
Google Docs : Audio to Text Transcription에서 전사하십시오
아래 코드 스 니펫을 사용하여 FFMPEG를 사용하여 비디오 파일을 오디오 파일로 변환하십시오 .
Speech-to-Text를 사용하여 비디오 파일에서 오디오를 전사하십시오
이 자습서.
오디오 파일은 여러 다른 소스에서 나올 수 있습니다. 오디오 데이터는 전화 (예 : 음성 메일) 또는 비디오 파일에 포함 된 사운드 트랙에서 나올 수 있습니다.
Speech-to-Text는 여러 기계 학습 중 하나를 사용할 수 있습니다 모델 오디오 파일을 전사하려면 오디오의 원래 소스와 가장 잘 어울립니다. 원래 오디오의 소스를 지정하여 음성 전사에서 더 나은 결과를 얻을 수 있습니다. 이를 통해 Speech-to-Text는 오디오 파일과 유사한 데이터를 위해 교육 된 기계 학습 모델을 사용하여 오디오 파일을 처리 할 수 있습니다.
목표
- 비디오 파일에 대한 오디오 전사 요청을 Speech-to-Text로 보내십시오.
소송 비용
- 음성-텍스트
예상 사용량을 기반으로 비용 추정치를 생성하려면 가격 계산기를 사용하십시오. 새로운 Google 클라우드 사용자는 무료 평가판을받을 수 있습니다.
시작하기 전에
이 튜토리얼에는 몇 가지 전제 조건이 있습니다
- Google Cloud 콘솔에서 음성-텍스트 프로젝트를 설정했습니다.
- Google Cloud 콘솔에서 응용 프로그램 기본 자격 증명을 사용하여 환경을 설정했습니다.
- 선택한 프로그래밍 언어를위한 개발 환경을 설정했습니다.
- 선택한 프로그래밍 언어를 위해 Google Cloud 클라이언트 라이브러리를 설치했습니다.
오디오 데이터를 준비하십시오
비디오에서 오디오를 전사하기 전에 비디오 파일에서 데이터를 추출해야합니다. 오디오 데이터를 추출한 후 클라우드 스토리지 버킷에 저장하거나 Base64 인코딩으로 변환해야합니다.
메모: 전사를 위해 클라이언트 라이브러리를 사용하는 경우 오디오 데이터를 저장하거나 변환 할 필요가 없습니다. 전사 요청을 보내기 전에 비디오 파일에서 오디오 데이터를 추출하면됩니다.
오디오 데이터를 추출하십시오
FFMPEG와 같은 오디오 및 비디오 파일을 처리하는 파일 변환 도구를 사용할 수 있습니다.
아래 코드 스 니펫을 사용하여 FFMPEG를 사용하여 비디오 파일을 오디오 파일로 변환하십시오 .
FFMPEG -I 비디오 입력 파일 오디오 출력 파일
오디오 데이터를 저장하거나 변환합니다
로컬 컴퓨터 또는 클라우드 스토리지 버킷에 저장된 오디오 파일을 전사 할 수 있습니다.
다음 명령을 사용하여 Gsutil 도구를 사용하여 오디오 파일을 기존 클라우드 스토리지 버킷에 업로드하십시오.
GSUTIL CP 오디오 출력 파일 스토리지-버킷-루리
로컬 파일을 사용하고 명령 줄에서 CURL 도구를 사용하여 요청을 보내려면 오디오 파일을 Base64 인코딩 된 데이터로 변환해야합니다.
다음 명령을 사용하여 오디오 파일을 텍스트 파일로 변환하십시오.
Base64 오디오 출력 파일 -w 0> 오디오 데이터 텍스트
전사 요청을 보내십시오
다음 코드를 사용하여 음성으로 전사 요청을 보내십시오.
로컬 파일 요청
규약
연설을 참조하십시오 : 자세한 내용은 API 엔드 포인트 인식.
동기 음성 인식을 수행하려면 사후 요청을 작성하고 적절한 요청 본문을 제공하십시오. 다음은 CURL을 사용한 게시물 요청의 예를 보여줍니다 . 이 예제는 Google Cloud Cloud Cli를 사용하여 프로젝트를 위해 설정된 서비스 계정에 대한 Access Token을 사용합니다. GCLOUD CLI 설치에 대한 지침, 서비스 계정으로 프로젝트 설정 및 액세스 토큰을 얻으려면 QuickStart를 참조하십시오.
curl -s -h "content-type : application/json"\ -h "권한 : bearer $ (gcloud auplic application-default print-access-token)"\ https : // speech.googleapis.com/v1/speech : 인식 \ -data ' < "config": < "encoding": "LINEAR16", "sampleRateHertz": 16000, "languageCode": "en-US", "모델": "비디오" >, "오디오": < "uri": "gs://cloud-samples-tests/speech/Google_Gnome.wav" >> '' '
요청 본문 구성에 대한 자세한 내용은 ReconsitionConfig 참조 문서를 참조하십시오.
요청이 성공하면 서버는 200 OK HTTP 상태 코드와 JSON 형식의 응답을 반환합니다
가다
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 지역 개발 환경에 대한 인증 설정을 참조하십시오.
FUNC 모델 선택 (W IO.Writer, Path String) 오류 {ctx : = context.배경 () 클라이언트, err : = speech.err 인 경우 NewClient (CTX) != nil {return fmt.errorf ( "newclient : %w", err)}} 연기 클라이언트.close () // path = "../testdata/google_gnome.Wav "데이터, err : = ioutil.readfile (path) err != nil {return fmt.errorf ( "readfile : %w", err)} req : = & speechpb.enderizerequest {config : & spectionpb.ReconsitionConfig {encoding : speechpb.ReconsitionConfig_linear16, SamplerateHertz : 16000, LanguageCode : "EN-US", Model : "Video",}, Audio : & SpeechPB.인정 받침대 {audiosource : & specivepb.inkepitionAudio_content,},} resp, err : = 클라이언트.ERR 인 경우 (CTX, Req)를 인식하십시오 != nil {return fmt.errorf ( "인식 : %w", err)}} 결과 : = 범위 resp.결과 {fmt.fprintf (w, "%s \ n", 문자열.반복 ( "-", 20)) fmt.j의 fprintf (w, "result %d \ n", i+1), 대안 : = 범위 결과.대안 {fmt.fprintf (w, "대체 %d : %s \ n", j+1, 대안.전사)}} return nil} 자바
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 SET U를 참조하십시오
Google Docs : Audio to Text Transcription에서 전사하십시오
아래 코드 스 니펫을 사용하여 FFMPEG를 사용하여 비디오 파일을 오디오 파일로 변환하십시오 .
Speech-to-Text를 사용하여 비디오 파일에서 오디오를 전사하십시오
이 자습서.
오디오 파일은 여러 다른 소스에서 나올 수 있습니다. 오디오 데이터는 전화 (예 : 음성 메일) 또는 비디오 파일에 포함 된 사운드 트랙에서 나올 수 있습니다.
Speech-to-Text는 여러 기계 학습 중 하나를 사용할 수 있습니다 모델 오디오 파일을 전사하려면 오디오의 원래 소스와 가장 잘 어울립니다. 원래 오디오의 소스를 지정하여 음성 전사에서 더 나은 결과를 얻을 수 있습니다. 이를 통해 Speech-to-Text는 오디오 파일과 유사한 데이터를 위해 교육 된 기계 학습 모델을 사용하여 오디오 파일을 처리 할 수 있습니다.
목표
- 비디오 파일에 대한 오디오 전사 요청을 Speech-to-Text로 보내십시오.
소송 비용
- 음성-텍스트
예상 사용량을 기반으로 비용 추정치를 생성하려면 가격 계산기를 사용하십시오. 새로운 Google 클라우드 사용자는 무료 평가판을받을 수 있습니다.
시작하기 전에
이 튜토리얼에는 몇 가지 전제 조건이 있습니다
- Google Cloud 콘솔에서 음성-텍스트 프로젝트를 설정했습니다.
