
AMD FX-8150 검토
보다 정확하게 우리는 AMD FX-8150, PHENOM II X6 1100T 및 CORE I7-2600에서 3을 비교했습니다.6GHz 주파수 및 2 개의 활성 계산 코어 만. 실험의 순도를 보장하기 위해 모든 전원 절약 및 자동 청소 기술을 비활성화했습니다. 우리는 Sisoft Sandra 2011 Suite에서 간단한 합성 벤치 마크 세트를 사용했는데, 여기서 K10 Microarchitecture는 SSE3 이상의 모든 지침을 수동으로 비활성화했습니다’t 그들을 지원하십시오.
요약
AMD FX-8150 프로세서는 Phenom II X6 1100T 및 Core I7-2600 프로세서와 비교되었습니다. 비교는 3의 빈도로 수행되었다.6GHz 및 2 개의 활성 계산 코어 만 있습니다. 실험의 정확성을 보장하기 위해 모든 전력 절약 및 자동 청소 기술이 비활성화되었습니다. Sisoft Sandra 2011 Suite의 합성 벤치 마크는 SSE3 이외의 지침과 함께 사용되었습니다.
키 포인트
1. 비교에는 AMD FX-8150, PHENOM II X6 1100T 및 CORE I7-2600 프로세서가 포함되었습니다.
2. 실험은 3의 빈도로 수행되었다.2 개의 활성 계산 코어 만있는 6GHz.
삼. 전력 절약 및 자동 청소 기술은 정확성을 위해 비활성화되었습니다.
4. Sisoft Sandra 2011 Suite의 합성 벤치 마크가 사용되었습니다.
5. SSE3 이외의 지침은 K10 미세 구조 제한으로 인해 수동으로 비활성화되었습니다.
1. 검토에서 얼마나 많은 프로세서를 비교했는지?
검토는 AMD FX-8150, Phenom II X6 1100T 및 Core i7-2600을 비교했습니다.
2. 프로세서가 어떤 빈도를 비교했는지?
프로세서를 3의 빈도로 비교 하였다.6GHz.
삼. 비교에 얼마나 많은 활성 계산 코어가 사용되었는지?
비교에는 2 개의 활성 계산 코어 만 사용되었습니다.
4. 실험을 위해 어떤 기술이 비활성화되었는지?
모든 전력 절약 및 자동 청소 기술은 정확성을 위해 비활성화되었습니다.
5. 어떤 벤치 마크 스위트가 사용되었는지?
Sisoft Sandra 2011 Suite는 벤치 마크에 사용되었습니다.
6. SSE3 이외의 지시가 장애가있는 이유는 무엇입니까??
SSE3 이외의 지침은 K10 Microarchitecture가 지원하지 않기 때문에 수동으로 비활성화되었습니다.
7. AMD FX-8150 프로세서가 몇 개가 있습니까??
AMD FX-8150 프로세서에는 8 개의 코어가있어 옥타 코어 프로세서가됩니다.
8. 코어 i3-8100의 기본 클럭 속도는 얼마입니까??
코어 i3-8100의 기본 클럭 속도는 3입니다.6GHz.
9. FX-8150에 얼마나 많은 캐시가 있습니까??
FX-8150에는 총 8192kb의 캐시가 있으며 384kb의 L1 캐시, 코어 당 256k의 L2 캐시 및 6MB의 공유 L3 캐시가 있습니다.
10. 핵심 i3-8100의 리소그래피는 무엇입니까??
코어 i3-8100의 리소그래피는 14 nm입니다.
11. FX-8150의 최대 온도는 얼마입니까??
FX-8150의 최대 코어 온도는 61 ° C입니다.
12. 코어 i3-8100의 소켓 유형은 무엇입니까??
코어 i3-8100의 소켓 유형은 FCLGA1151입니다.
13. Core i3-8100은 64 비트를 지원합니다?
예, Core i3-8100은 64 비트를 지원합니다.
14. 핵심 i3-8100을 지원하는 명령 세트 확장 기능?
핵심 i3-8100은 Intel SSE4를 지원합니다.1, Intel SSE4.2 및 인텔 AVX2 명령어 세트 확장.
15. FX-8150에는 터보 부스트 기술이 있습니까??
아니요, FX-8150에는 터보 부스트 기술이 없습니다.
AMD FX-8150 검토
보다 정확하게 우리는 AMD FX-8150, PHENOM II X6 1100T 및 CORE I7-2600에서 3을 비교했습니다.6GHz 주파수 및 2 개의 활성 계산 코어 만. 실험의 순도를 보장하기 위해 모든 전원 절약 및 자동 청소 기술을 비활성화했습니다. 우리는 Sisoft Sandra 2011 Suite에서 간단한 합성 벤치 마크 세트를 사용했는데, 여기서 K10 Microarchitecture는 SSE3 이상의 모든 지침을 수동으로 비활성화했습니다’t 그들을 지원하십시오.
AMD FX-8150 vs Intel Core i3-8100
Core I3-8100 및 FX-8150 프로세서 시장 유형 (데스크탑 또는 노트북), 건축, 판매 시작 시간 및 가격 비교.
| 성능 순위에 배치하십시오 | 1163 | 1283 |
| 인기로 배치하십시오 | 62 | 데이터가 없습니다 |
| 돈에 대한 가치 | 9.36 | 1.70 |
| 시장 세그먼트 | 데스크탑 프로세서 | 데스크탑 프로세서 |
| 시리즈 | 인텔 코어 i3 | 데이터가 없습니다 |
| 아키텍처 코드 이름 | 커피 레이크 (2017-2019) | Zambezi (2011-2012) |
| 출시일 | 2017 년 9 월 24 일 (5 세) | 2011 년 10 월 12 일 (11 세) |
| 발사 가격 (MSRP) | $ 117 | 데이터가 없습니다 |
| 현재 가격 | $ 138 (1.2X MSRP) | $ 102 |
돈에 대한 가치
가격 당 성과가 높아지는 것이 더 좋습니다.
