”, podczas gdy równoważny otwarty serwer obliczeniowy używał tylko trzech watów w tym celu.

Co jeszcze rozebrał się Facebook? Frankovsky powiedział, że „wiele płyt głównych ma wiele zarządzania. To jest techniczny termin, którego lubię do tego używać.„Ten goop może być zintegrowanym silnikiem zarządzania cyklem życia HP lub narzędziami do zarządzania serwerami zdalnego Dell.
Funkcje te mogą być przydatne dla wielu klientów, szczególnie jeśli standaryzowali na jednym dostawcy. Ale przy rozmiarze Facebooka nie ma sensu polegać tylko na jednym dostawcy, ponieważ „usterka projektowa może przynieść dużą część floty lub dlatego, że brak części może przydać twoją zdolność do dostarczania produktu do centrów danych.”
Facebook ma własne narzędzia do zarządzania centrum danych, więc rzeczy wytwarzane przez HP lub Dell są niepotrzebne. Produkt dostawcy „zawiera własny zestaw interfejsów użytkowników, zestaw interfejsów API i ładny GUI, aby powiedzieć, jak szybko wirują fani, oraz niektóre rzeczy, które ogólnie większość klientów wdrażają te rzeczy na skalę jako nieuzasadnione zróżnicowanie” – powiedział Frankovsky. „Jest inaczej w sposób, który nie ma dla mnie znaczenia. To dodatkowe oprzyrządowanie na płycie głównej, nie tylko kosztuje zakup z perspektywy materiałów, ale także powoduje złożoność operacji.”
Ścieżka dla HP i Dell: dostosuj się do Otwartego obliczania
To nie znaczy, że Facebook przeklinuje HP i Dell na zawsze. „Większość naszego nowego sprzętu zbuduje ODM, takie jak Quanta”-powiedziała firma w odpowiedzi e-mail na jedno z naszych następujących pytań. „Robimy wiele źródeł naszego sprzętu, a jeśli OEM może zbudować nasze standardy i wprowadzić go w odległości 5 procent, to zwykle znajdują się w tych dyskusjach z wieloma źródłami.”
HP i Dell zaczęły tworzyć projekty, które są zgodne z otwartymi specyfikacjami obliczeniowymi, a Facebook powiedział, że testuje jeden z HP, aby sprawdzić, czy może zrobić cięcie. Firma potwierdziła jednak, że jej nowe centrum danych w Szwecji nie będzie zawierać żadnych serwerów OEM po otwarciu.
Facebook twierdzi, że otrzymuje 24-procentowe oszczędności finansowe od posiadania tańszej infrastruktury i oszczędza 38 procent bieżących kosztów operacyjnych w wyniku budowania własnych rzeczy. Niestandardowe serwery Facebooka nie uruchamiają różnych obciążeń niż jakikolwiek inny serwer-po prostu uruchamiają je bardziej wydajnie.
„Serwer HP lub Dell lub otwarty serwer obliczeni. „To tylko kwestia, ile pracy wykonujesz za wat za dolara.”
Facebook nie wirtualizuje swoich serwerów, ponieważ jego oprogramowanie zużywa już wszystkie zasoby sprzętowe, co oznacza, że wirtualizacja spowodowałaby karę wydajności bez zysku wydajności.
Gigant mediów społecznościowych opublikował projekty i specyfikacje własnych serwerów, płyt głównych i innego sprzętu. Na przykład płyta główna „Windmill” używa dwóch procesorów Intel Xeon E5-2600, z maksymalnie ośmioma rdzeniami na procesor.
Arkusz specyfikacji Facebooka to załamuje:
- 2 procesory serii Intel® Xeon® E5-2600 (LGA2011) do 115 W
- 2 Intel QuickPath Interconnect (QPI) łączy do 8 gt/s/kierunek
- Do 8 rdzeni na procesor (do 16 wątków z technologią nadmiernego tullania)
- Do 20 MB pamięci podręcznej ostatniego poziomu
- Tryb pojedynczego procesora
- DDR3 Direct załączona obsługa pamięci na CPU0 i CPU1 z:
- 4 -kanałowy interfejs pamięci DDR3 na procesorach 0 i 1
- 2 szczeliny DDR3 na kanał na procesor (łącznie 16 Dimms na płycie głównej)
- RDIMM/LV-RDIMM (1.5v/1.35 V), LRDIMM i ECC UDIMM/LV-UDIMM (1.5v/1.35 V)
- Pojedyncze, podwójne i quad dimms
- Prędkości DDR3 800/1066/1333/1600 MHz
- Do maksymalnej pamięci 512 GB z 32 GB RDIMM DIMMS
A teraz schemat płyty głównej:
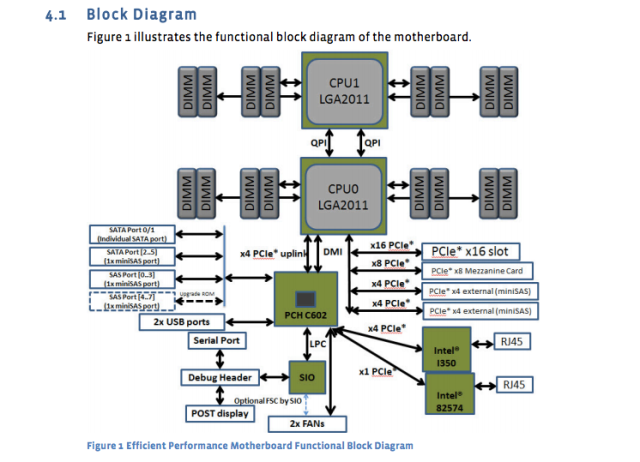
Te specyfikacje płyty głównej zostały opublikowane prawie rok temu, ale nadal są standardem. Nowo zaprojektowany serwer bazy danych „Dragonstone” i serwer Web „Winterfell” polegają na płycie głównej wiatrakowej, chociaż nowsze procesory Intel mogą trafić na produkcję na Facebooku jeszcze w tym roku.