- Google Cloud 콘솔에서 응용 프로그램 기본 자격 증명을 사용하여 환경을 설정했습니다.
- 선택한 프로그래밍 언어를위한 개발 환경을 설정했습니다.
- 선택한 프로그래밍 언어를 위해 Google Cloud 클라이언트 라이브러리를 설치했습니다.
오디오 데이터를 준비하십시오
비디오에서 오디오를 전사하기 전에 비디오 파일에서 데이터를 추출해야합니다. 오디오 데이터를 추출한 후 클라우드 스토리지 버킷에 저장하거나 Base64 인코딩으로 변환해야합니다.
메모: 전사를 위해 클라이언트 라이브러리를 사용하는 경우 오디오 데이터를 저장하거나 변환 할 필요가 없습니다. 전사 요청을 보내기 전에 비디오 파일에서 오디오 데이터를 추출하면됩니다.
오디오 데이터를 추출하십시오
FFMPEG와 같은 오디오 및 비디오 파일을 처리하는 파일 변환 도구를 사용할 수 있습니다.
아래 코드 스 니펫을 사용하여 FFMPEG를 사용하여 비디오 파일을 오디오 파일로 변환하십시오 .
ffmpeg -I 비디오 입력 파일 오디오 출력 파일
오디오 데이터를 저장하거나 변환합니다
로컬 컴퓨터 또는 클라우드 스토리지 버킷에 저장된 오디오 파일을 전사 할 수 있습니다.
다음 명령을 사용하여 Gsutil 도구를 사용하여 오디오 파일을 기존 클라우드 스토리지 버킷에 업로드하십시오.
Gsutil CP 오디오 출력 파일 스토리지 버킷 오리
로컬 파일을 사용하고 명령 줄에서 CURL 도구를 사용하여 요청을 보내려면 오디오 파일을 Base64 인코딩 된 데이터로 변환해야합니다.
다음 명령을 사용하여 오디오 파일을 텍스트 파일로 변환하십시오.
베이스 64 오디오 출력 파일 -W 0> 오디오 데이터 텍스트
전사 요청을 보내십시오
다음 코드를 사용하여 음성으로 전사 요청을 보내십시오.
로컬 파일 요청
규약
연설을 참조하십시오 : 자세한 내용은 API 엔드 포인트 인식.
동기 음성 인식을 수행하려면 사후 요청을 작성하고 적절한 요청 본문을 제공하십시오. 다음은 CURL을 사용한 게시물 요청의 예를 보여줍니다 . 이 예제는 Google Cloud Cloud Cli를 사용하여 프로젝트를 위해 설정된 서비스 계정에 대한 Access Token을 사용합니다. GCLOUD CLI 설치에 대한 지침, 서비스 계정으로 프로젝트 설정 및 액세스 토큰을 얻으려면 QuickStart를 참조하십시오.
curl -s -h "content-type : application/json"\ -h "권한 : bearer $ (gcloud auplic application-default print-access-token)"\ https : // speech.googleapis.com/v1/speech : 인식 \ -data ' < "config": < "encoding": "LINEAR16", "sampleRateHertz": 16000, "languageCode": "en-US", "모델": "비디오" >, "오디오": < "uri": "gs://cloud-samples-tests/speech/Google_Gnome.wav" >> '' '
요청 본문 구성에 대한 자세한 내용은 ReconsitionConfig 참조 문서를 참조하십시오.
요청이 성공하면 서버는 200 OK HTTP 상태 코드와 JSON 형식의 응답을 반환합니다
가다
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 지역 개발 환경에 대한 인증 설정을 참조하십시오.
FUNC 모델 선택 (W IO.작가, 경로 문자열) 오류 < ctx := context.Background() client, err := speech.NewClient(ctx) if err != nil < return fmt.Errorf("NewClient: %w", err) >고객을 연기하십시오.close () // path = "../testdata/google_gnome.Wav "데이터, err : = ioutil.readfile (path) err != nil < return fmt.Errorf("ReadFile: %w", err) >req : = & speechpb.인식 request< Config: &speechpb.RecognitionConfig< Encoding: speechpb.RecognitionConfig_LINEAR16, SampleRateHertz: 16000, LanguageCode: "en-US", Model: "video", >, 오디오 : & speciouspb.인정 부< AudioSource: &speechpb.RecognitionAudio_Content, >, > resp, err : = 클라이언트.ERR 인 경우 (CTX, Req)를 인식하십시오 != nil < return fmt.Errorf("Recognize: %w", err) >I의 경우 결과 : = 범위 resp.결과 < fmt.Fprintf(w, "%s\n", strings.Repeat("-", 20)) fmt.Fprintf(w, "Result %d\n", i+1) for j, alternative := range result.Alternatives < fmt.Fprintf(w, "Alternative %d: %s\n", j+1, alternative.Transcript) >> 반환 nil> 자바
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 지역 개발 환경에 대한 인증 설정을 참조하십시오.
/*** 주어진 오디오 파일의 전사를 선택한 모델과 동기식으로 수행합니다. * * * @param filename 오디오 파일의 경로는 전사 */ public static void transcribemodelselection (String filename)이 예외를 던집니다 < Path path = Paths.get(fileName); byte[] content = Files.readAllBytes(path); try (SpeechClient speech = SpeechClient.create()) < // Configure request with video media type RecognitionConfig recConfig = RecognitionConfig.newBuilder() // encoding may either be omitted or must match the value in the file header .setEncoding(AudioEncoding.LINEAR16) .setLanguageCode("en-US") // sample rate hertz may be either be omitted or must match the value in the file // header .setSampleRateHertz(16000) .setModel("video") .build(); RecognitionAudio recognitionAudio = RecognitionAudio.newBuilder().setContent(ByteString.copyFrom(content)).build(); RecognizeResponse recognizeResponse = speech.recognize(recConfig, recognitionAudio); // Just print the first result here. SpeechRecognitionResult result = recognizeResponse.getResultsList().get(0); // There can be several alternative transcripts for a given chunk of speech. Just use the // first (most likely) one here. SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0); System.out.printf("Transcript : %s\n", alternative.getTranscript()); >>마디.JS
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 지역 개발 환경에 대한 인증 설정을 참조하십시오.
// 베타 API의 Google Cloud 클라이언트 라이브러리를 가져옵니다/** ** TODO (Developer) : 원하는 기능을 사용할 때 새 버전의 API 버전 */const speech = require ( '@google-cloud/speech').v1p1beta1; const fs = 요구 사항 ( 'fs'); // 클라이언트 const 클라이언트 = 새 음성을 만듭니다.SpeechClient (); /*** todo (개발자) : 샘플을 실행하기 전에 다음 줄을 타협. */ // const filename = '오디오 파일의 로컬 경로, e.g. /Path/to/Audio.날것의'; // const model = '사용하는 모델, e.g. Phone_Call, 비디오, 기본값 '; // const encoding = '오디오 파일의 인코딩, e.g. linear16 '; // const samplerateHertz = 16000; // const languagecode = 'bcp-47 언어 코드, e.g. en-us '; const config = < encoding: encoding, sampleRateHertz: sampleRateHertz, languageCode: languageCode, model: model, >; const audio = < content: fs.readFileSync(filename).toString('base64'), >; const request = < config: config, audio: audio, >; // 오디오 파일에서 음성 감지 const [response] = 클라이언트가 기다립니다.인식 (요청); const 전사 = 반응.결과 .지도 (result => result.대안 [0].성적 증명서) .가입 ( '\ n'); 콘솔.log ( '전사 :', 전사);파이썬
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 지역 개발 환경에 대한 인증 설정을 참조하십시오.
def 전사 _model_selection (speech_file, model) : "" "주어진 오디오 파일을 선택한 모델과 동기식으로 전사."" ""Google에서.클라우드 가져 오기 음성 클라이언트 = 음성.Open (speech_file, "rb")이있는 SpeechClient () As Audio_file : content = audio_file.read () audio = speech.inlockitionAudio (content = content) config = speech.realitionConfig (인코딩 = 음성.인식 조치.오디오 엔코딩.linear16, sample_rate_hertz = 16000, language_code = "en-us", model = model,) 응답 = 클라이언트.i에 대한 인식 (config = config, audio = audio), enumerate (응답.결과) : 대안 = 결과.대안 [0] print ( "-" * 20) print (f "첫 번째 대안의 대안") print (f "transcript :") 추가 언어
씨#: 클라이언트 라이브러리 페이지의 C# 설정 지침을 팔로우 한 다음 .그물.