기술 사양
코어 i3-8100 및 FX-8150 코어 수, 스레드 수, 기본 주파수 및 터보 부스트 시계, 리소그래피, 캐시 크기 및 승수 잠금 상태와 같은 기본 매개 변수. 이 매개 변수는 CPU 속도에 대해 간접적으로 말하지만보다 정확한 평가를 위해서는 테스트 결과를 고려해야합니다.
| 물리적 코어 | 4 (쿼드 코어) | 8 (옥타 코어) |
| 스레드 | 4 | 8 |
| 베이스 클럭 속도 | 삼.6GHz | 삼.6GHz |
| 클럭 속도를 높이십시오 | 삼.6GHz | 4.2GHz |
| 버스 지원 | 4 × 8 gt/s | 데이터가 없습니다 |
| L1 캐시 | 64K (코어 당) | 384 KB |
| L2 캐시 | 256K (코어 당) | 8192 KB |
| L3 캐시 | 6 MB (공유) | 8192 KB |
| 칩 리소그래피 | 14 nm | 32 nm |
| 다이 크기 | 126 mm 2 | 315 mm 2 |
| 최대 코어 온도 | 100 ° C | 61 ° C |
| 최대 케이스 온도 (Tcase) | 72 ° C | 데이터가 없습니다 |
| 트랜지스터 수 | 데이터가 없습니다 | 1,2 억 |
| 64 비트 지원 | + | + |
| Windows 11 호환성 | + | – |
| 잠금 해제 된 승수 | – | 1 |
| P0 Vcore 전압 | 데이터가 없습니다 | 최소 : 1.0125 V- 최대 : 1.4125 v |
호환성
코어 i3-8100 및 FX-8150에 대한 정보 다른 컴퓨터 구성 요소와의 호환성 : 마더 보드 (소켓 유형 찾기), 전원 공급 장치 (전원 소비를 찾음) 등. 향후 컴퓨터 구성을 계획하거나 기존 컴퓨터 구성을 업그레이드 할 때 유용합니다. 일부 프로세서의 전력 소비는 오버 클로킹 없이도 공칭 TDP를 초과 할 수 있습니다. 일부는 마더 보드가 CPU 전력 매개 변수를 조정할 수 있다는 점을 감안할 때 선언 된 열을 두 배로 늘릴 수도 있습니다.
| 구성에서 CPU 수 | 1 | 1 |
| 소켓 | FCLGA1151 | am3+ |
| 전력 소비 (TDP) | 65 와트 | 125 와트 |
기술 및 확장
Core I3-8100 및 FX-8150에서 지원하는 기술 솔루션 및 추가 지침. 특정 기술이 필요한 경우이 정보가 필요할 것입니다.
| 명령 세트 확장 | Intel® SSE4.1, Intel® SSE4.2, Intel® AVX2 | 데이터가 없습니다 |
| aes-ni | + | + |
| FMA | 데이터가 없습니다 | + |
| AVX | + | + |
| 향상된 스피드 스텝 (EIST) | + | 데이터가 없습니다 |
| 향상된 스피드 스텝 (EIST) | + | 데이터가 없습니다 |
| 터보 부스트 기술 | – | 데이터가 없습니다 |
| 하이퍼 스레딩 기술 | – | 데이터가 없습니다 |
| TSX | – | 데이터가 없습니다 |
| 유휴 상태 | + | 데이터가 없습니다 |
| 열 모니터링 | + | 데이터가 없습니다 |
| SIPP | – | 데이터가 없습니다 |
보안 기술
핵심 I3-8100 및 FX-8150 기술은 예를 들어 해킹으로부터 보호함으로써 보안 개선을 목표로합니다.
| txt | – | 데이터가 없습니다 |
| edb | + | 데이터가 없습니다 |
| 보안 키 | + | 데이터가 없습니다 |
| MPX | + | 데이터가 없습니다 |
| 신원 보호 | + | 데이터가 없습니다 |
| sgx | 예, Intel® Me | 데이터가 없습니다 |
| OS 가드 | + | 데이터가 없습니다 |
가상화 기술
Core I3-8100 및 FX-8150에서 지원하는 가상 기계 속도 업 기술은 여기에 열거됩니다.
| AMD-V | 데이터가 없습니다 | + |
| VT-D | + | 데이터가 없습니다 |
| VT-X | + | 데이터가 없습니다 |
| ept | + | 데이터가 없습니다 |
메모리 사양
Core I3-8100 및 FX-8150에서 지원하는 RAM의 유형, 최대량 및 채널 수량. 마더 보드에 따라 더 높은 메모리 주파수가 지원 될 수 있습니다.
| 지원되는 메모리 유형 | DDR4-2400 | DDR3 |
| 최대 메모리 크기 | 64GB | 데이터가 없습니다 |
| 최대 메모리 채널 | 2 | 데이터가 없습니다 |
| 최대 메모리 대역폭 | 37.5GB/s | 데이터가 없습니다 |
| ECC 메모리 지원 | + | 데이터가 없습니다 |
그래픽 사양
통합 GPU의 일반 매개 변수.
| 통합 그래픽 카드 | 인텔 UHD 그래픽 630 | 데이터가 없습니다 |
| 맥스 비디오 메모리 | 64GB | 데이터가 없습니다 |
| 빠른 동기화 비디오 | + | 데이터가 없습니다 |
| 명확한 비디오 | + | 데이터가 없습니다 |
| 클리어 비디오 HD | + | 데이터가 없습니다 |
| 그래픽 최대 주파수 | 1.1GHz | 데이터가 없습니다 |
| 침입 3D | + | 데이터가 없습니다 |
그래픽 인터페이스
코어 i3-8100 및 FX-8150 통합 GPU의 사용 가능한 인터페이스 및 연결.
| 지원되는 디스플레이 수 | 삼 | 데이터가 없습니다 |
그래픽 이미지 품질
Core I3-8100 및 FX-8150 통합 GPU에 의해 지원되는 최대 디스플레이 해상도, 다른 인터페이스에 대한 해상도를 포함하여.
| 4K 해상도 지원 | + | 데이터가 없습니다 |
| HDMI에 대한 최대 분해능 1.4 | 4096×2304@24Hz | 데이터가 없습니다 |
| EDP에 대한 최대 해상도 | 4096×2304@60Hz | 데이터가 없습니다 |
| DisplayPort에 대한 최대 해상도 | 4096×2304@60Hz | 데이터가 없습니다 |
그래픽 API 지원
Core i3-8100 및 FX-8150 통합 GPU가 지원하는 API, 때때로 API 버전이 포함되어 있습니다.
| Directx | 12 | 데이터가 없습니다 |
| Opengl | 4.5 | 데이터가 없습니다 |
주변 장치
코어 i3-8100 및 FX-8150에서 지원하는 주변 장치의 사양 및 연결.
| PCIE 버전 | 삼.0 | N/A |
| PCI Express 차선 | 16 | 데이터가 없습니다 |
합성 벤치 마크 성능
프로세서의 다양한 벤치 마크 결과. 전체 점수는 0-100 범위의 지점에서 측정되며 더 높습니다.
