
Netflix Studio and Finance World에서 Apache Kafka가 등장합니다
요약:
Netflix에서 대부분의 응용 프로그램은 Java Client Library를 사용하여 Keystone 파이프 라인에 대한 데이터를 생성합니다. 파이프 라인은 프론팅 Kafka 클러스터, 데이터 수집 및 버퍼링을 담당하는 소비자 Kafka 클러스터로 구성됩니다. Netflix는 매일 7 천억 이상의 메시지를 처리하는 총 36 개의 카프카 클러스터를 운영합니다. 무손실 전달을 달성하기 위해 파이프 라인은 0 미만의 데이터 손실 속도를 허용합니다.01%. 생산자와 중개인은 가용성과 우수한 사용자 경험을 보장하도록 구성되어 있습니다.
키 포인트:
- Netflix 응용 프로그램은 Java Client Library를 사용하여 Keystone 파이프 라인에 대한 데이터를 생성합니다
- 각 응용 프로그램 인스턴스에는 여러 카프카 생산자가 있습니다
- 프론팅 카프카 클러스터는 메시지를 수집하고 버퍼합니다
- 소비자 Kafka 클러스터에는 실시간 소비자를위한 주제가 포함되어 있습니다
- Netflix는 매일 7 천억 이상의 메시지로 36 개의 Kafka 클러스터를 운영합니다
- 데이터 손실률은 0보다 작습니다.01%
- 생산자와 중개인은 가용성을 보장하도록 구성됩니다
- 제작자는 주제 라우팅 및 싱크 격리에 동적 구성을 사용합니다
- 비 Java 응용 프로그램은 Keystone Rest 엔드 포인트로 이벤트를 보낼 수 있습니다
- 메시지 순서는 배치 처리 또는 라우팅 계층에서 설정됩니다
질문:
- Netflix 애플리케이션은 Keystone 파이프 라인에 데이터를 생성하는 방법?
- Kafka 클러스터를 앞두고있는 역할은 무엇입니까??
- Keystone 파이프 라인에 존재하는 Kafka 클러스터의 유형?
- Netflix가 운영되는 Kafka 클러스터 수는 몇 개입니다?
- Netflix의 평균 데이터 수집 속도는 얼마입니까??
- Netflix에서 사용한 Kafka의 현재 버전은 무엇입니까??
- Netflix는 파이프 라인에서 무손실 전달을 어떻게 달성합니까??
- 생산자와 중개인이 가용성을 보장하기위한 구성은 무엇입니까??
- 메시지 순서는 어떻게 유지됩니까??
- 클라이언트 애플리케이션이 Kafka 클러스터를 향하는 것에서 직접 소비하지 않는 이유는 무엇입니까??
- 클라우드에서 Kafka를 실행할 때 어떤 문제가 발생하는지?
- 복제가 Kafka의 가용성에 어떤 영향을 미칩니다?
- Netflix가 사건을 해결하고 클러스터 안정성을 유지하기 위해 수행 한 것?
- Kafka 클러스터에 대한 Netflix의 배포 전략은 무엇입니까??
대부분의 Netflix 응용 프로그램은 Java 클라이언트 라이브러리를 사용하여 Keystone 파이프 라인에 대한 데이터를 생성합니다. 각 응용 프로그램 인스턴스에는 여러 Kafka 생산자가 있습니다.
Fronting Kafka 클러스터 생산자로부터 메시지를 수집하고 버퍼링합니다. 그들은 메시지 주입을위한 관문 역할을합니다.
Keystone 파이프 라인은 Fronting Kafka 클러스터 및 소비자 Kafka 클러스터로 구성됩니다.
Netflix는 36 개의 Kafka 클러스터를 운영합니다.
Netflix는 매일 7 천억 이상의 메시지를 섭취합니다.
Netflix는 Kafka 버전 0에서 전환 중입니다.8.2.1 ~ 0.9.0.1.
대량의 데이터 볼륨을 설명하면서 Netflix는 팀과 함께 수용 가능한 데이터 손실을 수락하기 위해 팀과 협력하여 일일 데이터 손실률이 0 미만입니다.01%.
생산자와 중개인은 “ACK = 1”, “블록으로 구성됩니다.~에.완충기.full = false “및”부정한.지도자.선거.enable = true “.
제작자는 키가 표시된 메시지를 사용하지 않으며 배치 처리 계층 또는 라우팅 레이어에서 메시지 순서가 다시 설정됩니다.
클라이언트 애플리케이션은 예측 가능한 부하 및 안정성을 보장하기 위해 Kafka 클러스터를 향한 Fronting Kafka 클러스터에서 직접 소비 할 수 없습니다.
클라우드에서 Kafka를 실행하면 예측할 수없는 인스턴스 수명주기, 일시적 네트워킹 문제 및 성능 문제를 일으키는 특이 치와 같은 문제가 발생합니다.
복제는 가용성을 향상시킬 수 있지만, 이상적 인 브로커는 복제 지연 및 버퍼 소진으로 인해 계단식 효과와 메시지 삭제를 유발할 수 있습니다.
Netflix는 상태와 복잡성을 줄이고, 이상치 탐지를 구현했으며, 사고로부터 빠르게 회복하기위한 조치를 개발했습니다.
넷플릭스.
Kafka 내부 키스톤 파이프 라인
Keystone 파이프 라인에는 두 개의 Kafka 클러스터 세트가 있습니다 : Fronting Kafka와 Consumer Kafka. Fronting Kafka 클러스터. 그들의 역할은 다운 스트림 시스템의 데이터 수집 및 버퍼링입니다. 소비자 Kafka 클러스터는 Samza가 실시간 소비자를 위해 라우팅 한 주제의 하위 집합을 포함합니다.
우리는 현재 Kafka와 Consumer Kafka를 위해 4,000 개 이상의 브로커 인스턴스로 구성된 36 개의 Kafka 클러스터를 운영하고 있습니다. 평균 하루에 7 천억 이상의 메시지가 섭취됩니다. 우리는 현재 Kafka 버전 0에서 전환 중입니다.8.2.1 ~ 0.9.0.1.
설계 원칙
현재 Kafka 아키텍처와 거대한 데이터 볼륨을 감안할 때 데이터 파이프 라인에 대한 무손실 전달을 달성하기 위해 AWS EC2에서는 비용이 많이 듭니다. 이를 설명합니다’VE는 인프라에 의존하는 팀과 협력하여 비용의 균형을 유지하면서 수용 가능한 데이터 손실에 도달했습니다. 우리’VE는 0 미만의 일일 데이터 손실률을 달성했습니다.01%. 삭제 된 메시지를 위해 메트릭이 수집되어 필요한 경우 조치를 취할 수 있습니다.
Keystone 파이프 라인은 응용 프로그램을 차단하지 않고 비동기 적으로 메시지를 생성합니다. 재시험 후 메시지를 전달할 수없는 경우 응용 프로그램의 가용성과 우수한 사용자 경험을 보장하기 위해 프로듀서가 삭제합니다. 이것이 바로 프로듀서 및 중개인을 위해 다음 구성을 선택한 이유입니다
- ACKS = 1
- 차단하다.~에.완충기.full = false
- 더러운.지도자.선거.enable = true
Netflix의 대부분의 응용 프로그램은 Java Client Library를 사용하여 Keystone 파이프 라인을 제작합니다. 해당 응용 프로그램의 각 인스턴스에는 여러 개의 Kafka 생산자가 있으며, 각각은 싱크 레벨 격리를 위해 프론팅 Kafka 클러스터로 생산됩니다. 제작자는 유연한 주제 라우팅 및 싱크 구성을 가지고 있으며, 신청 프로세스를 다시 시작하지 않고도 런타임에 변경할 수있는 동적 구성을 통해 구동됩니다. 이로 인해 트래픽 리디렉션 및 Kafka 클러스터의 주제 마이그레이션과 같은 것들이 가능합니다. 자바가 아닌 응용 프로그램의 경우 Kafka 클러스터를 프론팅하는 데 메시지를 전달하는 Keystone Rest 엔드 포인트로 이벤트를 보내도록 선택할 수 있습니다.
유연성을 높이기 위해 제작자는 키가있는 메시지를 사용하지 않습니다. 대략적인 메시지 순서는 배치 처리 계층 (Hive / Elasticsearch) 또는 스트리밍 소비자를위한 라우팅 레이어에서 다시 확립됩니다.
우리는 메시지 주입을위한 관문이기 때문에 프론팅 카프카 클러스터의 안정성을 우선 순위로 삼았습니다. 따라서 클라이언트 애플리케이션이 직접 소비하여 예측 가능한 부하가 있는지 확인할 수 없습니다.
클라우드에서 Kafka를 실행하는 도전
Kafka는 LinkedIn의 배포 목표로 데이터 센터와 함께 개발되었습니다. 우리는 Kafka를 클라우드에서 더 잘 운영하도록 주목할만한 노력을 기울였습니다.