PHP: Client Libraries 페이지의 PHP 설정 지침을 따르고 PHP에 대한 Speech-to-Text 참조 문서를 방문하십시오.
루비: Client Libraries 페이지의 Ruby 설정 지침을 따르고 Ruby의 Speech-to-Text 참조 문서를 방문하십시오.
원격 파일 요청
자바
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 지역 개발 환경에 대한 인증 설정을 참조하십시오.
/*** 선택한 모델에서 원격 오디오 파일의 전사를 수행합니다. * * @param gcsuri 전사 할 원격 오디오 파일로가는 길. */ public static void transcribemodelselectiongcs (String gcsuri)는 예외를 던집니다 < try (SpeechClient speech = SpeechClient.create()) < // Configure request with video media type RecognitionConfig config = RecognitionConfig.newBuilder() // encoding may either be omitted or must match the value in the file header .setEncoding(AudioEncoding.LINEAR16) .setLanguageCode("en-US") // sample rate hertz may be either be omitted or must match the value in the file // header .setSampleRateHertz(16000) .setModel("video") .build(); RecognitionAudio audio = RecognitionAudio.newBuilder().setUri(gcsUri).build(); // Use non-blocking call for getting file transcription OperationFutureresponse = speech.longRunningRecognizeAsync(config, audio); while (!response.isDone()) < System.out.println("Waiting for response. "); Thread.sleep(10000); >목록 결과 = 응답.얻다().getResultsList (); // 여기에서 첫 번째 결과를 인쇄합니다. SpeechRecognitionResult result = 결과.get (0); // 주어진 연설 덩어리에 대한 몇 가지 대체 성적표가있을 수 있습니다. // 먼저 (가장 가능성이 높은) 여기에서 사용하십시오. SpeechRecognitionaltonative 대안 = 결과.getAlternativesList ().get (0); 체계.밖으로.printf ( "전사 : %s \ n", 대안.getTranscript ()); >>마디.JS
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 지역 개발 환경에 대한 인증 설정을 참조하십시오.
// 베타 API의 Google Cloud 클라이언트 라이브러리를 가져옵니다/** ** TODO (Developer) : 원하는 기능을 사용할 때 새 버전의 API 버전 */const speech = require ( '@google-cloud/speech').v1p1beta1; // 클라이언트 const 클라이언트 = 새 음성을 만듭니다.SpeechClient (); /*** todo (개발자) : 샘플을 실행하기 전에 다음 줄을 타협. */// const gcsuri = 'gs : // my-bucket/audio.날것의'; // const model = '사용하는 모델, e.g. Phone_Call, 비디오, 기본값 '; // const encoding = '오디오 파일의 인코딩, e.g. linear16 '; // const samplerateHertz = 16000; // const languagecode = 'bcp-47 언어 코드, e.g. en-us '; const config = < encoding: encoding, sampleRateHertz: sampleRateHertz, languageCode: languageCode, model: model, >; const audio = < uri: gcsUri, >; const request = < config: config, audio: audio, >; // 오디오 파일에서 음성을 감지합니다. const [응답] = 클라이언트를 기다립니다.인식 (요청); const 전사 = 반응.결과 .지도 (result => result.대안 [0].성적 증명서) .가입 ( '\ n'); 콘솔.log ( '전사 :', 전사);파이썬
speech-to-text로 인증하려면 응용 프로그램 기본 자격 증명을 설정하십시오. 자세한 내용은 지역 개발 환경에 대한 인증 설정을 참조하십시오.
DEF 전사 _model_selection_gcs (gcs_uri, model) : "" "주어진 오디오 파일을 선택한 모델과 비동기로 전사."" ""Google에서.클라우드 가져 오기 음성 클라이언트 = 음성.SpeechClient () Audio = Speech.realitionaudio (uri = gcs_uri) config = speech.realitionConfig (인코딩 = 음성.인식 조치.오디오 엔코딩.linear16, sample_rate_hertz = 16000, language_code = "en-us", model = model,) 작동 = 클라이언트.long_running_recognize (config = config, audio = audio) print ( "완료를위한 작동 대기 대기. ") 응답 = 작동.I의 결과 (시간 초과 = 90), 결과적으로 열거됩니다 (응답.결과) : 대안 = 결과.대안 [0] print ( "-" * 20) print (f "첫 번째 대안의 대안") print (f "transcript :") 추가 언어
씨#: 클라이언트 라이브러리 페이지의 C# 설정 지침을 팔로우 한 다음 .그물.
PHP: Client Libraries 페이지의 PHP 설정 지침을 따르고 PHP에 대한 Speech-to-Text 참조 문서를 방문하십시오.
루비: Client Libraries 페이지의 Ruby 설정 지침을 따르고 Ruby의 Speech-to-Text 참조 문서를 방문하십시오.
정리
이 튜토리얼에 사용되는 리소스에 대해 Google 클라우드 계정에 대한 요금이 부과되지 않으려면 리소스가 포함 된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하십시오.
프로젝트를 삭제하십시오
청구를 제거하는 가장 쉬운 방법은 자습서를 위해 만든 프로젝트를 삭제하는 것입니다.
- 프로젝트의 모든 것이 삭제됩니다. 이 튜토리얼에 기존 프로젝트를 사용한 경우 삭제하면 프로젝트에서 수행 한 다른 작업도 삭제합니다.
- 사용자 정의 프로젝트 ID가 손실되었습니다. 이 프로젝트를 만들 때 앞으로 사용하려는 사용자 정의 프로젝트 ID를 만들 수 있습니다. AppSpot과 같은 프로젝트 ID를 사용하는 URL을 보존하려면.com url, 전체 프로젝트를 삭제하는 대신 프로젝트 내에서 선택된 리소스 삭제.
주의: 프로젝트 삭제에는 다음과 같은 효과가 있습니다
여러 튜토리얼과 QuickStarts를 탐색하려는 경우 프로젝트를 재사용하면 프로젝트 할당량 제한을 초과하는 것을 피할 수 있습니다.
인스턴스를 삭제합니다
- Google Cloud 콘솔에서 이동하십시오 VM 인스턴스 페이지. VM 인스턴스로 이동하십시오
- 삭제하려는 인스턴스에 대한 확인란을 선택하십시오.
- 인스턴스를 삭제하려면 more_vert를 클릭하십시오 더 많은 행동, 딸깍 하는 소리 삭제, 그런 다음 지침을 따르십시오.
기본 네트워크의 방화벽 규칙을 삭제하십시오
- Google Cloud 콘솔에서 이동하십시오 방화벽 페이지. 방화벽으로 이동하십시오
- 삭제하려는 방화벽 규칙에 대한 확인란을 선택하십시오.
- 방화벽 규칙을 삭제하려면 삭제를 클릭하십시오 삭제.
무엇 향후 계획
- 오디오에 대한 타임 스탬프를 얻는 방법을 배우십시오.
- 오디오 파일에서 다른 스피커를 식별하십시오.
직접 시도하십시오
Google Cloud를 처음 접하는 경우 실제 시나리오에서 Speech-to-Text의 수행 방식을 평가하기 위해 계정을 작성하십시오. 신규 고객은 또한 실행, 테스트 및 배포 할 무료 크레딧으로 $ 300를받습니다.