합성 벤치 마크 점수를 결합했습니다
이것은 우리의 결합 된 벤치 마크 성능 등급입니다. 우리는 정기적으로 결합 알고리즘을 개선하고 있지만, 인식 된 불일치를 발견하면 의견 섹션에서 자유롭게 발언하십시오. 일반적으로 우리는 일반적으로 문제를 빠르게 해결합니다.
AMD FX-8150 검토

대기가 마침내 끝났습니다
거기’2007 년 7 월에 새로운 CPU 마이크로 아키텍처에 대해 처음 들어 본 이후로 불도저를 둘러싼 많은 혼란이있었습니다. 우리는 그것이 GPU를 통합 할 모듈 식 CPU 디자인이라고 들었습니다. 퓨전 프로세서에는 두 가지 맛이있을 것입니다. 하나는 고성능 CPU를위한 불도저와 저전력 시스템을위한 다른 밥캣 디자인을 기반으로합니다.
그 대부분은 사실로 판명되었습니다’불도저 CPU의 그래픽 유닛이 없으며 Bobcat과 Bulldozer의 간격을 연결하는 Llano 프로세서 설계가 있습니다.
더 혼란스러운 것은 불도저가 가정용으로의 의미인지. 2010 년 8 월 브리핑에서 우리는, ‘[Bulldozer]는 33 % 더 많은 코어를 제공하고 Magny-Cours와 동일한 전력 봉투에서 처리량이 약 50 % 증가합니다’, AMD’현재 최고급 오피스 디자인.
불도저 프로세서는 BIOS 업데이트를 통해 G34 마더 보드에 들어가야하며 새로운 Llano 프로세서가 데스크탑 사용을위한 것이 었음을 이야기했습니다. 얼마 지나지 않아 불도저는 서버 및 워크 스테이션 CPU 설계뿐만 아니라 데스크탑으로 확인되었습니다. 몇 달의 지연 후’S가 마침내 판매 중입니다.
이제 우리는 불도저 CPU를 테스트 할 수 있습니다 (또한 참석자 리뷰어’ 가이드, 인터뷰 및 나머지는 모두), 우리는 그것을 둘러싼 모든 신화와 소문을 없애 버릴 수 있습니다. FX-8150은 우리가 첫 번째 프로세서입니다’VE를 보았습니다’불도저 CPU 아키텍처를 기반으로 한 S’공칭 주파수 3을 가진 새로운 라인업의 아빠.6GHz (최대 4 증가.2GHz).
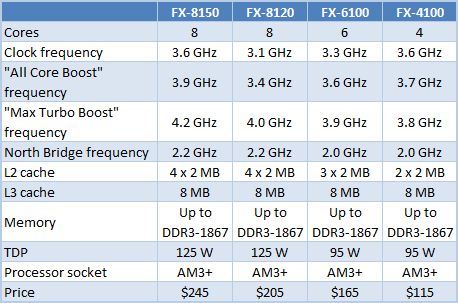
FX-8150은 출시시 3 개의 다른 FX 브랜드 프로세서와 결합되며 오늘 이후 어느 시점에 도달 할 수있는 또 다른 3 가지 모델이 있습니다. 여기’우리가 알고있는 모델을 요약하는 테이블, 우리가 계속해서 그들에 대해 더 이야기하기 전에.
| AMD FX 시리즈 프로세서 | |||||||||
| 이름 | 공칭 주파수 | 터보 코어 주파수 | 맥스 터보 주파수 | TDP | 코어 | 레벨 2 캐시 | 레벨 3 캐시 | 노스 브리지 주파수 | SRP |
| FX-8150* | 삼.6GHz | 삼.9GHz | 4.2GHz | 125W | 8 | 8MB | 8MB | 2.2GHz | $ 245 |
| FX-8120* | 삼.1GHz | 삼.4GHz | 4GHz | 95W 및 125W | 8 | 8MB | 8MB | 2.2GHz | $ 205 |
| FX-8100 | 2.8GHz | 삼.1GHz | 삼.7GHz | 95W | 8 | 8MB | 8MB | 2GHz | 알려지지 않은 |
| FX-6100* | 삼.3GHz | 삼.6GHz | 삼.9GHz | 95W | 6 | 6MB | 8MB | 2GHz | $ 165 |
| FX-4170 | 4.2GHz | 없음 | 4.3GHz | 125W | 4 | 4MB | 8MB | 2.2GHz | 알려지지 않은 |
| FX-B4150 | 삼.8GHz | 삼.9GHz | 4GHz | 95W | 4 | 4MB | 8MB | 2.2GHz | 알려지지 않은 |
| FX-4100* | 삼.6GHz | 삼.7GHz | 삼.8GHz | 95W | 4 | 4MB | 8MB | 2GHz | $ 115 |
| *실행 모델 | |||||||||
사양을 탐구하기 전에’모든 FX 프로세서가 완전히 잠금 해제되었음을 주목할 가치가 있습니다’우리는 Black Edition 브랜딩이 필요하지 않습니다’익숙해집니다. AMD는 올해 통합 그래픽으로 이미 두 개의 새로운 프로세서 디자인을 출시했기 때문에 FX 범위 중 어느 것도 통합 그래픽 장치를 가지고있는 반면, 훨씬 더 큰 인텔은 하나만 제공했습니다. 1 년 안에 3 개의 근본적으로 새로운 아파를 제공하는 것은 놀라운 일입니다. 불도저 CPU 디자인을 살펴보면’그것에 들어간 많은 급진적 인 새로운 디자인 작품.