클라우드에서 인스턴스에는 예측할 수없는 수명주기가 있으며 하드웨어 문제로 인해 언제든지 종료 될 수 있습니다. 일시적 네트워킹 문제가 예상됩니다. 이들은 무국적 서비스에 문제가되지 않지만 Zookeeper가 필요한 상태의 서비스와 조정을위한 단일 컨트롤러에게 큰 도전을 제기합니다.
우리의 대부분의 문제는 Outlier Brokers로 시작합니다. 특이점은 고르지 않은 워크로드, 하드웨어 문제 또는 특정 환경으로 인해 발생할 수 있습니다. 예를 들어 다중 테넌 시로 인한 시끄러운 이웃. 이상적인 브로커는 요청 또는 빈번한 TCP 타임 아웃/재전송에 대해 느린 응답을 가질 수 있습니다. 그러한 중개인에게 이벤트를 보내는 생산자. 버퍼 소진의 다른 기여 요인은 Kafka 0이라는 것입니다.8.2 명의 생산자가하지 않았습니다’t 버퍼에서 대기하는 메시지의 시간 초과 지원.
카프카’S 복제는 가용성을 향상시킵니다. 그러나 복제는 특이 치가 계단식 효과를 유발할 수있는 중개인들 사이의 상호 의존성으로 이어집니다. 특이 치가 복제가 느려지면 복제 지연이 쌓여 결국 파티션 리더가 디스크에서 읽어서 복제 요청을 제공 할 수 있습니다. 이로 인해 영향을받는 중개인이 속도가 떨어지고 결국 이전 경우에 설명 된대로 소진 버퍼로 인해 제작자가 메시지를 떨어 뜨립니다.
Kafka를 운영하는 초기에는 제작자가 Zookeeper 문제로 인해 수백 개의 인스턴스가있는 Kafka 클러스터에 상당한 양의 메시지를 삭제 한 사건을 경험했습니다. 수백 명의 중개인이있는 작은 시간 창에서 이와 같은 문제를 디버깅하는 것은 단순히 현실적이 아닙니다.
사건 이후, Kafka 클러스터의 상태와 복잡성을 줄이고, 특이 치를 감지하고, 사건이 발생할 때 깨끗한 상태로 빠르게 다시 시작할 수있는 방법을 찾기위한 노력이 이루어졌습니다.
Kafka 배포 전략
다음은 Kafka 클러스터를 배포하는 데 사용한 주요 전략입니다
- 하나의 거대한 클러스터가 아닌 여러 개의 작은 카프카 클러스터를 선호합니다. 이는 종속성을 줄이고 안정성을 향상시킵니다.
- 문제가있는 중개인을 식별하고 처리하기위한 이상적인 탐지 메커니즘 구현.
- 사고에서 빠르게 회복하고 깨끗한 상태로 시작하기위한 조치를 개발하십시오.
Netflix Studio and Finance World에서 Apache Kafka가 등장합니다
Netflix의 대부분의 응용 프로그램은 Java Client Library를 사용하여 Keystone 파이프 라인을 제작합니다. 해당 응용 프로그램의 각 인스턴스에는 여러 개의 Kafka 생산자가 있으며, 각각은 싱크 레벨 격리를 위해 프론팅 Kafka 클러스터로 생산됩니다. 제작자는 유연한 주제 라우팅 및 싱크 구성을 가지고 있으며, 신청 프로세스를 다시 시작하지 않고도 런타임에 변경할 수있는 동적 구성을 통해 구동됩니다. 이로 인해 트래픽 리디렉션 및 Kafka 클러스터의 주제 마이그레이션과 같은 것들이 가능합니다. 자바가 아닌 응용 프로그램의 경우 Kafka 클러스터를 프론팅하는 데 메시지를 전달하는 Keystone Rest 엔드 포인트로 이벤트를 보내도록 선택할 수 있습니다.
Kafka 내부 키스톤 파이프 라인
Keystone 파이프 라인에는 두 개의 Kafka 클러스터 세트가 있습니다 : Fronting Kafka와 Consumer Kafka. Fronting Kafka 클러스터. 그들의 역할은 다운 스트림 시스템의 데이터 수집 및 버퍼링입니다. 소비자 Kafka 클러스터는 Samza가 실시간 소비자를 위해 라우팅 한 주제의 하위 집합을 포함합니다.
우리는 현재 Kafka와 Consumer Kafka를 위해 4,000 개 이상의 브로커 인스턴스로 구성된 36 개의 Kafka 클러스터를 운영하고 있습니다. 평균 하루에 7 천억 이상의 메시지가 섭취됩니다. 우리는 현재 Kafka 버전 0에서 전환 중입니다.8.2.1 ~ 0.9.0.1.
설계 원칙
현재 Kafka 아키텍처와 거대한 데이터 볼륨을 감안할 때 데이터 파이프 라인에 대한 무손실 전달을 달성하기 위해 AWS EC2에서는 비용이 많이 듭니다. 이를 설명합니다’VE는 인프라에 의존하는 팀과 협력하여 비용의 균형을 유지하면서 수용 가능한 데이터 손실에 도달했습니다. 우리’VE는 0 미만의 일일 데이터 손실률을 달성했습니다.01%. 삭제 된 메시지를 위해 메트릭이 수집되어 필요한 경우 조치를 취할 수 있습니다.
Keystone 파이프 라인은 응용 프로그램을 차단하지 않고 비동기 적으로 메시지를 생성합니다. 재시험 후 메시지를 전달할 수없는 경우 응용 프로그램의 가용성과 우수한 사용자 경험을 보장하기 위해 프로듀서가 삭제합니다. 이것이 바로 프로듀서 및 중개인을 위해 다음 구성을 선택한 이유입니다
- ACKS = 1
- 차단하다.~에.완충기.full = false
- 더러운.지도자.선거.enable = true
Netflix의 대부분의 응용 프로그램은 Java Client Library를 사용하여 Keystone 파이프 라인을 제작합니다. 해당 응용 프로그램의 각 인스턴스에는 여러 개의 Kafka 생산자가 있으며, 각각은 싱크 레벨 격리를 위해 프론팅 Kafka 클러스터로 생산됩니다. 제작자는 유연한 주제 라우팅 및 싱크 구성을 가지고 있으며, 신청 프로세스를 다시 시작하지 않고도 런타임에 변경할 수있는 동적 구성을 통해 구동됩니다. 이로 인해 트래픽 리디렉션 및 Kafka 클러스터의 주제 마이그레이션과 같은 것들이 가능합니다. 자바가 아닌 응용 프로그램의 경우 Kafka 클러스터를 프론팅하는 데 메시지를 전달하는 Keystone Rest 엔드 포인트로 이벤트를 보내도록 선택할 수 있습니다.
유연성을 높이기 위해 제작자는 키가있는 메시지를 사용하지 않습니다. 대략적인 메시지 순서는 배치 처리 계층 (Hive / Elasticsearch) 또는 스트리밍 소비자를위한 라우팅 레이어에서 다시 확립됩니다.
우리는 메시지 주입을위한 관문이기 때문에 프론팅 카프카 클러스터의 안정성을 우선 순위로 삼았습니다. 따라서 클라이언트 애플리케이션이 직접 소비하여 예측 가능한 부하가 있는지 확인할 수 없습니다.
클라우드에서 Kafka를 실행하는 도전
Kafka는 LinkedIn의 배포 목표로 데이터 센터와 함께 개발되었습니다. 우리는 Kafka를 클라우드에서 더 잘 운영하도록 주목할만한 노력을 기울였습니다.
클라우드에서 인스턴스에는 예측할 수없는 수명주기가 있으며 하드웨어 문제로 인해 언제든지 종료 될 수 있습니다. 일시적 네트워킹 문제가 예상됩니다. 이들은 무국적 서비스에 문제가되지 않지만 Zookeeper가 필요한 상태의 서비스와 조정을위한 단일 컨트롤러에게 큰 도전을 제기합니다.
우리의 대부분의 문제는 Outlier Brokers로 시작합니다. 특이점은 고르지 않은 워크로드, 하드웨어 문제 또는 특정 환경으로 인해 발생할 수 있습니다. 예를 들어 다중 테넌 시로 인한 시끄러운 이웃. 이상적인 브로커는 요청 또는 빈번한 TCP 타임 아웃/재전송에 대해 느린 응답을 가질 수 있습니다. 그러한 중개인에게 이벤트를 보내는 생산자. 버퍼 소진의 다른 기여 요인은 Kafka 0이라는 것입니다.8.2 명의 생산자가하지 않았습니다’t 버퍼에서 대기하는 메시지의 시간 초과 지원.
카프카’S 복제는 가용성을 향상시킵니다. 그러나 복제는 특이 치가 계단식 효과를 유발할 수있는 중개인들 사이의 상호 의존성으로 이어집니다. 특이 치가 복제가 느려지면 복제 지연이 쌓여 결국 파티션 리더가 디스크에서 읽어서 복제 요청을 제공 할 수 있습니다. 이로 인해 영향을받는 중개인이 속도가 떨어지고 결국 이전 경우에 설명 된대로 소진 버퍼로 인해 제작자가 메시지를 떨어 뜨립니다.