피드백을 보내십시오
달리 명시된대로,이 페이지의 내용은 Creative Commons Attribution 4에 따라 라이센스가 부여됩니다.0 라이센스 및 코드 샘플은 Apache 2에 따라 라이센스가 부여됩니다.0 라이센스. 자세한 내용은 Google 개발자 사이트 정책을 참조하십시오. Java는 Oracle 및/또는 그 계열사의 등록 상표입니다.
마지막 업데이트 된 2023-05-19 UTC.
Google Docs : Audio to Text Transcription에서 전사하십시오
이 기사는 음성 타이핑 기능을 사용하여 Google 문서에서 전사하는 방법을 검토합니다. 이 무료 전사 도구는 일반 음성 타이핑 외에도 많은 작업에 유용합니다. 아이디어를 빠르게 작성하고 회의에서 거친 메모를 받고 연설을위한 스크립트를 만들 수 있습니다. 성적표는 여러 가지 이유로 유용합니다. 검색 가능하며 자막을 만들기 위해 사용할 수 있습니다’향후 참조를 위해 저장하기 쉽습니다.
Google Docs는 오디오 파일을 전사 할 수 있습니다?
많은 사람들이 Google 문서를 사용하여 오디오 파일을 전사 할 수 있다는 것을 아는 사람은 많지 않습니다’t 추천합니다! 대신 SPF와 같은 타사 도구를 사용하십시오.IO 오디오 파일에서 정확하고 빠른 전사를 얻으려면). 주요 목적 이외의 것을 위해 도구를 사용하면 이상적인 결과보다 덜 줄 것입니다. 음성 타이핑을 사용하여 오디오 파일에서 무료 성적표를 얻는 경우, 쓰기에는 구두점이 부족하거나 단어가 잘못되었거나 누락되었을 가능성이 있으며 나중에 상당한 편집이 필요합니다.
Google Docs Voice Typing 기능을 사용하면 몇 가지 이점이 있습니다
-무료 : Google Docs는 시작할 수수료가 필요하지 않습니다.
-편집 가능한 : Google 문서의 텍스트는 당신을 돕고있는 공동 작업자와 쉽게 수정하고 댓글을 달고 사용하기 쉽습니다
-쉽게 공유 할 수 있습니다 : 당신 이후’Google 문서에서 직접 작업하면
“공유하다” 전사를 친구와 동료에게 보낼 수 있습니다
Google Docs와 같은 무료 전사 도구 사용에 대한 단점 :
-번역 없음
-타임 스탬프가 없습니다
-자동 구두점이 없습니다 (구두로 말할 수 있습니다 “기간” 또는 “반점,” 그러나 문서는 문장 부호로 전사하지 않습니다. 음성 명령에 대한 자세한 내용은 여기를 참조하십시오).
-사용자 정의 사전 또는 자동 철자 수정이 없음 (이 기능을 원한다면 SPF를 사용하십시오.IO 및 나만의 자동 변환 데이터베이스 생성)
Google을 사용하는 방법’S 텍스트 음성 연설 도구
오디오 파일이 있으면 다음 단계에 따라 Google Docs에서 전사하십시오
- 새 문서 만들기 :
https : // docs에서 새 Google Doc 파일을 엽니 다.Google.com/document/
- 텍스트 음성 사용 :
도구에서 선택하십시오 “음성 타이핑”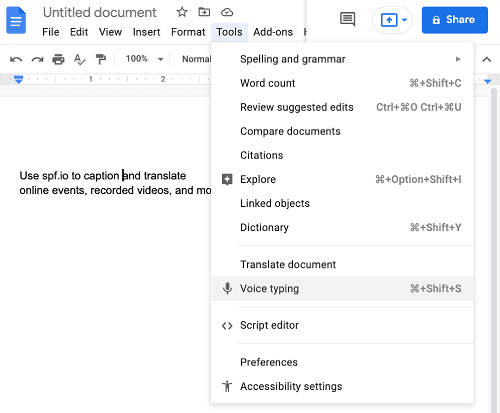
- 전사 언어 선택 :
마이크가 나타나면 표시된 언어 (이 경우 영어 (미국)) 옆의 드롭 다운 화살표를 사용하여 언어를 선택할 수 있습니다. 이중 언어 작업을 위해 Google 문서에서 전사 할 때’다른 언어를 말하고 싶을 때마다 새 언어로 전환하기 전에 마이크를 멈추고 끄는 것이 필요합니다.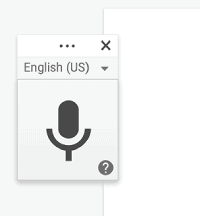
- 오디오 파일 전사 시작 :
다른 창에서 오디오 파일 재생을 시작하십시오 (헤드셋이 아닌 스피커에서 재생 중인지 확인하십시오!)). 가능한 빨리 Google 문서에서 마이크를 클릭하여 사운드를 캡처하십시오. 순서대로 해야하는 이유는 Google Docs 창에서 클릭하면 전사가 중지되기 때문입니다. 단점은 당신입니다’ll 전사를 시작하기 위해 Google 문서를 클릭하면 오디오 또는 비디오 파일의 첫 번째 부분을 잃습니다.
- 성적 증명서 편집 :
이것은 당신이이기는 이후이 과정에서 가장 시간이 많이 걸리는 부분입니다’G Google 문서에서 전사 할 때 구두점이 자동으로 추가됩니다. 당신은 할 수 있습니다’t 비디오/오디오가 전사 될 때 문서의 텍스트 편집 – 음성 타이핑은 커서를 넣을 때마다 텍스트를 추가합니다.
Google Docs Speech-to-Text를 사용하는 다른 방법 :
- 더 빨리 쓰십시오
- 회의에서 메모하십시오
- 연설을위한 스크립트를 만듭니다
SPF가있는 쉽고 정확한 오디오/비디오 전사.io
Google 문서에서 전사하는 프로세스는 무료이지만 많은 시간이 걸릴 수 있습니다 (결국 더 비싸 질 수 있습니다!)). SPF와 같은 타사 도구를 사용하는 것이 좋습니다.IO는 무료 도구보다 시간이 많이 걸리는 편집이 필요한 정확한 성적표를 얻으려면. 전사 할 비디오/오디오가 많은 경우 특히 필요합니다.
SPF와 함께.io, 성적표를 사용하여 캡션 및 자막을 만들 수도 있습니다. 올인원 도구에서 많은 옵션을 제공하기 때문에 텍스트를 60 개가 넘는 언어로 번역 할 수 있습니다! 또한 Zoom, Streamyard, YouTube 등과 같은 대부분의 플랫폼에 대한 라이브 캡션도 제공합니다.
Google 문서에서 전사를 시도하는 데 지쳤습니다? 프로세스를 단순화하고 SPF로부터 견적을 받으십시오.전사 프로젝트를위한 IO!
오디오 컨텐츠 전사 : 리소스 및 방법

오디오 콘텐츠를 전사하려면’바로 올바른 장소에 오세요. 타사 전사 서비스를 사용하든 DIY (직접 해보 든)’장단점을 측정하고 가장 적합한 옵션을 선택하는 것이 중요합니다.
오디오 전사의 이점
- 더 나은 사용자 경험을 만듭니다
- 인용 및 신용 가능성을 높이십시오
- 검색 엔진 최적화 부스트 (SEO)
- 청각 장애인이거나 청각이 어려운 사용자의 접근성 향상
또한 많은 비즈니스 및 조직이 있습니다 합법적으로 내용에 대한 성적 증명서를 작성해야합니다 미국 장애인 법 및 재활법 504 및 508 조에 근거. WCAG 2.0은 월드 와이드 웹 컨소시엄 (World Wide Web Consortium)이 시행하여 장애가있는 사람들을 포함하여 사용자가 디지털 컨텐츠에보다 액세스 할 수 있도록하는 일련의 지침입니다. WCAG 2.0 레벨 A, AA 및 AAA의 세 가지 수준의 규정 준수가 있습니다. 섹션 508은 WCAG 2를 준수하기 위해 개정되었습니다.0 레벨 A 및 AA. 가장 낮은 레벨에 따르면 레벨 A, 오디오 전용 콘텐츠에 전 사체가 권장됩니다.