A 시리즈 및 전자 시리즈 아포와 마찬가지로’편지 이외의 브랜딩 없음 – AMD. 실제 브랜드가가는 한 AMD는 이제 Vision, Radeon, FirePro 및 Opteron 만 있습니다.
AMD는 FX-8150을 세계라고 부릅니다’논란의 여지가 있지만 첫 8 코어 데스크탑 프로세서-우리는 무엇을 논의합니다’핵심에 s? 나중에, 그러나 여기에서 CPU 디자인의 개요를 고수 할 것입니다. Bulldozer CPU는 모듈로 구성되며 각각에는 2 개의 실행 장치와 Fetch, Decode, Floating Point 장치 및 2MB 레벨 2 캐시와 같은 일부 공유 리소스가 있습니다. 그런 다음이 모듈은 4-, 6- 또는 8 코어 CPU를 형성하기 위해 함께 볼트로 고정 될 수 있습니다. Bulldozer는 인텔 CPU가 한동안 구조적으로 모듈화 된 것처럼 (2008 년 11 월 Nehalem 기반 Core i7-900 시리즈 이후) 매우 모듈 식 디자인입니다.
모듈이 있습니다’t 일부 공유 유닛에 걸친 K10 실행 코어 한 쌍으로 방금 만들어졌지만 Bulldozer는 AMD의 완전히 새로운 디자인 (및 디자인 철학)입니다. 따라서이 기사는 다소 길다.
AMD FX-8150 사양
- 빈도 삼.7GHz
- 터보 주파수 최대 4.2GHz
- 핵심 불도저
- 제조 공정 32nm
- 코어 수 8 육체
- 메모리 컨트롤러 이중 채널 DDR3
- 은닉처 8 x 16kb l1 데이터, 4 x 64kb l1 명령, 4 x 2MB L2, 4 x 2MB L3
- 포장 소켓 AM3+
- 열 설계 전력 (TDP 125W
- 특징 SSE, SSE2, SSE3, SSE4A, SSE 4.1, SSE 4.2, 256 비트 AVX, Aesni, Pclmulqdq, AMD64, Cool’N’조용한 3.0, AMD-V, MMX, FMA4, XOP
댓글을 달고 싶다? 로그인 해주세요.
검토 : AMD 불도저 FX-8150


내 금고에 추가 :
안녕, 현상, 안녕하세요, fx
K10, 좋아하는 작별 인사
AMD는 Athlon과 Phenom CPU에서 상당한 마일리지를 꺼 냈습니다. Athlon 64, Architecture Modifications-K8 ~ K10-Die Shrinks, Socket Shrinks 및 Board 가격 절단은 8 년 동안 주류 빌드를위한 견고한 선택을 유지하는 것을 의미하는 Athlon 64, Architecture Modifications-K8 ~ K10- 소켓 수명 및 전반적으로 가격 절단을 통해 계보를 완전히 추적합니다.
한편, 경쟁사 인텔은 같은 8 년 만에 새로운 기술과 아키텍처 뗏목을 출시하여 2011 년 1 월에 발표 된 인상적인 2 세대 핵심 칩으로 끝났습니다. AMD의 Phenom II는 낡은 권투 비유를 그려 보려면 그의 프라임을 지나가는 복서이며, 가격 절단은 Foible을 마스킹 할 수 있지만 캔버스를 때릴 때까지 많은 시간이 남아 있지 않습니다.
AMD는 여전히 서 있지 않았다. 완전히 새로운 데스크탑 Llano와 함께 플레이하기 위해 자체 퓨전을 가져 왔으며, 적절한 CPU로 건강한 GPU 성능을 포장했습니다. 이제 인텔과의 싸움을 할 준비가 된 것은 Phenom II를 대체하도록 설계된 다양한 새로운 주류 CPU입니다. 불도저 가족을 입력하십시오.
FX, 파운드 파운드 챔피언?
K10 유래 Phenom II 아키텍처에서 깨끗하게 휴식을 취하면서 불도저에 관한 모든 것이 새로. 새로운 제작 프로세스, 일반 아키텍처, ISA 지원, 캐시 설정, 전력 배달 시스템 및 브랜딩이 있습니다 : PHEW! 각각을 차례로 검사하여 불도저의 피부 아래에 맡겨 봅시다.
32nm 생산
CPU-and-GPU Llano에 채택 된 프로세스에서 AMD는 GlobalFoundries의 32nm Silicon-on-Irsulator High-K Metal Gate Fabrication을 사용하고 있습니다. 32NM은 2011 년 말에 필수품이며, AMD는 PHENOM II에 사용되는 45NM 프로세스보다 더 많은 트랜지스터를 짜낼 수 있습니다.
그러나 Glofo는 Llano 칩의 꾸준한 공급을 보장하는 데 잘 문서화 된 문제를 견뎌냈습니다. AMD의 PR 기계는 채널에 ‘적절한 공급’이있을 것이라고 진술함으로써 응답했지만, 이것이 어떻게 불도저 수율로 변환 되는가?. AMD는 인텔의 팹에서 날아가는 풍부한 핵심 칩에 직면 할 때 파트너와 채널을 지원해야합니다.
건축 – 새로운 시작
여기가 흥미로워지는 곳이 있습니다. AMD는 모든 새로운 아키텍처가 코어, 전원 및 성능 측면에서 확장되어야한다는 것을 심각하게 이해하여 랩톱, 데스크탑 머신 및 서버에 맞출 수 있습니다. 그리고 문자 그대로 모듈 식 아키텍처가 설계된이 필수 스케일링에 응답합니다.