Kafka를 운영하는 초기에는 제작자가 Zookeeper 문제로 인해 수백 개의 인스턴스가있는 Kafka 클러스터에 상당한 양의 메시지를 삭제 한 사건을 경험했습니다. 수백 명의 중개인이있는 작은 시간 창에서 이와 같은 문제를 디버깅하는 것은 단순히 현실적이 아닙니다.
사건 이후, Kafka 클러스터의 상태와 복잡성을 줄이고, 특이 치를 감지하고, 사건이 발생할 때 깨끗한 상태로 빠르게 다시 시작할 수있는 방법을 찾기위한 노력이 이루어졌습니다.
Kafka 배포 전략
다음은 Kafka 클러스터를 배포하는 데 사용한 주요 전략입니다
- 하나의 거대한 클러스터가 아닌 여러 개의 작은 카프카 클러스터를 선호합니다. 이는 각 클러스터의 작동 복잡성을 줄입니다. 우리의 가장 큰 클러스터는 200 명 미만의 브로커를 가지고 있습니다.
- 각 클러스터의 파티션 수를 제한하십시오. 각 클러스터에는 10,000 개 미만의 파티션이 있습니다. 이것은 가용성을 향상시키고 파티션 수에 바인딩 된 요청/응답의 대기 시간을 줄입니다.
- 각 주제에 대해 복제본의 균일 한 분포를 위해 노력하십시오. 작업 부하조차도 용량 계획 및 이상치 감지가 더 쉽습니다.
- Zookeeper 문제의 영향을 줄이기 위해 각 Kafka 클러스터에 대해 전용 Zookeeper 클러스터를 사용하십시오.
다음 표는 배포 구성을 보여줍니다.
카프카 장애 조치
기본 클러스터가 문제가 발생할 때 생산자와 소비자 (라우터) 트래픽을 새로운 Kafka 클러스터로 장착 할 수있는 프로세스를 자동화했습니다. 각각의 프론팅 Kafka 클러스터마다 원하는 런치 구성이 있지만 초기 용량이 최소화 된 콜드 대기 클러스터가 있습니다. 깨끗한 상태를 시작하도록 보장하기 위해, Failover Cluster에는 주제가없고 주제를 기본 Kafka 클러스터와 공유하지 않습니다. Failover 클러스터는 원래 클러스터가 가질 수있는 모든 복제 문제로부터 자유로울 수 있도록 복제 계수 1을 갖도록 설계되었습니다.
장애 조치가 발생하면 생산자와 소비자 트래픽을 전환하기 위해 다음 단계를 수행합니다
- 장애 조치 클러스터를 원하는 크기로 크기를 조정하십시오.
- 실패 클러스터에 대한 주제를 작성하고 라우팅 작업을 동시에 시작합니다.
- (선택적으로) 컨트롤러가 파티션 리더를 확립 할 때까지 기다리십시오.
- 생산자 구성을 동적으로 변경하여 생산자 트래픽을 장애 조치 클러스터로 전환하십시오.
장애 조치 시나리오는 다음 차트로 표시 할 수 있습니다
프로세스의 완전한 자동화를 통해 5 분 이내에 장애 조치를 수행 할 수 있습니다. 장애 조치가 성공적으로 완료되면 로그 및 메트릭을 사용하여 원래 클러스터의 문제를 디버깅 할 수 있습니다. 트래픽을 다시 전환하기 전에 클러스터를 완전히 파괴하고 새 이미지로 재건 할 수도 있습니다. 실제로, 우리는 종종 오프라인 유지 보수를 수행하는 동안 트래픽을 전환하기 위해 장애 조치 전략을 사용합니다. 이것이 우리가 Kafka 클러스터를 롤링 업그레이드 또는 인터 브로커 커뮤니케이션 프로토콜 버전을 설정하지 않고 새로운 Kafka 버전으로 업그레이드하는 방법입니다.
Kafka의 개발
우리는 Kafka를위한 유용한 도구를 많이 개발했습니다. 다음은 주요 내용입니다
프로듀서 스티커 파티셔너
이것은 우리가 Java Producer Library를 위해 개발 한 특별한 맞춤형 파티션입니다. 이름에서 알 수 있듯이 다음 파티션을 무작위로 선택하기 전에 구성 가능한 시간 동안 생산하기위한 특정 파티션을 고수합니다. 우리는 Lingering과 함께 Sticky Partitioner를 사용하여 메시지 배치를 개선하고 브로커의 부하를 줄이는 데 도움이된다는 것을 알았습니다. 다음은 끈적 끈적한 파티션의 효과를 보여주는 테이블입니다
랙 인식 레플리카 할당
우리의 모든 Kafka 클러스터는 3 개의 AWS 가용 영역에 걸쳐 있습니다. AWS 가용성 구역은 개념적으로 랙입니다. 하나의 구역이 다운 될 경우 가용성을 보장하기 위해 동일한 주제에 대한 복제본이 다른 영역에 할당되도록 Rack (Zone) Aware Replica 할당을 개발했습니다. 이것은 구역 정전의 위험을 줄이는 데 도움이 될뿐만 아니라 동일한 물리적 호스트에 공동으로 배치 된 여러 브로커가 호스트 문제로 종료 될 때 가용성을 향상시킵니다. 이 경우 Kafka보다 더 나은 결함 허용 기능이 있습니다’s n – 1 여기서 n은 복제 계수입니다.
이 작업은 KIP-36의 Kafka 커뮤니티와 Apache Kafka Github PULL 요청 #132에 기여합니다.
Kafka 메타 데이터 비주얼 라이저
카프카’S 메타 데이터는 Zookeeper에 저장됩니다. 그러나 전시 업체가 제공하는 트리 뷰는 탐색하기가 어렵고 정보를 찾고 상관시키는 데 시간이 많이 걸립니다.
우리는 메타 데이터를 시각화하기 위해 우리 자신의 UI를 만들었습니다. 차트와 표로 뷰를 모두 제공하고 풍부한 색 구성표를 사용하여 ISR 상태를 나타냅니다. 주요 기능은 다음과 같습니다
- 브로커, 주제 및 클러스터에 대한 개별 탭
- 대부분의 정보는 정렬 가능하고 검색 가능합니다
- 클러스터 전체에서 주제 검색
- 브로커 ID에서 AWS 인스턴스 ID로 직접 매핑
- 리더 가족 관계에 의한 중개인의 상관 관계
다음은 UI의 스크린 샷입니다
모니터링
우리는 Kafka를위한 전용 모니터링 서비스를 만들었습니다. 추적을 담당합니다
- 중개인 상태 (특히 Zookeeper의 오프라인 인 경우)
- 브로커’s 제작자로부터 메시지를 받고 소비자에게 메시지를 전달하는 능력. 모니터링 서비스는 지속적인 하트 비트 메시지의 생산자 및 소비자 역할을하며 이러한 메시지의 대기 시간을 측정합니다.
- 오래된 동물원 기반 소비자의 경우 각 파티션이 소비되도록 소비자 그룹의 파티션 수를 모니터링합니다.
- Keystone Samza 라우터의 경우 검사 지점 오프셋을 모니터링하고 브로커와 비교합니다’s 로그 오프셋이 붙지 않고 지연이 없도록.
또한 트래픽 흐름을 주제 수준과 대부분의 브로커로 모니터링하는 광범위한 대시 보드가 있습니다’S 메트릭.
향후 계획
우리는 현재 Kafka 0으로 마이그레이션하고 있습니다.9, 새로운 소비자 API, 생산자 메시지 시간 초과 및 할당량을 포함하여 몇 가지 기능이 있습니다. 우리는 또한 Kafka 클러스터를 AWS VPC로 옮기고 향상된 네트워킹 (EC2 Classic과 비교하여)이 가용성 및 자원 활용을 향상시키는 우위를 점할 것이라고 믿습니다.
우리는 주제를 위해 Tiered SLA를 소개 할 것입니다. 경미한 손실을 받아 들일 수있는 주제의 경우 하나의 복제본 사용을 고려하고 있습니다. 복제 없이는 대역폭에 큰 절약 할뿐만 아니라 컨트롤러에 의존 해야하는 상태 변경을 최소화합니다. 이것은 무국적 서비스를 선호하는 환경에서 Kafka를 덜 상태로 만들기위한 또 다른 단계입니다. 단점은 브로커가 사라질 때의 잠재적 메시지 손실입니다. 그러나 0에서 생산자 메시지 시간 초과를 활용하여.9 릴리스 및 아마도 AWS EBS 볼륨, 손실을 완화 할 수 있습니다.
라우팅 인프라, 컨테이너 관리, 스트림 처리 등에 대한 향후 Keystone 블로그를 계속 지켜봐 주시기 바랍니다!