우리’다른 자원을 제공합니다’ll 오디오 파일에서 전사하고 예산, 시간 및 특정 요구에 따라 가장 실용적인 선택을 결정하도록 도와야합니다. 행운을 빕니다. 그리고 행복한 전사!
DIY 전사
오디오를 수동으로 전사하는 것은 특히 더 긴 컨텐츠 형태의 콘텐츠가있을 때 어려운 작업이 될 수 있습니다. 일반적으로 콘텐츠의 실제 시간의 5-6 배가 걸립니다. 운 좋게도 프로세스를 단순화하는 데 사용할 수있는 무료 및 저렴한 도구가 많이 있습니다. 전사를 시작하기 전에 확인하십시오 명확하고 큰 오디오를 캡처하십시오. 이것은 성적표에서 적기 및들을 수없는 소리를 줄이는 데 도움이됩니다.
YouTube

YouTube에서 오디오 콘텐츠를 호스팅하는 경우 무료 자동 비디오 전사 도구를 활용할 수 있습니다. 이 도구는 오디오를 자동으로 텍스트로 전사하지만 많은 오류가 있음을 명심하십시오. YouTube에서 제작 한 사본’S 도구는 자체적으로 사용하기에는 너무 부정확합니다. 따라서, 그것은’S를 청소하는 것이 좋습니다 검색 엔진 결과 페이지 (SERP)에서 비디오 접근성 및 순위를 상하게합니다.
여기’S YouTube를 활용하는 방법’s 자동 비디오 성적표 :
- 비디오 관리자에서 비디오를 선택하고 클릭하십시오 편집> 자막 및 CC. 선택하다 자막 또는 CC를 추가하십시오 그리고 당신의 언어를 선택하십시오.
- 선택하다 타이밍을 전사하고 설정하십시오, 제공된 공간에 성적표를 입력하십시오. YouTube는 입력 할 때 비디오를 자동으로 일시 중지하여 더 빠르고 정확하게 전사 할 수 있습니다.
- 만족되면 선택하십시오 타이밍 설정. 이렇게하면 성적표가 비디오와 동기화됩니다.
마찬가지로, 사전에 전사를 만들어 YouTube에 업로드 할 수 있습니다
- 먼저, 성적표를 만듭니다 YouTube’서식에 대한 권장 사항.
- YouTube의 비디오 관리자로 이동하여 클릭하십시오 편집> 자막 및 CC. 자막 또는 CC 추가를 선택하고 언어를 선택하십시오.
- 선택하다 파일을 올리다, 선택하다 성적 증명서, 그리고 당신을 선택하십시오 .업로드를위한 txt 파일.
- 성적표가 업로드되면 클릭하십시오 타이밍 설정 비디오와 성적표를 동기화하고 닫힌 캡션을 작성하려면.
캡션 파일로 타이밍을 사용하여 나중에 Transcript 파일을 다운로드 할 수도 있습니다
- 성적 증명서를 다운로드하려는 비디오로 이동. 클릭하십시오 더 많은 행동 버튼 (3 수평 도트). 힌트 : 그것은’공유 버튼 옆에있는 S.
- 선택하십시오 성적 증명서 옵션.
- 타임 코드가있는 폐쇄 캡션의 전사가 자동으로 생성됩니다.
ASR 소프트웨어

ASR이라고도하는 자동 음성 인식은 인간의 음성을 집어 들고 텍스트로 변환하는 기술입니다. 미디어를 ASR 소프트웨어에 업로드 할 수 있으며 자동으로 오디오를 텍스트로 전사합니다. 이 방법은 여전히 많은 오류가 있지만’처음부터 시작하는 것보다 부정확 한 전 사자를 정리하기가 훨씬 쉽고 빠릅니다.
Express Scribe, EuriScribe 및 Dragon NaturallySpeak와 같은 적은 비용으로 무료 또는 소액 비용으로 제공되는 전사 소프트웨어에 대한 많은 옵션이 있습니다.
구글 문서
Google은 문서를 무료 전사 소프트웨어로 전환 할 수있는 멋진 기능을 제공합니다. 당신이하지 않으면’t gmail 계정이 있으면 무료로 가입 할 수 있습니다. 기존 계정이있는 경우 이미라는 기능에 액세스 할 수 있습니다 구글 문서; Google Docs는 웹 브라우저에서 텍스트 문서를 만들 수있는 단어 처리 도구입니다. 음성 타이핑을 사용하여 Google 보이스 전사는 오디오에서 텍스트 전사를 생성 할 수 있습니다. 다른 수동 전사 도구와 마찬가지로 오류가 있으므로 사용하기 전에 정리하십시오.
다음 단계에 따라 성적 증명서를 작성하십시오
- 선택한 브라우저를 사용하여 Google Docs 웹 사이트를 방문하고 새 문서를 시작하십시오.
- 클릭 도구 그리고 선택하십시오 음성 타이핑. 음성 인식을 가능하게합니다.
- 클릭하십시오 마이크로폰 활성화하려면 왼쪽의 아이콘 음성 타이핑. Google은 Word 문서에 말하는 모든 것을 전사합니다.
iOS/Android

오디오 콘텐츠를 전사하는 또 다른 방법은 스마트 폰을 사용하는 것입니다. Google Docs와 유사하게 마이크는 오디오에서 픽업하여 텍스트로 전사합니다. 휴대 전화의 마이크가 배경 소음이 적기 때문에 스마트 폰에서 전사하는 것은 Google 문서보다 조금 더 잘 작동하는 경향이 있습니다. 그러나 여전히 그렇습니다’t 고품질 마이크와 비교하십시오. 스마트 폰에 녹음이 이겼습니다’t 높은 정확도를 보장하므로 최종 성적표를 정리해야합니다.
다음은 스마트 폰을 사용하여 오디오를 텍스트로 전사하는 방법에 대한 단계별 지침입니다
- a 워드 프로세싱 앱 스마트 폰에서.
- 스마트 폰의 키보드에서 마이크로폰 버튼이 있고 녹음이 시작됩니다.
- 컴퓨터 또는 기타 장치 근처에 휴대 전화를 잡고 비디오를 재생하십시오. 휴대 전화는 오디오를 자동으로 텍스트로 전환합니다.
장점 대. DIY 사본의 단점
프로
- 더 예산 친화적입니다
- 더 짧은 콘텐츠에 좋습니다
단점
- 생성하는 데 시간이 많이 걸립니다
- 노동 집약적
- 낮은 정확도 수준
전사 서비스
텍스트에 오디오 콘텐츠를 전사하는 또 다른 옵션은 타사 전사 서비스를 사용하는 것입니다. 만약 너라면’고품질의 정확한 성적 증명서를 찾고, 이것은 확실히 갈 길입니다!
3 플레이 미디어 제공 a 3 단계 전사 과정 기술과 인간 전사자를 모두 사용하여 99.6% 정확도. 오디오 파일이 컨텐츠가 어려운 컨텐츠로 구성되거나 배경 노이즈가 있거나 악센트가 포함되면 정확도가 감소합니다. ASR은 일반적으로 60-70% 정확도를 제공하므로 인간 전사자의 사용은 다른 전사 옵션과 3 플레이를 구별합니다.
특허받은 기술은 ASR을 사용하여 거친 성적표를 자동으로 생성합니다. 이는 단어와 문법이 잘못된 경우에도 정확한 타이밍을 만드는 데 유용합니다. 독점 소프트웨어를 사용하여 전사자는 성적 증명서를 통해 편집합니다. 우리의 모든 전사자들은 엄격한 인증 과정을 겪고 영어 문법을 강력하게 이해하고 있으며, 이는 콘텐츠의 모든 뉘앙스를 이해하는 데 중요합니다. 편집 프로세스 후 파일은 품질 보증이라는 최종 검토를 거칩니다. 귀하의 파일은 최고 편집자에 의해 검토됩니다.