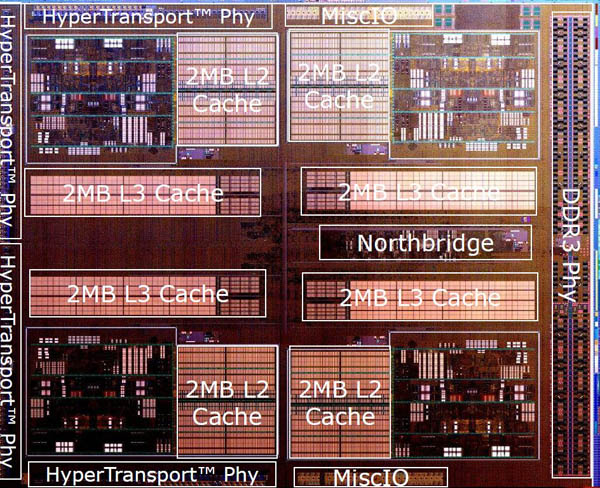
높은 수준의 개요에서 볼 수있는 불도저가 있습니다. 빠른 한 눈에는 많은 캐시로 둘러싸인 4 개의 실행 코어 -16MB, 실제로. 온 칩 노스 브리지, L3 캐시 및 4 개의 하이퍼 랜 스포츠 링크와 듀얼 채널 DDR3 메모리가 인터페이스하여 시스템의 나머지 부분에 링크되면 여기에는 새로운 것이 많지 않은 것 같습니다. 사진의 일부가 통합 그래픽에 대한 참조가 없다는 것은 당신의 관심을 피할 수 없습니다. 불도저는 순수한 CPU입니다.
그러나 첫눈에 오해의 소지가있을 수 있습니다. 통합 그래픽에 대한 조항은 없지만 여기에는 8 개의 CPU 코어가 존재하지만 각 코어는 Yore의 프로세서에 의해 설정된 완전 독립 금형에 적합하지 않습니다. 설명에 대해 설명하는 것이 있으므로 칩의 1/4을 확대합시다.
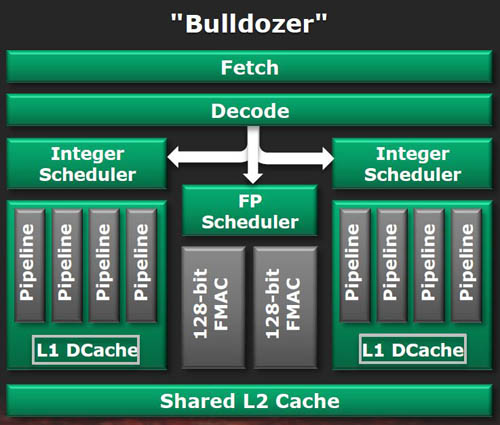
다음은 한 모듈에서 무슨 일이 일어나고 있는지에 대한 간단한 개요입니다. 불도저에는 모듈을 통해 만들어 졌다는 것을 이해하는 것이 중요합니다. 8 코어 칩에는 4 개의 모듈이 있고 6 개의 코어 칩에는 3 개의 활성 모듈이 있으며 4 코어 2 개입니다. 아이디어를 얻을 수 있습니다. 4 모듈, 8 코어 칩의 무게는 거의 2 억 개의 트랜지스터 (Ahem, 1).AMD가 실수를 계산 한 후 2BN, 315mm²의 지역에서 다이 크기가 있습니다. 흥미롭게도, 이것은 더 큰 45nm 공정에서 제조되었지만 6 코어 Phenom II Die와 같은 크기입니다. 그러나 Intel은 4 개의 코어, 8 개의 스레드 및 통합 그래픽 (Core i7 2600K)을 상당히 작은 다이로 포장합니다.
AMD는 모듈 당 완전히 독립적 인 코어를 가지고 있지 않지만, 인텔의 최신 칩에서 발견되는 하이퍼 스레딩 코어와 같은 통합은 아닙니다. 이 핵심 Mishmash의 이유는 핵심 처리량에 대한 균형을 잡는 다이 크기와 제조 비용으로 달려 있습니다. 경제적 비용을 신경 쓰지 않은 세상에서 AMD는 8 개의 독립 코어로 불도저를 엔지니어링 할 것입니다.
Bulldozer를 사용하여 두 스레드 가이 모듈을 통해 움직이고 있다고 가정하여 각 코어에서 처리 될 수 있습니다. 그들은 (훨씬 더 큰) 플로팅 포인트 스케줄러뿐만 아니라 설정 단계를 공유해야하며, 이해하기에 중요한 포인트를 사용하면 진정으로 별도의 코어에서는 일어나지 않을 것입니다. 그러나 Decode Stage는 Clock II의 3 개 (코어 당)에서 3 개에서 클록 사이클 당 4 개의 지침으로 향상되었으며 Branch Fusion이라는 기술을 통해 Bulldozer는 실제로 Decode Stage를 더 넓게 만들 수 있습니다.
아래로 이동하면 각 코어는 2 개의 ALU와 2 개의 Agus를 처리 할 수 있지만 Phenom II는 각각 3 개를 가지고 있음을 상기시켜줍니다. 싱글 스레드 벤치 마크 성능 에서이 문제에 대해 더 많이 이야기 할 것입니다. 궤도에, 각 코어는 16KB의 L1 캐시를 가지고 있으며, 더 많은 것을 기대했지만 AMD는 상당한 L2 캐시가 있으면 각 모듈이 처분 할 때 독점적 인 2MB를 갖는 데 도움이된다고 말합니다.
FP 스케줄러로 돌아가서이 공유 리소스는 별도의 코어에게 작업이 완료되었음을 알리는 루프백 시스템이 있습니다. 그리고 그 작업은 4 개의 파이프 – 128 비트 FMAC 2 개와 128 비트 정수 2 개 – Phenom II와 마찬가지로 수행됩니다.
고립 된 상태에서 고려 된 AMD의 디자인 선택은 불도저 뒤의 이데올로기에 대한 상당히 명확한 아이디어를 제공합니다. 한 스레드가 전체 모듈 자체를 갖는 단일 스레드 성능은 일반적으로 여기에서 중요하지 않으며, ALU 및 AGU 설정 감소로 입증되며, Phenom II. 두 개의 스레드로 모듈을 작성하여 부하를 증가시키고 불가피한 리소스 공유, 특히 탑 엔드에서 발생하지만 4 전체 디코더를 사용하여 성능 저하가 개선됩니다.
Workload 유형에 대한 사전 지식이없는 Bulldozer 모듈이 얼마나 강력한 지 알기가 어렵습니다. Bulldozer에서 최적화되지 않은 코드를 사용하는 경우 실제 가능성이 더 낮게 나올 것입니다. Processor 101은 그러한 파이프 라인을 사용하면 값 비싼 포장 마차와 지점 오해의 가능성이 열리면 문제가 해결 될 경우. AMD의 Adam Kozak은 불도저가 ‘많은 개선 된’프리 페치와 독립적 인 (이혼) 논리와 예측을했다고 알려주었습니다.