Projekty serwerów Facebooka są dostosowane do różnych zadań. Jak donosi Timothy Prickett Morgan w zeszłym miesiącu, niektóre funkcje bazy danych na Facebooku wymagają nadmiarowych zasilaczy, podczas gdy inne zadania mogą być obsługiwane przez serwery z wieloma węzłami obliczeniowymi dzielącymi pojedyncze zasilacze.
Centra danych używają mieszanki pamięci flash i tradycyjnych dysków wirujących, a Flash obsługuje funkcjonalność Facebooka wymaga najszybszych dostępnych prędkości. Serwery bazy danych używają wszystkich lampy błyskowej. Serwery internetowe zwykle mają naprawdę szybkie procesory, ze stosunkowo niskimi ilościami pamięci i pamięci RAM. Frankovsky powiedział, że 16 GB to typowa ilość pamięci RAM. Chipsy Intel i AMD są obecne w sprzęcie Facebooka.
A Facebook jest obciążony dużą ilością „chłodnego” rzeczy napisanych raz i rzadko dostępny ponownie. Nawet tam Frankovsky chce coraz częściej używać lampy błyskowej ze względu na wskaźnik awarii wirujących dysków. Dzięki dziesiątkom tysięcy urządzeń „nie chcemy, aby technicy biegają wokół zastępowania dysków twardych” – powiedział.
Flash klasy centralnej danych jest zazwyczaj znacznie droższy niż wirujący dyski, ale Frankovsky twierdzi, że może istnieć sposób, aby warto go było tego warte. „Jeśli używasz klasy NAND [Flash] w napędach kciukowych, które są zwykle uważane za zamiatanie lub złom NAND, i używasz naprawdę fajnego algorytmu kontrolera, aby scharakteryzować, które komórki są dobre, a komórki nie, możesz potencjalnie zbudować naprawdę wysokowydajne rozwiązanie chłodne przy bardzo niskich kosztach”-powiedział.
Przejęcie elastyczności centrum danych do skrajności
Frankovsky chce, aby projekty są tak elastyczne, że poszczególne elementy można zamienić w odpowiedzi na zmieniające się popyt. Jednym wysiłkiem w tej linii jest nowa specyfikacja „Grupy Hug” na Facebooku dla płyt głównych, która może pomieścić procesory wielu dostawców. AMD i Intel, a także dostawcy układów ARM zastosowały mikro i calxeda, już zobowiązali się do obsługi tych płyt z nowymi produktami SoC (System na ChIP).
To był jeden z kilku wiadomości, które wyszły z otwartego szczytu obliczeniowego w zeszłym miesiącu w Santa Clara, Kalifornia. W sumie ogłoszenia wskazują na przyszłość, w której klienci mogą „uaktualnić wiele pokoleń procesorów bez konieczności zastępowania płyt głównych lub sieci”-zauważył Frankovsky w poście na blogu.
Calxeda wymyślił oparte na ramieniu tablicę serwerów, która może wsunąć się w otwarty system przechowywania sklepienia na Facebooku, o kodach nazwy „Knox.„” Zmienia urządzenie pamięci w serwer pamięci i eliminuje potrzebę osobnego serwera do kontrolowania dysku twardego ” – powiedział Frankovsky. (Facebook nie używa dziś serwerów ARM, ponieważ wymaga 64-bitowego wsparcia, ale Frankovsky mówi, że „rzeczy stają się interesujące” w technologii Arm.)
Intel wniósł także projekty nadchodzącej technologii fotoniki krzemowej, która pozwoli na połączenia 100 Gb / s, 10 razy szybciej niż Ethernet Connections, które Facebook używa dziś w swoich centrach danych. Przy niskim opóźnieniu umożliwionym przez tego rodzaju prędkości klienci mogą być w stanie oddzielić procesory, DRAM i przechowywanie w różnych częściach stojaka i po prostu dodać lub odejmować komponenty zamiast w razie potrzeby, w razie potrzeby, powiedział Frankovsky. W tym scenariuszu wiele hostów może dzielić system flash, poprawiając wydajność.
Pomimo wszystkich tych niestandardowych projektów pochodzących spoza świata OEM, HP i Dell nie są całkowicie pozostawione. Dostosowali się do schwytania niektórych klientów, którzy chcą elastyczności otwartych projektów obliczeniowych. Kierownik Dell dostarczył jeden z kluczowych wyników na tegorocznym otwartym szczycie obliczeniowym, a zarówno HP, jak i Dell w zeszłym roku ogłosiły „Projekty serwerów i pamięci czystych”, które są kompatybilne ze specyfikacją „Open Rack” Open Compute Project „Open Rack”.
Oprócz tego, że jest dobry na Facebooku, Frankovsky ma nadzieję, że Open Compute przyniesie korzyści klientom serwerów. Fidelity i Goldman Sachs należą do tych, którzy korzystają z niestandardowych projektów dostrojonych do swoich obciążeń w wyniku otwartego obliczenia. Powiedział, że mniejsi klienci mogą również skorzystać, nawet jeśli wynajmują przestrzeń z centrum danych, w którym nie mogą zmienić projektu serwera lub stojaka. Mogliby „brać elementy składowe [otwartego obliczenia] i restrukturyzować je w fizyczne projekty, które pasują do ich gniazd serwerów” – powiedział Frankovsky.
„Przemysł zmienia się i zmienia w dobry sposób, na korzyść konsumentów z powodu otwartego obliczenia” – powiedział.