우리가 제공하는 기능 중 하나는 다음과 같습니다 3 플레이 대화식 전 사체. 이 기능은 사용자가 비디오를 검색하고, 단어를 클릭하여 탐색하고, 오디오와 함께 읽음으로써 비디오와 상호 작용할 수 있습니다. 대화식 성적표는 콘텐츠에 더 액세스 할 수있게하고 사용자 경험을 향상시킵니다.
장점 대. 전사 서비스 사용의 단점
프로
- 높은 정확도 수준
- 더 듬직 해요
- 대량의 콘텐츠를 처리합니다
- 고유 한 도구에 대한 액세스
- 숙련 된 직원에 대한 접근
단점
- 더 비싼
전사 모범 사례
이제 수동 전사 대 전사 서비스에 대한 이해가 더 좋았으므로 정보에 근거한 결정을 내릴 수 있습니다. 어떤 옵션을 선택하든 상관 없습니다’방법을 아는 것이 중요합니다 사본을 최대한 활용하십시오.
- 문법과 구두점: 성적표에 오류가 없어서 읽기 쉬운 오류가 있는지 확인하십시오.
- 스피커 식별: 스피커 레이블을 사용하여 말하는 사람, 특히 여러 스피커가있을 때.
- 비전식 소리: 성적표에서 비 연설적 인 사운드를 전달합니다. 이들은 일반적으로 [Square Brackets]로 표시됩니다.
- 구두: 가능한 한 구두에 가깝게 내용을 전사하십시오. 다음과 같은 필러 단어를 제외하십시오 “음” 또는 “좋다” 그들이 아니라면’의도적으로 오디오에 포함됩니다.
더 배우고 싶습니다?

이 게시물은 원래 2018 년 8 월 30 일 Samantha Sauld가 게시했으며 그 이후로 업데이트되었습니다.
Google Cloud 콘솔을 사용하여 텍스트로 연설 전사
이 QuickStart는 Cloud Speech-to-Text 콘솔을 소개합니다. 이 QuickStart에서는 전사를 생성하고 개선하고 자신의 응용 프로그램에 대해 Speech-to-Text API와 함께이 구성을 사용하는 방법을 배웁니다.
콘솔 대신 REST API를 사용하여 요청을 보내고 응답을받는 방법을 배우려면 Page Page 이전을 참조하십시오.
시작하기 전에
Speech-to-Text 콘솔 사용을 시작하기 전에 Google Cloud 플랫폼 콘솔에서 API를 활성화해야합니다. 아래 단계는 다음과 같은 조치를 안내합니다
- 프로젝트에서 음성-텍스트를 활성화하십시오.
- Speech-to-Text에 청구가 활성화되어 있는지 확인하십시오.
Google 클라우드 프로젝트를 설정하십시오
- Google Cloud 콘솔에 로그인하십시오
- 프로젝트 선택기 페이지로 이동 기존 프로젝트를 선택하거나 새 프로젝트를 만들 수 있습니다. 프로젝트 작성에 대한 자세한 내용은 Google Cloud 플랫폼 문서를 참조하십시오.
- 새 프로젝트를 작성하면 청구 계정을이 프로젝트에 연결하라는 메시지가 표시됩니다. 기존 프로젝트를 사용하는 경우 청구가 활성화되어 있는지 확인하십시오. 프로젝트에 청구가 활성화되어 있는지 확인하는 방법에 대해 알아보십시오메모: 청구서가 Speech-to-Text API를 사용하도록해야하지만 무료 할당량을 초과하지 않으면 청구되지 않습니다. 자세한 내용은 가격 책정 페이지를 참조하십시오.
- 프로젝트를 선택하고 청구 계정에 연결하면 Speech-to-Text API를 활성화 할 수 있습니다. 가십시오 제품 및 리소스 검색 페이지 상단의 막대를 입력하고 “연설”.
- 선택하십시오 클라우드 음성 텍스트 API 결과 목록에서.
- 프로젝트에 연결하지 않고 Speech-to-Text를 시도하려면 다음을 선택하십시오 이 API를 사용해보십시오 옵션. 프로젝트와 함께 사용하기 위해 Speech-to-Text API를 사용하려면 클릭하십시오 할 수 있게 하다.
전사를 만듭니다
Google Cloud 콘솔을 사용하여 새 전사를 만듭니다
오디오 구성
- 열기 음성-텍스트 개요.
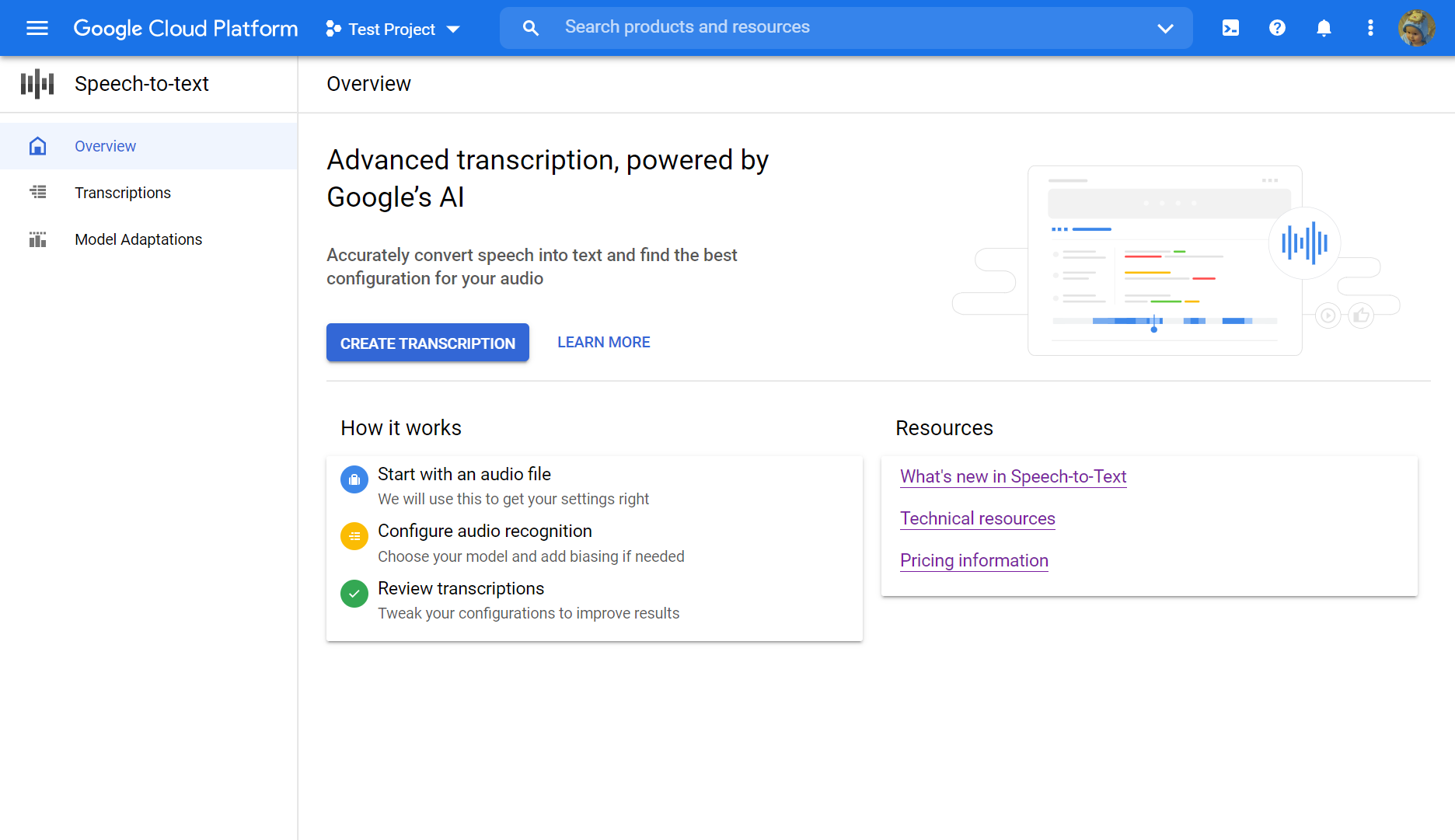
- 딸깍 하는 소리 전사를 만듭니다.