기본 아키텍처 관점에서 모두 반올림하는 Northbridge 제어 L3 캐시는 코어간에 공유됩니다. 이것은 구현 된 모듈의 수에 관계없이 총 8MB의 총 8MB이므로 코어가 적은 칩이 더 많은 캐시를 수신합니다.
노스 브리지는 또한 시스템 메모리에서 액세스를 제어합니다. AMD는 공식적으로 지원되는 1,866MHz에 속도를 높이는 온 칩 캐시가 너무 많기 때문에 전통을 유지하고 듀얼 채널 DDR3 설정을 선택합니다
불도저가 도착했습니다 : AMD FX-8150 프로세서 검토

AMD가 오랫동안 이야기 해 온 큰 혁명은 마침내 일어났습니다! 오늘 우리는 오랜 Bulldozer Microarchitecture를 기반으로 8 코어 데스크탑 프로세서를 만났습니다. AMD가 이번에 오랫동안 잃어버린 리더십을 되 찾을 수 있는지 검토에서 알아 봅니다.
Bulldozer Microarchitecture를 기반으로 한 새로운 AMD 프로세서. AMD 제품에 팬이 너무 많다는 사실뿐만 아니라 그 이유는 몇 가지가 있습니다. 나는 여러분 중 일부는 AMD 프로세서가 모든 측면에서 인텔보다 나은시기를 기억한다고 확신합니다. 일부 사용자는 AMD 제품을 좋아하는 가격과 성능의 균형 조합을 위해. 그리고 어떤 사람들은 열정에 의해 쫓겨 났을 수도 있으며, 그들은 그들이 작업 한 새로운 소규모의 장점에 대해 이야기했습니다. 이 모든 것은 새로운 불도저 프로세서 세대를 기다리는 수년간의 논리적 결과를 얻었습니다. 당신은 큰 관심과 흥분 으로이 리뷰를 읽고 있습니다.
그러나 대기는 확실히 그만한 가치가있었습니다. 불도저 프로세서 마이크로 아키텍처의 성공은 향후 몇 년 동안 프로세서 시장의 상황을 결정할 것입니다. 현재 인텔만이 충분한 엔지니어링 리소스와 생산 능력을 가지고 있으며 2-3 년마다 새로운 미세 구조물을 출시 할 수 있습니다. AMD는 훨씬 더 합리적인 템포를 고수해야합니다. 그것은 당신을 다소 무섭다는 것처럼 당신을 때릴지 모르지만 현재 Phenom II 및 Athlon II 프로세서에서 사용되는 마이크로 아키텍처는 2003 년까지 거슬러 올라갑니다. 미성년자 만있었습니다 “화장품” 그 이후로 변경되었습니다. 따라서 우리는 실제로 불도저 프로세서의 출시가 AMD의 개발 프로세스 속도를 높이기를 기대하지 않습니다. 새로운 불도저가 향후 몇 년간 모든 고성능 AMD 제품의 기초가 될 것이라는 것은 의심의 여지가 없습니다.
회사 로드맵의 현재 버전은 2014 년 까지이 마이크로 아키텍처를 이용하지만 그 시점을 넘어서도 계속 존재할 것입니다.
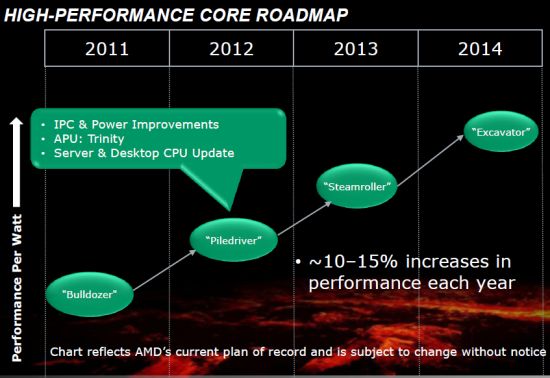
AMD’S 매년 최소 10-15%의 성능 향상을 제공하겠다는 약속. 시계 주파수 증가는 성능을 향상시키는 주요 방법 일 가능성이 높으며, 미세한 교사 개선이 백그라운드에서 더 많아 질 것입니다.
다시 말해, 오늘날 불도저 마이크로 아키텍처의 성공은 AMD에 삶을 변화시키는 영향을 미칩니다’미래는 제품의 경쟁력이 얼마나 경쟁력이 있는지, 결국 프로세서 시장에 일반적으로 일어날 일을 결정합니다.
물론 우리는 할 수 있습니다’t Bulldozer가 AMD의 유일한 주요 제품이 아니라는 것을 거부합니다. 이 마이크로 아키텍처는 현재 고성능 데스크탑 및 서버 시스템에 위치하고 있습니다. 동시에 AMD는 나머지 시장에 대한 다른 제품을 가지고 있습니다. 예를 들어, 올해 초에 출시 된 Bobcat Microarchitecture의 저렴한 에너지 효율적인 프로세서 또는 Llano APU가 회사에서도 중요합니다. 그리고 우리의 테스트에 따르면 이들은 넷북과 넷 꼭대기에 우수한 플랫폼이 될 수 있고 주류 통합 플랫폼에 전력을 공급할 수있는 매우 성공적인 제품이라는 것이 밝혀졌습니다.
그럼에도 불구하고 불도저’S의 성공 또는 실패는 장기적으로 훨씬 더 큰 의미를 가질 것입니다. 먼저,이 소기업은 서버와 고성능 데스크탑 (서버 및 고성능 데스크톱)을 가진 시장 부문을 대상으로합니다. 따라서 AMD에 큰 영향을 줄 수 있습니다’S 재정 상황. 둘째, 새로운 마이크로 아키텍처 설계 및 개발에 관여하는 엔지니어는 실제로 AMD의 성공과 관련이 없습니다’S C, E 및 시리즈 프로세서. 이 CPU (또는 AMD의 APU’S 용어) ATI 기술의시기 적절한 획득으로 인해 현대 AMD 프로세서에 들어온 통합 Radeon HD 그래픽 코어에 시장에서의 성공을 거두었습니다. Bulldozer는 Computational Cores Microarchitecture에서 특별히 작업하는 엔지니어링 팀을위한 자격 테스트입니다. 셋째, 불도저는 결국 에너지 효율적인 플랫폼을 위해 설계된 제품을 제외하고는 전체 AMD CPU 라인업의 기초가 될 것입니다. 그래서 어느 날이 소기업은 Llano 프로세서에서도 K10을 완전히 대체하는 하위 엔드 시장 세그먼트에도 도달합니다.