Netflix Studio and Finance World에서 Apache Kafka가 등장합니다
Netflix는 2019 년에 세계적 수준의 독창적 인 콘텐츠를 제작하기 위해 약 150 억 달러를 소비했습니다. 지분이 너무 높으면 계획, 지출을 결정하고 모든 Netflix 콘텐츠를 설명하는 데 도움이되는 비판적 통찰력으로 비즈니스를 가능하게하는 것이 가장 중요합니다. 이러한 통찰력에는 다음이 포함될 수 있습니다
- 내년에 국제 영화와 시리즈에 얼마를 소비해야합니까??
- 우리는 생산 예산을 극복하려는 경향이 있습니까??
- 데이터, 직관 및 분석을 통해 몇 년 전에 카탈로그를 프로그래밍하여 가능한 최고의 슬레이트를 만드는 방법?
- 전 세계 콘텐츠에 대한 재무를 생산하고 월스트리트에보고하는 방법?
VCS가 좋은 투자를 위해 눈을 엄격하게 조정하는 방법과 유사하게, Content Finance Engineering Team’S 헌장.
이벤트를 받아들입니다
엔지니어링 관점에서 모든 재무 응용 프로그램은 마이크로 서비스로 모델링되고 구현됩니다. 넷플릭스. 단순한 세상에서 서비스는 HTTP를 통해 상호 작용할 수 있지만 확장하면서 스케일링되면 잠재적으로 분할 뇌/상태로 이어지고 가용성을 방해 할 수있는 동기식 요청 기반 상호 작용의 복잡한 그래프로 발전합니다.
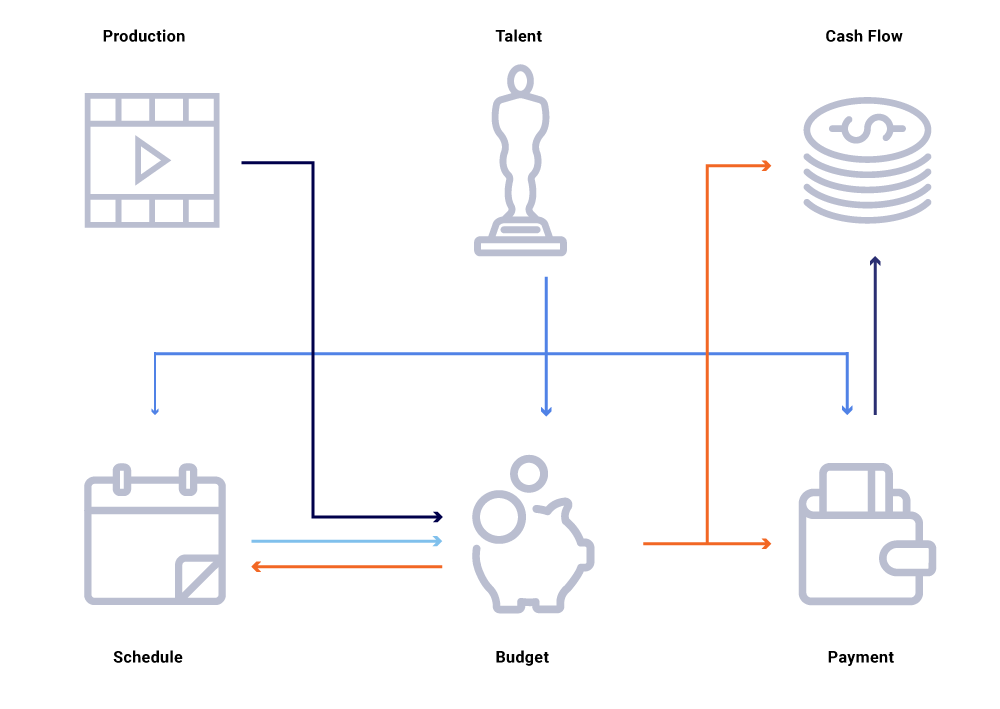
위의 관련 엔티티의 그래프에서 쇼의 제작 날짜 변경 사항을 고려하십시오. 이것은 우리의 프로그래밍 슬레이트에 영향을 미치며, 이는 현금 흐름 프로젝트, 인재 지불, 연도 예산 등에 영향을 미칩니다. 종종 마이크로 서비스 아키텍처에서는 몇 퍼센트의 고장이 허용됩니다. 그러나 컨텐츠 금융 엔지니어링을 요구하는 마이크로 서비스 중 하나의 실패로 인해 많은 계산이 동기화되지 않고 데이터가 수백만 달러에 달할 수 있습니다. 또한 통화 그래프가 쏟아져 사각 지대를 유발하면서도 가용성 문제로 이어질 수 있습니다? 현재 연도의 예측이 적극적으로 개발중인 쇼를 고려하지 않는 이유? 우리의 비용 보고서가 업스트림 변경을 정확하게 반영 할 수있는시기를 기대할 수 있습니까??
일련의 동기 요청과는 달리 이벤트 교환의 스트림으로서 서비스 상호 작용을 다시 생각합니다. 분리 된 거래 웹에서 디퍼 커플 링을 촉진하고 일류 시민으로서 추적 성을 제공합니다. 이벤트는 트리거 및 업데이트 이상입니다. 그들은 우리가 전체 시스템 상태를 재구성 할 수있는 불변의 흐름이됩니다.
게시/구독 모델로 이동하면 모든 서비스가 변경 사항을 메시지 버스에 이벤트로 게시 할 수 있으며, 이는 세계 상태를 조정 해야하는 다른 관심 서비스로 소비 할 수 있습니다. 이러한 모델을 사용하면 서비스가 상태 변경과 관련하여 서비스가 동기화되어 있는지, 그렇지 않은 경우 동기화하기까지 얼마나 걸리도록 추적 할 수 있습니다. 이러한 통찰력은 대규모 종속 서비스 그래프를 운영 할 때 매우 강력합니다. 이벤트 기반 통신 및 분산 소비는 일반적으로 대규모 동기 통화 그래프에서 볼 수있는 문제를 극복하는 데 도움이됩니다 (위에서 언급 한 바와 같이).
Netflix는 Apache Kafka ®를 이벤트, 메시징 및 스트림 처리 요구의 요금 표준으로 받아들입니다. Kafka는 모든 포인트-포인트 및 Netflix Studio Wide Communications의 다리 역할을합니다. Netflix의 운영 체제에 필요한 높은 내구성과 선형 확장 가능, 다중 테넌트 아키텍처를 제공합니다. 서비스 오퍼링으로서의 사내 Kafka. 이를 통해 마이크로 서비스의 전체 생태계가 의미있는 이벤트를 쉽게 생산하고 소비하고 비동기 통신의 힘을 발휘할 수 있습니다.
Netflix Studio Ecosystem 내의 일반적인 메시지 교환은 다음과 같습니다
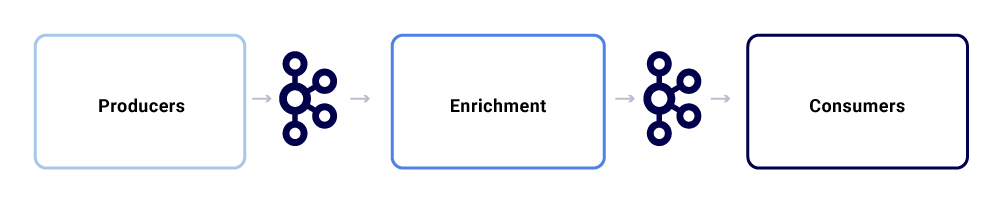
우리는 그것들을 세 가지 주요 하위 경쟁자로 분류 할 수 있습니다.
생산자
생산자는 전체 상태를 게시하거나 내부 상태의 중요한 부분이 특정 엔티티에 대해 변경되었다는 힌트를 원하는 시스템 일 수 있습니다. 페이로드 외에도 이벤트는 정규화 된 형식으로 준수해야하므로 추적하고 이해하기 쉽습니다. 이 형식에는 다음이 포함됩니다
- UUID : 보편적으로 고유 한 식별자
- 유형: CRUD (Create, Read, Update 또는 Delete) 유형 중 하나
- TS : 이벤트 타임 스탬프
CDC (Change Data Capture) 도구는 데이터베이스 변경에서 이벤트를 도출하는 또 다른 범주의 이벤트 제작자입니다. 여러 소비자가 데이터베이스 변경을 사용할 수있게하려면 유용 할 수 있습니다. 또한이 패턴을 사용하여 데이터 센터에서 동일한 데이터를 복제하기 위해 (단일 마스터 데이터베이스). 예를 들어 MySQL에 Elasticsearch 또는 Apache Solr ™에 인덱싱 해야하는 데이터가있는 경우입니다. CDC 사용의 이점은 소스 애플리케이션에 추가로드를 부과하지 않는다는 것입니다.
CDC 이벤트의 경우 이벤트 형식의 유형 필드를 사용하면 해당 싱크대가 요구하는대로 이벤트를 쉽게 조정하고 변환 할 수 있습니다.