- 콘솔을 처음 사용하는 경우 클라우드 스토리지의 위치를 선택하여 구성 및 전사를 저장해야합니다.
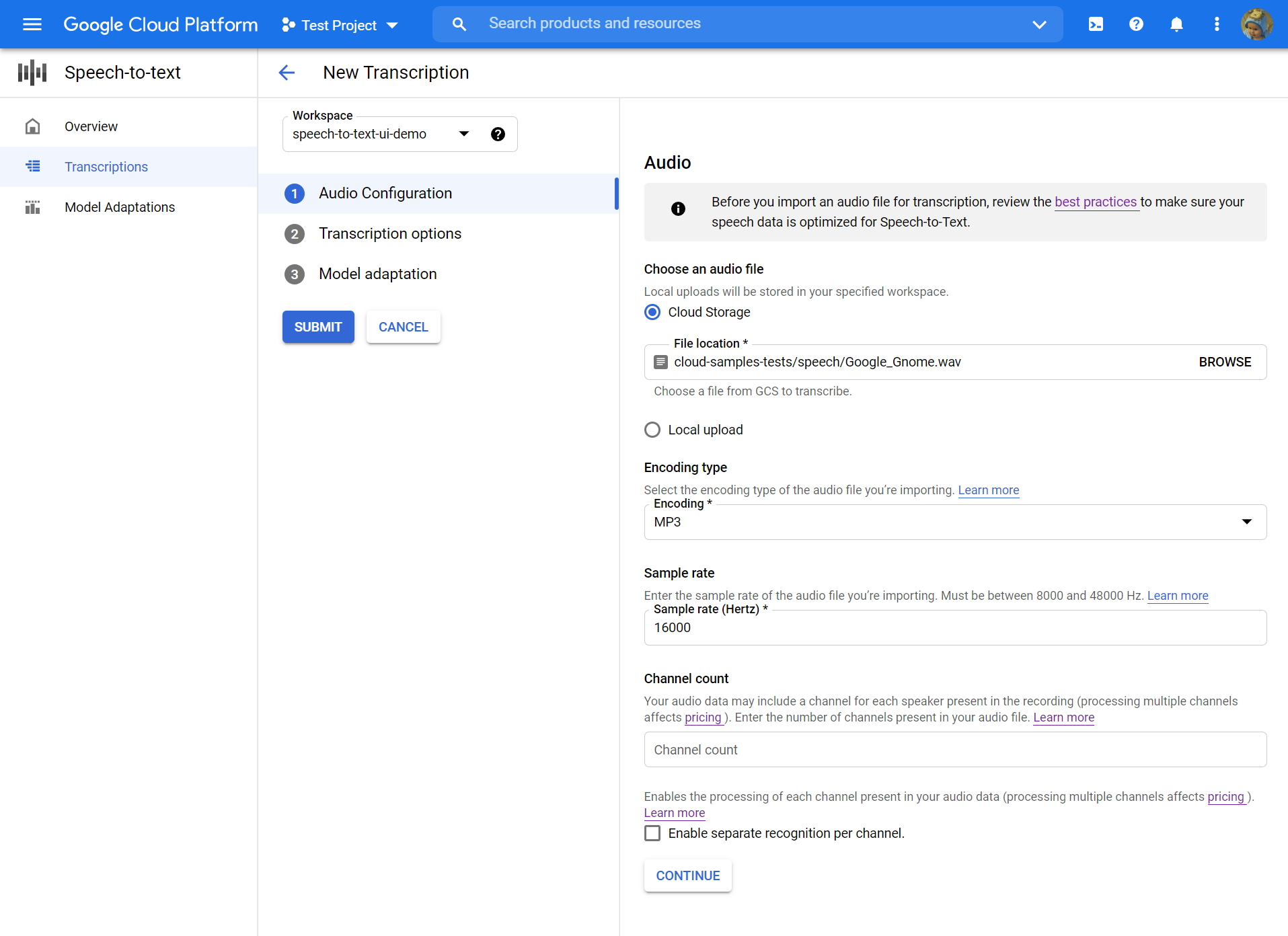
- 콘솔을 처음 사용하는 경우 클라우드 스토리지의 위치를 선택하여 구성 및 전사를 저장해야합니다.
- 에서 전사를 만듭니다 페이지, 소스 오디오 파일을 업로드하십시오. 클라우드 스토리지에 이미 저장된 파일을 선택하거나 지정된 클라우드 스토리지 대상에 새 파일을 업로드 할 수 있습니다.
- 업로드 된 오디오 파일을 선택하십시오 인코딩 유형.
- 지정하십시오 샘플 속도.
- 딸깍 하는 소리 계속하다. 당신은 데려 갈 것입니다 전사 옵션.
전사 옵션

- 선택하십시오 언어 코드 소스 오디오의. 이것은 녹음에서 사용되는 언어입니다.
- 선택하십시오 전사 모델 파일에서 사용하고 싶습니다. 기본 옵션은 사전 선택되며 일반적으로 변경이 필요하지 않지만 오디오 유형과 모델을 일치 시키면 정확도가 높아질 수 있습니다. 모델 비용은 다양합니다.
- 딸깍 하는 소리 계속하다. 당신은 데려 갈 것입니다 모델 적응.
모델 적응 (선택 사항)
소스 오디오가 희귀 단어, 적절한 이름 또는 독점 용어와 같은 것이 포함되어 있고 인식에 문제가 발생하면 모델 적응이 도움이 될 수 있습니다.

- 확인하다 모델 적응을 켜십시오.
- 선택하다 일회성 적응 자원.
- 관련성을 추가하십시오 실없는 말 그리고 그들에게 가치 부스트 가치.
- 왼쪽 열에서 클릭하십시오 제출하다 전사를 만듭니다.
전사를 검토하십시오
오디오 파일의 크기에 따라 전사는 생성하는 데 몇 분에서 몇 시간이 걸릴 수 있습니다. 전사가 만들어지면 검토 할 준비가되었습니다. 타임 스탬프로 테이블을 정렬하면 최근의 전사를 쉽게 찾을 수 있습니다.
- 클릭하십시오 이름 검토하고 싶은 전사의.