전반적으로 Bulldozer Microarchitecture의 성공적인 출시의 중요성을 과대 평가하기는 어렵습니다. 그것은 심리적 수준뿐만 아니라 실용적인 수준에 대한 이정표 제품이기 때문에 우리는 새로운 K7 또는 K8과 같은 것을보고 싶어합니다.
그러나 실제 성능 테스트에 도달하기 전에도 위에서 언급 한 현상을 반복 할 가능성이 거의 없다고 말할 수 있습니다. 지난번 인텔은 AMD가 이상적이지 않은 Netburst Microarchitecture를 적극적으로 홍보하려고 노력함으로써 리더십을 얻는 데 도움이되었습니다. 그 당시 인텔 엔지니어는 시계 주파수 성장에 베팅하여 마침내 거대한 누설 전류를 우연히 발견했으며 AMD. 그러나 Intel이 전략을 수정하고 새로운 Core Microarchitecture를 시작했을 때 가능한 한 시계 당 많은 지침을 처리하려고 시도했을 때 AMD는 그 이후로 2 위로 물러서야했습니다.
시계주기 당 처리 된 지침 수로 현대 인텔 프로세서를 실수하는 것은 매우 어렵습니다. 오늘’S Sandy Bridge Microarchitecture는 디자인에 적어도 3 라운드의 최적화가 적용된 결과입니다. 그러므로 우리는 할 수 있습니다’A AMD의 계산 코어가 훨씬 높은 상대 효율성을 제공 할 것으로 예상됩니다. 특히 AMD 엔지니어가했기 때문에’T는 심지어 그런 목표를 가지고 있습니다.
불도저는 다른 주요 목표를 가지고 있습니다. 개발자에 따르면,이 마이크로 아키텍처를 기반으로 한 프로세서는 전임자 및 경쟁 업체에 비해 높은 시계 주파수와 더 많은 수의 계산 코어로 인해 빠르게 실행해야합니다. 동시에, 그들은 꽤 비용 효율적으로 유지되어야합니다.이자형. 작은 반도체가 죽고 비교적 낮은 코어 당 열 소산.
AMD의 비밀’S 멀티 코어 디자인
프로세서 코어 수의 증가가 필연적으로 프로세서 다이의 크기가 증가하는 것은 매우 논리적입니다. 결과적으로 제조 공정의 복잡성과 생산 비용도 증가합니다. 따라서 코어 수가 가장 많은 프로세서는 현재 서버 세그먼트에서만 사용됩니다. 기업 클라이언트는 일반 사용자보다 추가 비용을 지불하기를 훨씬 더 간절히 원하기 때문입니다. AMD’수용 가능한 가격대를 유지하면서 프로세서 코어 수를 늘리는 전략은 코어를 그에 따라 단순화해야한다는 것을 의미합니다. 그러나 반면에 코어를 단순화하면 현재 여전히 꽤 평행 할 수없는 애플리케이션에서 시스템 성능을 낮추는 것과 같이 원치 않는 결과를 초래할 수 있습니다.
따라서 AMD 엔지니어는 독특한 대안을 취하기로 결정했습니다. 개별 코어의 미세 구성은 더 복잡해졌으며 가능한 경우 단일 클록주기 당 실행되는 지침의 수를 증가시킵니다.
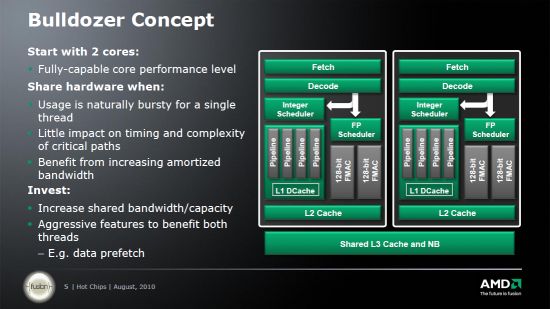
그러나 각 프로세서 코어에 일반적으로 존재하지만 과도한 효율을 갖는 리소스의 일부는 이제 코어 쌍 사이에서 공유됩니다.

결과 듀얼 코어 장치는 불도저 프로세서의 주요 빌딩 블록이되었습니다. AMD는 이러한 장치를 모듈로 언급합니다. 그들 각각은 두 개의 완전 기능적인 정수 실행 장치 세트가 있습니다. 그러나 부동 소수. 개발자에 따르면, 이러한 구성 요소는 두 코어를 공급할 수있는 충분한 잠재력을 가지고 있습니다.이 경우 코어 당 그러한 세트가있을 경우 종종 공회전이 발생하기 때문입니다. 또한, 마구간이없는 운영의 지연은 결과적으로 전반적인 성능에 심각한 영향을 미치지 않습니다.
AMD에 따르면, 위에서 설명한대로 설계된 단일 모듈은 완전 기능 듀얼 코어 프로세서의 80% 용량으로 수행 할 수 있습니다. 그러나 트랜지스터 예산의 약 44%를 절약합니다 (결과적으로 반도체 다이 크기).
AMD 프로세서 코어 밀도를 높이기위한이 독창적 인 접근 방식은 회사가 8 코어 (또는 4 개의 모듈) 불도저 반도체 다이를 설계 할 수있었습니다.

또한, 다이의 상당 부분이 캐시 메모리에 할당됩니다. L2 프로세서 캐시 단일 모듈 내의 CPU 코어 쌍 사이에서 공유되는 Caches는 각각 2MB이며 전체 프로세서에서 공유되는 L3 캐시 메모리는 8MB의 큰 것입니다. 이런 식으로 AMD를 고려하면’전통적인 독점 캐시 설계에 따르면, 우리는 캐시 메모리의 총량이 8 코어 CPU 당 16MB에 도달한다고 진술 할 수 있습니다. 동시에 불도저 다이 크기는 합리적인 한계 내에 남아있어 AMD 개발자가 실제로 궁극적 인 목표를 달성했습니다.