농축기
Kafka에 데이터가 존재하면 다양한 소비 패턴을 적용 할 수 있습니다. 이벤트는 시스템 계산을위한 트리거, 거의 실시간 통신을위한 페이로드 전송, 데이터의 메모리 뷰를 풍부하고 구체화하기위한 신호를 포함하여 여러 가지 방법으로 사용됩니다.
마이크로 서비스가 데이터 세트의 전체보기가 필요한 곳에서 데이터 강화가 점점 일반화되고 있지만 데이터의 일부는 다른 서비스에서 나옵니다’S 데이터 세트. 결합 된 데이터 세트는 쿼리 성능을 향상 시키거나 집계 된 데이터에 대한 거의 실시간보기를 제공하는 데 유용 할 수 있습니다. 이벤트 데이터를 풍부하게하기 위해 소비자는 Kafka의 데이터를 읽고 다른 서비스 (GRPC 및 GraphQL을 포함하는 방법을 사용하여)에 연결된 데이터 세트를 구성 한 다음 나중에 다른 Kafka 주제에 공급됩니다.
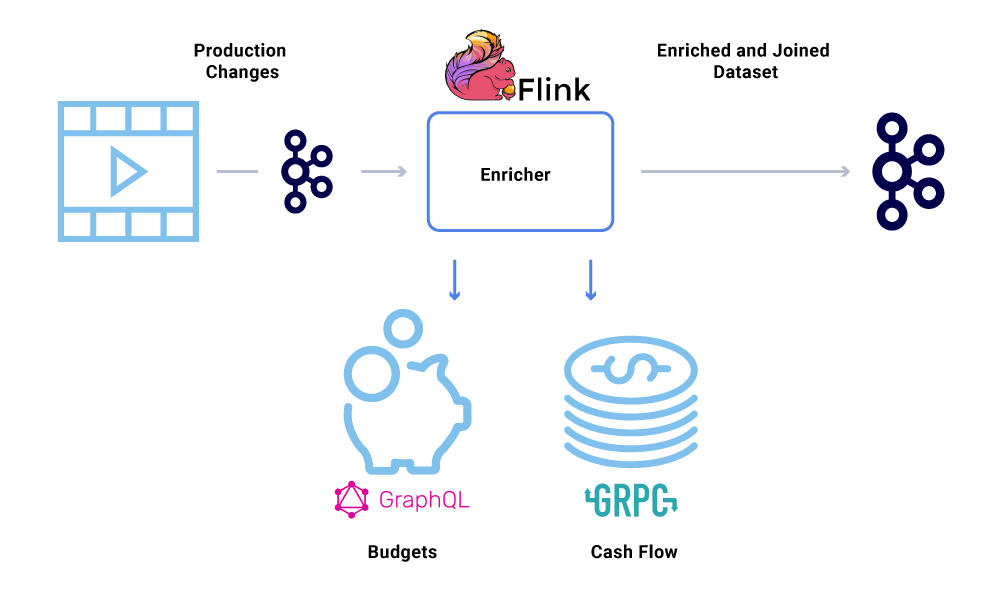
농축은 팬 아웃을 수행하고 데이터 세트를 구체화하는 데 책임이있는 별도의 마이크로 서비스로 실행할 수 있습니다. Windowing, Sessionization 및 State Management와 같은보다 복잡한 처리를 원하는 경우가 있습니다. 이러한 경우 Kafka 위에 성숙한 스트림 처리 엔진을 사용하여 비즈니스 로직을 구축하는 것이 좋습니다. Netflix에서는 Apache Flink ® 및 RocksDB를 사용하여 스트림 처리를 수행합니다. 우리’또한 유사한 목적으로 KSQLDB를 고려합니다.
이벤트 주문
재무 데이터 세트 내의 주요 요구 사항 중 하나는 이벤트의 엄격한 순서입니다. Kafka는 우리가이를 달성하는 데 도움이됩니다. 동일한 키로 전송 된 모든 이벤트 또는 메시지는 동일한 파티션으로 전송되므로 주문을 보장합니다. 그러나 제작자는 여전히 이벤트 순서를 망칠 수 있습니다.
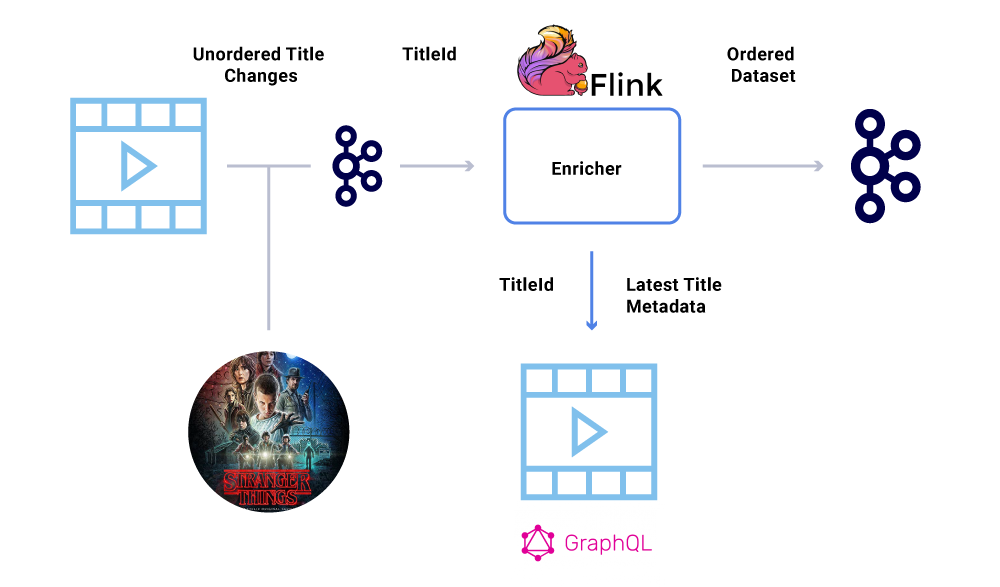
예를 들어, 출시일입니다 “낯선 것들” 원래 7 월에서 6 월까지 이동했지만 6 월에서 7 월까지. 여러 가지 이유로, 이러한 이벤트는 Kafka에게 잘못된 순서로 작성 될 수 있습니다 (프로듀서가 생산자 코드의 동시성 버그 등 Kafka에 도달하려고 할 때 네트워크 타임 아웃). 주문 딸꾹질은 다양한 재무 계산에 크게 영향을 줄 수 있습니다.
이 시나리오를 우회하기 위해, 제작자는 Kafka 메시지의 전체 페이로드가 아니라 변경된 엔티티의 기본 ID 만 보내도록 권장됩니다. 농축 프로세스 (위 섹션에 설명)는 최신 상태/페이로드를 얻기 위해 소스 서비스를 엔티티의 ID로 쿼리하여 주문 외 문제를 우회하는 우아한 방법을 제공합니다. 우리는 이것을 의미합니다 지연된 구체화, 그리고 주문한 데이터 세트를 보장합니다.
소비자
우리는 Spring Boot를 사용하여 Kafka 주제에서 읽은 많은 소비 마이크로 서비스를 구현합니다. Spring Boot는 Spring Kafka 커넥터라는 훌륭한 내장 Kafka 소비자를 제공하여 소비가 매끄럽게 만들어 데이터의 소비 및 부조화를위한 주석을 쉽게 연결하는 방법을 제공합니다.
우리가받은 데이터의 한 측면’논의 된 계약은 계약입니다. 이벤트 스트림의 사용을 확장하면서 다양한 데이터 세트 그룹으로 끝납니다. 그 중 일부는 많은 응용 프로그램에 의해 소비됩니다. 이 경우 출력에 대한 스키마를 정의하는 것이 이상적이며 후진 호환성을 보장하는 데 도움이됩니다. 이를 위해 Confluent Schema Registry 및 Apache Avro ™를 활용하여 버전 데이터 스트림을위한 스키미 화 된 스트림을 구축합니다.