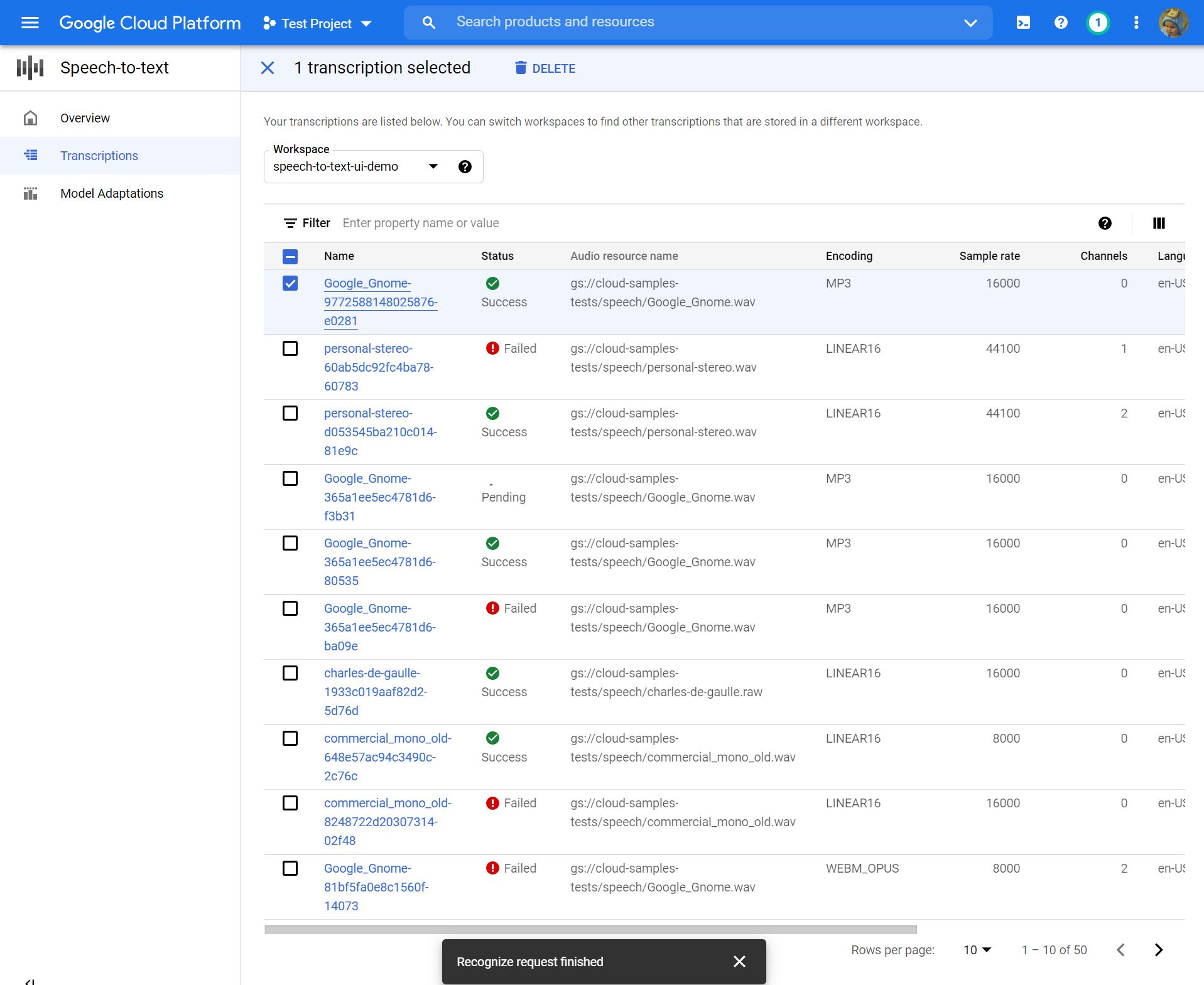
- 비교 전사 오디오 파일로 텍스트
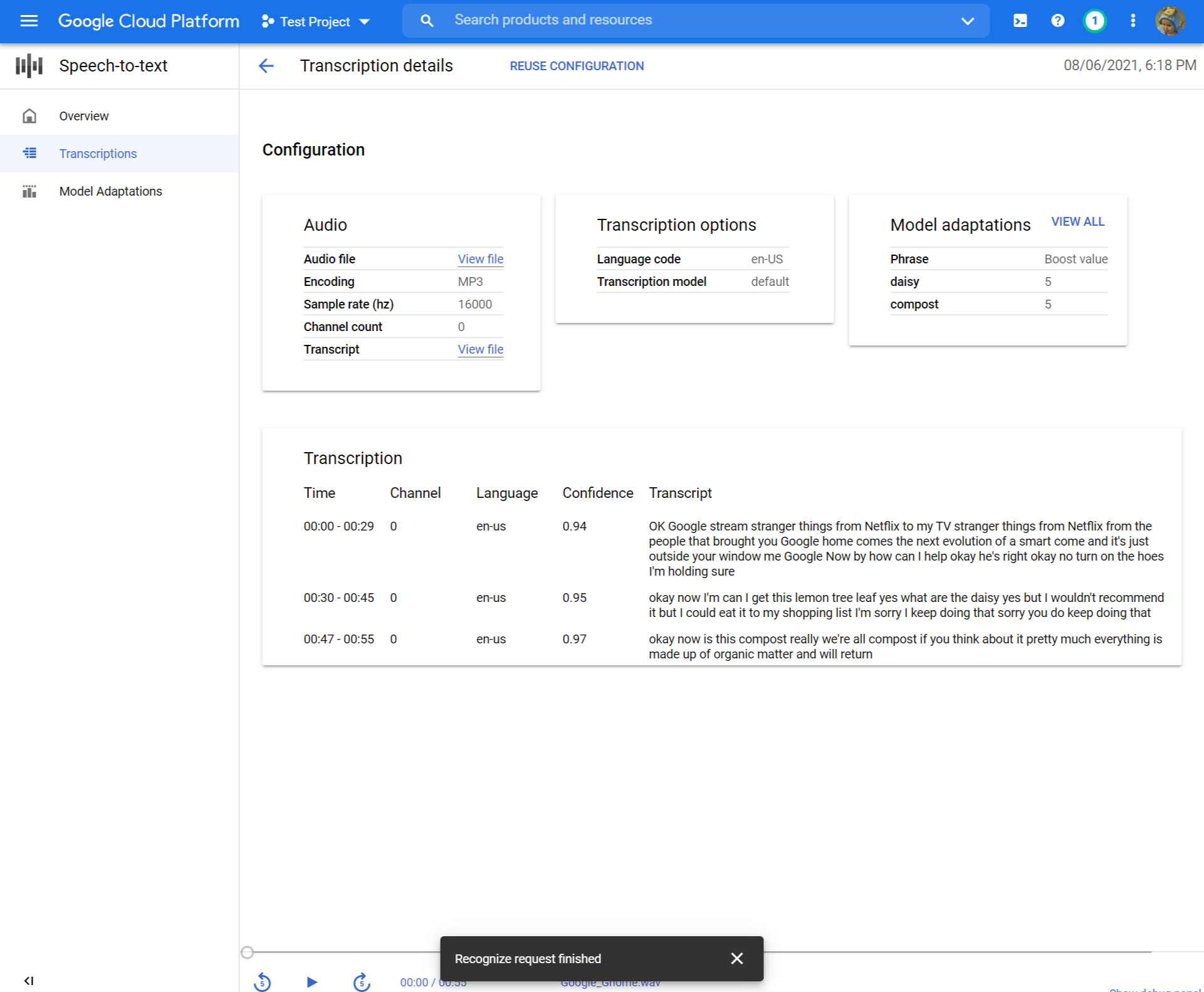
- 변경하려면 클릭하십시오 구성 재사용. 이것은 당신을 당신에게 데려 올 것입니다 전사를 만듭니다 사전 선택된 동일한 옵션으로 흐르고 몇 가지를 변경하고 새 전사를 만들고 결과를 비교할 수 있습니다.
무엇 향후 계획
- 짧은 오디오 파일 전사 연습.
- 음성 인식을 위해 긴 오디오 파일을 배치하는 방법에 대해 알아보십시오.
- 마이크에서 스트리밍 오디오를 전사하는 방법에 대해 알아보십시오.
- Speech-to-Text Client Library를 사용하여 선택한 언어로 Speech-to-Text를 시작하십시오.
- 샘플 응용 프로그램을 통해 작업하십시오.
- 최상의 성능, 정확도 및 기타 팁은 모범 사례 문서를 참조하십시오.
피드백을 보내십시오
달리 명시된대로,이 페이지의 내용은 Creative Commons Attribution 4에 따라 라이센스가 부여됩니다.0 라이센스 및 코드 샘플은 Apache 2에 따라 라이센스가 부여됩니다.0 라이센스. 자세한 내용은 Google 개발자 사이트 정책을 참조하십시오. Java는 Oracle 및/또는 그 계열사의 등록 상표입니다.
마지막 업데이트 된 2023-05-16 UTC.