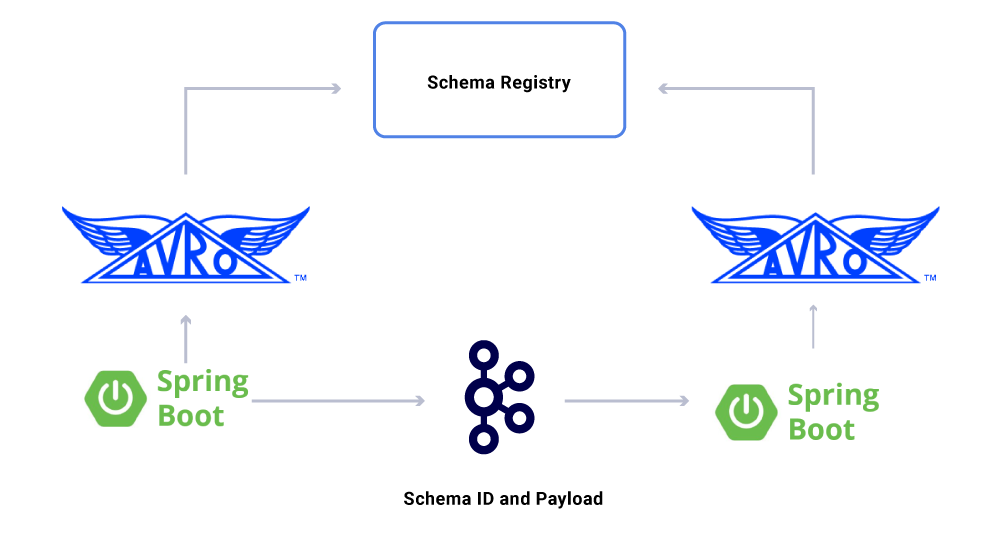
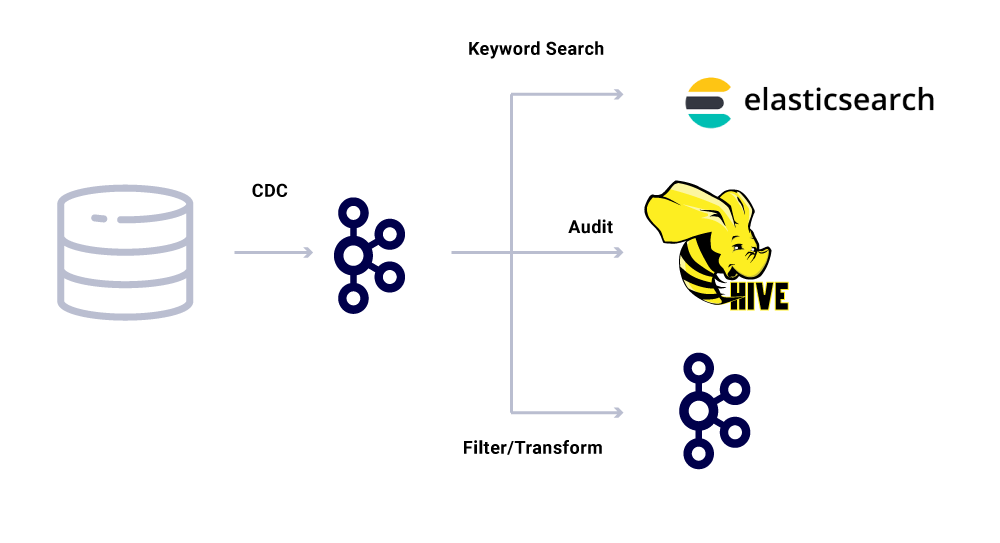
전용 마이크로 서비스 소비자 외에도 추가 분석을 위해 데이터를 다양한 상점에 색인화하는 CDC 싱크가 있습니다. 여기에는 키워드 검색을위한 Elasticsearch, 감사 용 Apache Hive ™ 및 추가 다운 스트림 처리를위한 Kafka가 포함됩니다. 이러한 싱크의 페이로드는 ID 필드를 기본 키로 사용하여 CRUD 작업을 식별하기위한 유형으로 Kafka 메시지에서 직접 파생됩니다.
메시지 전달 보증
분산 시스템에서 정확히 한 번 전달하는 것은 관련된 복잡성과 수많은 움직이는 부품으로 인해 사소하지 않습니다. 소비자는 잠재적 인 인프라와 생산자 사고를 설명하기 위해 묘사적인 행동을 가져야합니다.
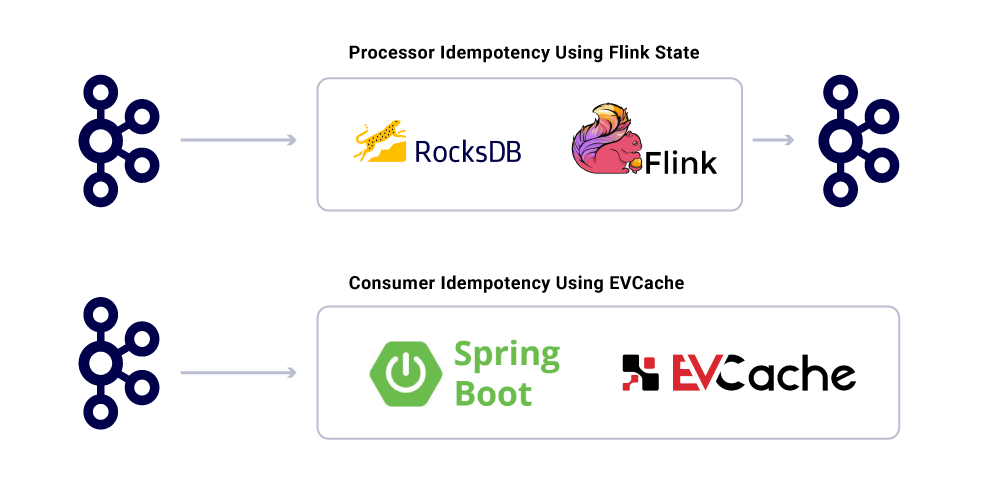
애플리케이션이 Idempotent라는 사실에도 불구하고 이미 처리 된 메시지에 대한 대형 작업 계산을 반복해서는 안됩니다. 이를 보장하는 인기있는 방법은 합리적인 만료 (SLA)를 기준으로 정의 된 분산 캐시에서 서비스가 소비 한 메시지의 UUID를 추적하는 것입니다. 만료 간격 내에서 동일한 UUID가 발생할 때마다 처리가 건너 뜁니다.
Flink에서의 처리는 내부 RocksDB 기반 상태 관리를 사용 하여이 보증을 제공하며 키는 메시지의 UUID입니다. Kafka를 사용 하여이 작업을 수행하려면 Kafka Streams는이를 수행 할 수있는 방법을 제공합니다. 스프링 부츠를 기반으로 응용 프로그램을 소비하여이를 달성하기 위해 evcache를 사용합니다.
인프라 서비스 수준 모니터링
그것’Netflix가 인프라 내에서 서비스 수준을 실시간으로 볼 수있는 데 중요합니다. Netflix는 ATLAS를 작성하여 치수 시계열 데이터를 관리하여 메트릭을 게시하고 시각화했습니다. 우리는 생산자, 프로세서 및 소비자가 게시 한 다양한 메트릭을 사용하여 전체 인프라의 거의 실시간 사진을 구성하는 데 도움이됩니다.
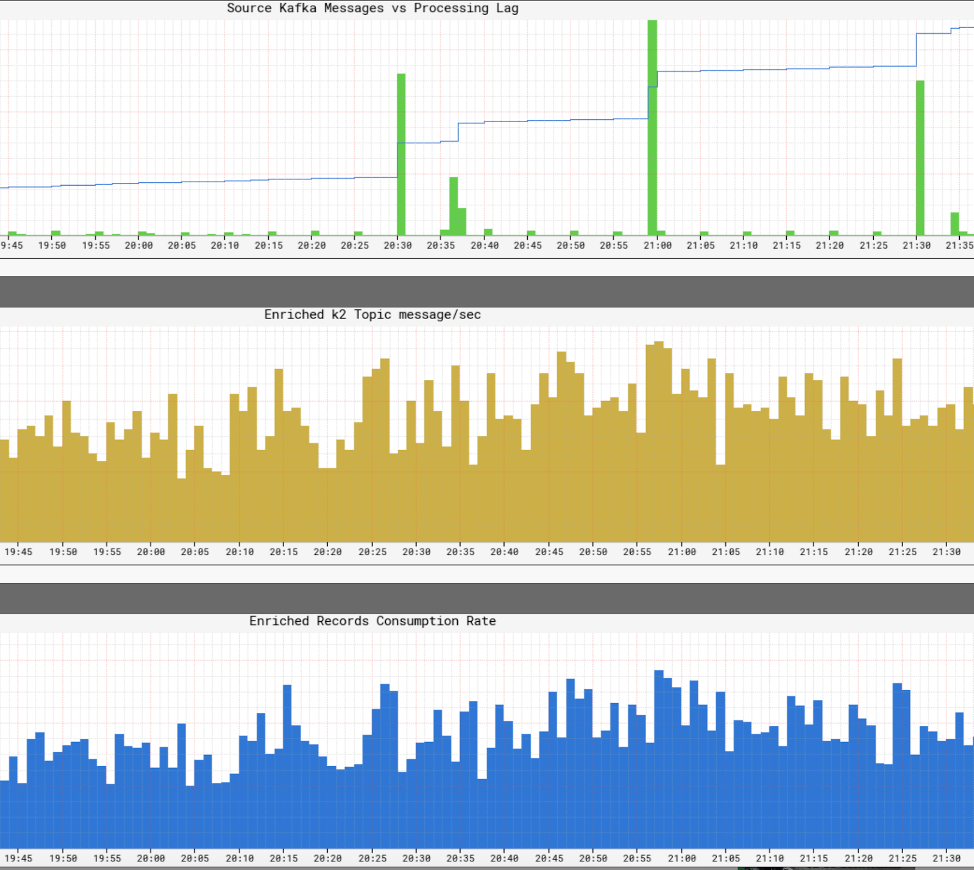
우리가 모니터링하는 주요 측면 중 일부는 다음과 같습니다
- 신선도 SLA
- 모든 싱크에 도달 할 때까지 이벤트 제작에서 끝까지 끝나는 시간?
- 모든 소비자의 처리 지연은 무엇입니까??
- 우리가 보낼 수있는 페이로드의 얼마나 큰가?
- 데이터를 압축해야합니다?
- 우리는 자원을 효율적으로 활용하고 있습니까??
- 더 빨리 소비 할 수 있습니까??
- 우리는 우리 상태에 대한 검문소를 만들고 실패의 경우 이력서를 이력 해 줄 수 있습니까??
- 이벤트 Firehose를 따라 잡을 수 없다면 응용 프로그램을 충돌시키지 않고 해당 소스에 배압을 적용 할 수 있습니까??
- 이벤트 버스트를 어떻게 처리합니까??
- 우리는 SLA를 충족시키기에 충분히 준비되어 있습니까??
개요
Netflix Studio Productions and Finance Team은 분산 거버넌스를 아키텍처 시스템의 방식으로 수용합니다. 우리는 Kafka를 이벤트 작업을위한 선택 플랫폼으로 사용합니다. 이는 시스템 상태를 기록하고 도출하는 불변의 방법입니다. Kafka는 우리가 인프라에서 더 많은 수준의 가시성과 분리를 달성하는 데 도움을 주면서 운영을 유기적으로 확장하는 데 도움이되었습니다. 그것은 Netflix Studio Infrastructure의 혁명의 핵심이며, 영화 산업.
더 많은 것에 관심이 있습니다?
만약 너라면’d 더 알고 싶어, 당신은 내 카프카 서밋 샌프란시스코 프레젠테이션 이벤트의 녹음과 슬라이드를 볼 수 있습니다 – 넷플릭스 원본!
Netflix : Apache Kafka가 수백만의 데이터를 수백만에서 인텔리전스로 바꾸는 방법
Netflix는 2020 년 컨텐츠 생산에 160 억 달러를 소비했습니다. 2021 년 1 월, Netflix Mobile 앱 (iOS 및 Android)은 1,900 만 번 다운로드되었고 한 달 후 회사는 203 명을 기록했다고 발표했습니다.전 세계적으로 6 천 6 백만 가입자. 그것’회사가 수집하고 프로세스가 방대하다고 가정하기에 안전합니다. 질문은 ~이야 –
Netflix는 중요한 비즈니스 결정을 내리기 위해 수십억 개의 데이터 레코드 및 이벤트를 어떻게 처리합니까??
160 억 달러의 연간 콘텐츠 예산으로 Netflix Aren의 의사 결정자’직관에 따라 콘텐츠 관련 결정을 내릴 것입니다. 대신 컨텐츠 큐레이터는 최첨단 기술을 사용하여 가입자 동작, 사용자 컨텐츠 선호도, 콘텐츠 제작 비용, 작동하는 콘텐츠 유형 등에 대한 대량의 데이터를 이해합니다. 이 목록은 계속됩니다.
Netflix 사용자는 평균 3을 소비합니다.플랫폼에서 하루 2 시간이며 Netflix의 최신 권장 사항을 지속적으로 공급받습니다’S 독점 추천 엔진. 이렇게하면 가입자 휘젓기가 낮고 새로운 가입자가 가입하도록 유도합니다. 데이터 중심 컨텐츠 전달은 이것의 전면 및 중심에 있습니다.
그래서 데이터 처리 관점에서 후드 아래에있는 것?
다시 말해, Netflix는 어떻게 데이터 중심 의사 결정을 방대한 규모로 만들어 낸 기술 백본을 구축 했습니까?? 2 억 2 천만 명의 가입자의 사용자 행동을 이해하는 방법?
Netflix는 Keystone 데이터 파이프 라인이라고하는 것을 사용합니다. 2016 년 에이 파이프 라인은 하루에 5 천억 이벤트를 처리했습니다. 이러한 이벤트에는 오류 로그, 사용자보기 활동, UI 활동, 문제 해결 이벤트 및 기타 여러 가지 귀중한 데이터 세트가 포함되었습니다.
Netflix에 따르면 기술 블로그에 게시 된대로 :
Keystone 파이프 라인은 배치 및 스트림 처리를위한 통합 이벤트 게시, 수집 및 라우팅 인프라입니다.
Kafka 클러스터는 Netflix의 Keystone Data Pipeline의 핵심 부분입니다. 2016 년 Netflix 파이프 라인은 36 Kafka 클러스터를 사용하여 하루에 수십억 개의 메시지를 처리했습니다.
아파치 카프카는 무엇입니까?? 그리고 왜 그렇게 인기를 얻었습니까??
Apache Kafka는 많은 양의 실시간 데이터를 수집하는 응용 프로그램을 개발할 수있는 오픈 소스 스트리밍 플랫폼입니다. 원래 LinkedIn의 천재에 의해 지어졌으며 현재 Netflix, Pinterest 및 Airbnb에서 몇 가지 이름을 지정합니다.
Kafka는 구체적으로 네 가지를 수행합니다
- 응용 프로그램이 데이터 또는 이벤트 스트림을 게시하거나 구독 할 수 있습니다
- 데이터 레코드를 정확하게 저장하고 결함이 강합니다
- 실시간, 대량 데이터 처리가 가능합니다.
- 성능 문제없이 하루에 수조 1 조의 데이터 레코드를 처리하고 처리 할 수 있습니다
소프트웨어 개발 팀은 Kafka를 활용할 수 있습니다’다음 API가있는 S 기능 :
- 생산자 API :이 API는 마이크로 서비스 또는 응용 프로그램이 특정 Kafka 주제에 데이터 스트림을 게시 할 수 있도록합니다. Kafka 주제는 데이터 및 이벤트 레코드를 순서대로 저장하는 로그입니다.
- 소비자 API :이 API는 응용 프로그램이 Kafka 주제에서 데이터 스트림을 구독 할 수 있도록합니다. 소비자 API를 사용하면 응용 프로그램은 데이터 스트림을 수집하고 처리 할 수 있으며, 이는 지정된 응용 프로그램에 대한 입력 역할을합니다.
- 스트림 API :이 API는 정교한 데이터 및 이벤트 스트리밍 응용 프로그램에 중요합니다. 기본적으로 다양한 Kafka 주제의 데이터 스트림을 소비하고 필요에 따라 처리하거나 변환 할 수 있습니다. 후 처리,이 데이터 스트림은 다운 스트림을 사용하고 기존 주제를 변환 할 다른 Kafka 주제에 게시됩니다.
- 커넥터 API : 최신 애플리케이션에서는 생산자 또는 소비자를 재사용하고 데이터 소스를 Kafka 클러스터에 자동으로 통합해야합니다. Kafka Connect는 Kafka를 외부 시스템에 연결하는 IS의 불필요하게 만듭니다.
Kafka의 주요 이점
Kafka 웹 사이트에 따르면 모든 Fortune 100 회사의 80%가 Kafka를 사용합니다. 가장 큰 이유 중 하나는 미션 크리티컬 응용 프로그램에 잘 맞기 때문입니다.
주요 회사는 다음과 같은 이유로 Kafka를 사용하고 있습니다
- 데이터 스트림과 시스템의 디퍼 커플 링을 쉽게 할 수 있습니다
- 배포되고 탄력적이며 결함이 강화되도록 설계되었습니다
- Kafka의 수평 확장 성은 가장 큰 장점 중 하나입니다. 초당 100 대의 클러스터와 수백만 개의 메시지로 확장 할 수 있습니다
- 고성능 실시간 데이터 스트리밍, 대규모 데이터 중심 애플리케이션의 중요한 요구 사항을 가능하게합니다
Kafka는 데이터 처리를 최적화하는 데 사용됩니다
Kafka는 다음을 포함하여 다양한 목적으로 산업 전반에 사용되고 있습니다
- 실시간 데이터 처리: 기술 회사에서의 사용 외에도 Kafka는 제조 산업에서 실시간 데이터 처리의 필수 요소입니다
- 규모에 따라 웹 사이트 모니터링 : Kafka는 교통량이 많은 웹 사이트에서 사용자 행동 및 사이트 활동을 추적하는 데 사용됩니다. 실시간 모니터링, 처리, Hadoop 연결 및 오프라인 데이터웨어 하우징에 도움이됩니다
- 주요 메트릭 추적 : Kafka는 다른 응용 프로그램에서 중앙 집중식 피드로 데이터를 집계하는 데 사용될 수 있으므로 대량 작동 데이터의 모니터링을 용이하게합니다
- 로그 집계 : 여러 소스의 데이터를 로그로 집계하여 분산 소비에 대한 명확성을 얻을 수 있습니다
- 메시징 시스템 : 대규모 메시지 처리 응용 프로그램을 자동화합니다
- 스트림 처리 : Kafka 주제가 다양한 단계에서 처리 파이프 라인에서 원시 데이터로 소비 된 후에는 추가 소비 또는 처리를 위해 집계, 강화 또는 새로운 주제로 변환됩니다
- 시스템의 종속성을 분리합니다
- 통합 Spark, Flink, Storm, Hadoop 및 기타 빅 데이터 기술로
Kafka를 사용하여 데이터를 처리하는 회사
다목적 성과 기능의 결과로 Kafka는 일부 세계에서 사용합니다’다양한 목적으로 가장 빠르게 성장하는 기술 회사 :
- Uber-수요를 계산하고 예측하고 예측 및 계산하여 실시간으로 사용자, 택시 및 여행 데이터를 실시간으로 수집하십시오
- LinkedIn-스팸을 방지하고 사용자 상호 작용을 수집하여 실시간으로 더 나은 연결 권장 사항을 제공합니다
- 트위터 – 스톰 스트림 처리 인프라의 일부
- Spotify – 로그 전달 시스템의 일부
- Pinterest – 로그 컬렉션 파이프 라인의 일부
- 에어 비앤비 – 이벤트 파이프 라인, 예외 추적 등.
- Cisco – Opensoc (보안 운영 센터)
공로 그룹’Kafka의 전문 지식
Merit Group에서 우리는 일부 세계와 협력합니다’윌 밍턴, 다우 존스, 글레니건 및 헤이 마켓과 같은 B2B 인텔리전스 회사. 당사의 데이터 및 엔지니어링 팀은 고객과 긴밀히 협력하여 데이터 제품 및 비즈니스 인텔리전스 도구를 구축합니다. 우리의 작업은 고객이 고성장 기회를 식별하도록 돕는 비즈니스 성장에 직접적인 영향을 미칩니다.
당사의 특정 서비스에는 대량 데이터 수집, AI 및 ML을 사용한 데이터 변환, 웹 감시 및 맞춤형 응용 프로그램 개발이 포함됩니다.
우리 팀은 또한 실시간 데이터 스트리밍 및 데이터 처리 응용 프로그램 구축에 대한 깊은 전문 지식을 제공합니다. Kafka에 대한 우리의 전문 지식은이 맥락에서 특히 유용합니다.
публикация участника 합류
시스템 상태를 기록하고 도출하는 아키텍트 시스템에 Netflix는 Apache Kafka 및 Distributed Governance를 활용합니다. 니틴 s. 이것이 인프라에서 가시성과 분리를 달성하는 데 도움이되는 방법을 공유하면서 작업을 유기적으로 확장하는 동시에 https : // lnkd./gfxaa6g
Netflix가 분산 스트리밍에 Kafka를 사용하는 방법
지류.io
- копировать
- 페이스 북
- 트위터
신자, 남편, 5의 아버지, IT 인프라 및 서비스 관리자, 팀 리더, 개발자.
Netflix
Netflix는 최근 MQTT 기반 이벤트 소싱 구현을 사용하여 안정적인 장치 관리 플랫폼을 구축 한 방법에 대한 블로그 게시물을 게시했습니다. 솔루션을 확장하기 위해 Netflix는 Apache Kafka, Alpakka-Kafka 및 CockroachDB를 사용합니다.
Netflix의 장치 관리 플랫폼은 응용 프로그램의 자동 테스트에 사용되는 하드웨어 장치를 관리하는 시스템입니다. Netflix Engineers Benson Ma와 Alok Ahuja는 플랫폼이 통과 한 여정을 설명합니다
Kafka 스트림 처리는 제대로하기가 어려울 수 있습니다. (. ) 다행스럽게도 Akka Streams와 Alpakka-Kafka가 제공하는 프리미티브는 이러한 솔루션을 구축하고 유지 관리 할 때 개발자 생산성을 확장하는 동안 우리가 가진 비즈니스 워크 플로우와 일치하는 스트리밍 솔루션을 구축 할 수있게함으로써 정확히이를 달성 할 수 있도록 권한을 부여합니다. Alpakka-Kafka 기반 프로세서를 제자리에두고 (. ), 우리는 제어 평면의 소비자 측면에서 결함 공차를 보장했는데, 이는 장치 관리 플랫폼 내에서 정확하고 신뢰할 수있는 장치 상태 집계를 가능하게하는 핵심입니다.
(. ) 플랫폼과 제어 평면의 신뢰성은 MQTT 전송, 인증 및 승인, 시스템 모니터링을 포함한 여러 영역에서 이루어진 중요한 작업에 달려 있습니다. (. )이 작업의 결과로 장치 관리 플랫폼이 시스템에 더 많은 장치를 탑승함에 따라 시간이 지남에 따라 작업량 증가로 계속 확장 될 것으로 기대할 수 있습니다.
다음 다이어그램은 아키텍처를 나타냅니다.

출처 : https : // netflixtechblog.com/에 대한 신뢰할 수있는 부호-관리-플랫폼 -4f86230ca623
로컬 참조 자동화 환경 (RAE) 임베디드 컴퓨터는 테스트중인 여러 장치에 연결됩니다 (DUT). 로컬 레지스트리 서비스는 RAE의 모든 연결된 장치에 대한 정보를 감지, 온 보딩 및 유지 관리 할 책임이 있습니다. 장치 속성 및 속성이 시간이 지남에 따라 변경됨에 따라 이러한 변경 사항을 로컬 레지스트리로 저장하고 동시에 클라우드 기반 제어 평면에 상류로 게시했습니다. 속성 변경 외에도 로컬 레지스트리는 정기적으로 장치 레코드의 전체 스냅 샷을 게시합니다. 이 체크 포인트 이벤트는 누락 된 업데이트를 지키면서 데이터 피드 소비자의 상태 재구성을 더 빠르게 할 수 있습니다.
MQTT를 사용하여 클라우드에 업데이트가 게시됩니다. MQTT는 사물 인터넷 (IoT)을위한 오아시스 표준 메시징 프로토콜입니다. 소형 코드 풋 프린트 및 최소 네트워크 대역폭과 원격 장치를 연결하는 데 이상적인 가볍면서 신뢰할 수있는 게시/가입 메시징 전송입니다. MQTT 브로커는 모든 메시지를 수신하고, 필터링하고, 그에 따라 구독 클라이언트에게 보냅니다.
Netflix는 조직 전체에서 Apache Kafka를 사용합니다. 결과적으로 브리지는 MQTT 메시지를 Kafka Records로 변환합니다. 메시지가 할당 된 MQTT 주제에 대한 레코드 키를 설정합니다. Ma와 Ahuja는 “MQTT에 게시 된 장치 업데이트에 device_session_id 주제에서, 주어진 장치 세션의 모든 장치 정보 업데이트는 동일한 Kafka 파티션에 효과적으로 나타나서 소비를위한 잘 정의 된 메시지 순서를 제공합니다.”
클라우드 레지스트리는 게시 된 메시지를 수집하고 처리하며 구체화 된 데이터를 CockroACHDB가 뒷받침하는 데이터 스토어로 푸시합니다. CockroachDB는 NewsQL이라는 RDBMS 시스템 클래스의 구현입니다. Ma와 Ahuja는 Netflix의 선택을 설명합니다
바퀴벌레. 또한 다른 SQL 스토어와 달리 CockroachDB는 수평으로 확장 가능하도록 처음부터 설계되었으며, 이는 클라우드 레지스트리의 장치 관리 플랫폼에 탑승 한 장치 수를 확장 할 수있는 클라우드 레지스트리의 능력에 대한 우려를 해결합니다.
다음 다이어그램은 클라우드 레지스트리로 구성된 Kafka 처리 파이프 라인을 보여줍니다.

출처 : https : // netflixtechblog.com/에 대한 신뢰할 수있는 부호-관리-플랫폼 -4f86230ca623
Netflix는 위에 묘사 된 스트림 처리 파이프 라인을 구현하기위한 많은 프레임 워크를 고려했습니다. 이러한 프레임 워크에는 Kafka Streams, Spring Kafkalistener, Project Reactor 및 Flink가 포함됩니다. 결국 Alpakka-Kafka를 선택했습니다. 이 선택의 이유는 Alpakka-Kafka가 스프링 부팅 통합을 제공하기 때문입니다. “자동 역압 지원 및 스트림 감독을 포함하여 스트림 처리에 대한 세밀한 제어.”Ma와 Ahuja에 따르면 Akka와 Alpakka-Kafka는 대안보다 가벼우 며 시간이 지남에 따라 유지 보수 비용이 낮아집니다.
Alpakka-Kafka 기반 구현은 초기 Spring Kafkalistsener 기반의 구현을 대체했습니다. 새로운 생산 구현에서 측정 된 메트릭은 Alpakka-Kafka의 기본 역압 지원이 Kafka 소비를 동적으로 확장 할 수 있음을 보여줍니다. Kafkalistener와 달리 Alpakka-Kafka는 소비하거나 과잉 소비되지 않습니다. 또한 릴리스 후 최대 소비자 지연 값이 감소하면 Alpakka-Kafka와 AKKA의 스트리밍 기능이 갑작스런 메시지로드에 직면하더라도 규모가 잘 작동합니다.