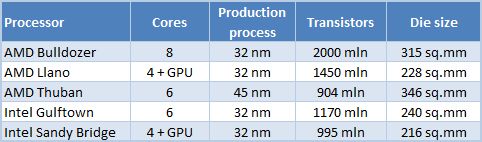
우리가 절대 숫자에 대해 이야기하면, 8 코어 불도저 프로세서는 K10 미세 구조가있는 6 코어 Thuban (Phenom II X6) CPU보다 작은 반도체 다이를 가질 것임을 의미합니다. 그러나 불도저 프로세서는보다 고급 32 nm 생산 공정을 사용하여 제조 될 것임을 명심해야합니다. 그리고 현대 쿼드 코어 인텔 샌디 브리지 프로세서와 비교하여 새로운 8 코어 AMD CPU는 45% 더 큰 다이를 가질 것입니다.
그러나 하이퍼 스레딩 기술로 인해 운영 체제는 불도저와 마찬가지로 쿼드 코어 인텔 샌디 브리지 프로세서로 8 코어로 볼 수 있습니다. 이 사실은 실제로 불도저를 본격적인 8 코어 프로세서라고 부르는 것이 얼마나 적절한 지에 대한 의문을 제기 할 수 있습니다. 그러나 AMD와 Intel은 8 개의 계산 스레드의 동시 실행을 구현하는 데 다른 접근 방식을 취했다는 것을 이해하는 것이 중요합니다. 인텔 개발자는 하나의 실행 장치 세트 만 사용하여 단일 코어 내에서 두 개의 계산 스레드를 실행하는 기능으로 마이크로 아키텍처를 무장했습니다. 반대로 AMD는 모든 것을 제거했습니다 “불필요한” 두 개의 완전 작동 코어에서 엑스트라이지만 각 모듈 내에 두 개의 실행 장치 세트를 유지했습니다.
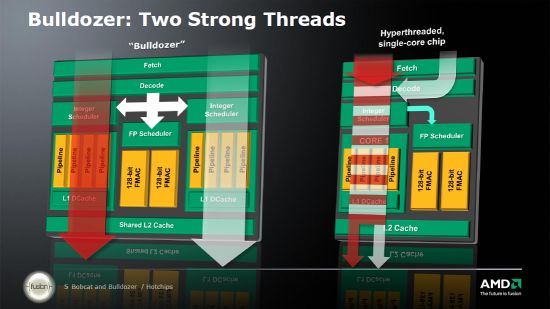
결과적으로 인텔’S 하이퍼 스레딩 기술은 다중 스레드 성능을 약 15-20%만 증가시키는 반면 AMD’S 솔루션은 4 ~ 8 스레드로 전환시 80% 부스트를 생성했습니다.
8 코어 불도저 프로세서의 반도체가 모듈 식 내부 구조로 인해 4 코어처럼 보인다는 것을 인정해야하지만.
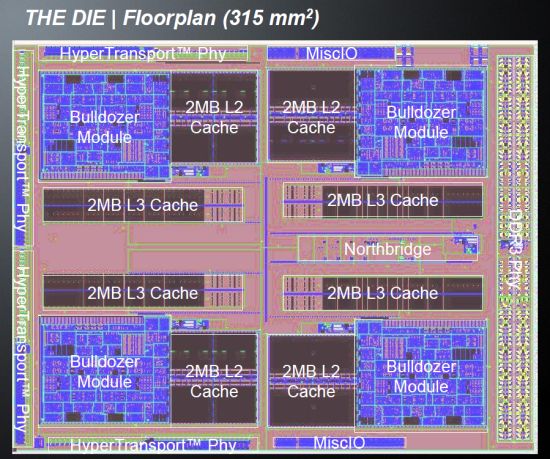
시계 당 더 많은 지침?
분명히 코어의 수를 늘리는 것은 궁극적 인 만병 통치약이 아닙니다. AMD가 Phenom II X6 프로세서를 시작했을 때 분명해졌습니다. 따라서 AMD 개발자는 그랬습니다’광범위한 디자인 수정에서 정지하십시오. 기본 Bulldozer Microarchitecture는 K10과 비교하여 실질적으로 완전히 변경되었으므로 AMD 시스템은 다중 스레드 작업뿐만 아니라 평행 덜 대중적인 응용 프로그램에서도 속도를 높이기를 희망합니다. 그리고이 희망은 매우 객관적인 증거로 뒷받침됩니다. 이전 AMD Microarchitures는 시계 당 최대 3 개의 지침 (단일 코어)을 처리하도록 설계되었지만 Bulldozer Microarchitecture는 시계 당 4 가지 지침을 처리 할 수 있어야하므로 Core Microarchitecture의 경쟁사 프로세서에 매우 가깝습니다.
실행 파이프 라인의 첫 번째 단계에서 몇 가지 품질이 변경되는 것을 볼 수 있습니다. 이 단계는 단일 모듈 내의 코어 쌍간에 공유되므로 AMD는’t 아키텍처 병목 현상으로 바뀝니다. 해독 될 지침은 32 바이트 블록의 L1I 캐시에서 프리 페치됩니다. 2 세대 코어 기반 프로세서보다 두 배입니다. 지침의 실제 L1I 캐시는 64KB가 크며 양방향 연관성이 있습니다. 해독 될 지침은 L2 캐시 메모리 에서이 캐시에 투기 적으로 사전로드됩니다.
지침은 두 개의 버퍼 세트를 포함하는 분기 예측 장치에 의해 프리 페치되며, 다른 코어의 활동을 독립적으로 모니터링합니다. 이런 식으로 불도저는 그랬습니다’티 “길을 잃다” 분기 예측 중에 실에서. 새로운 Microarchitecture는 높은 시계 주파수에서 작동하도록 설계되었으므로 지점 예측의 품질은 매우 중요합니다. 따라서 AMD는 분기 예측 알고리즘을 완전히 변경했으며 이제 새로운 불도저의 지점 예측 정확도가 실질적으로 향상되기를 바랍니다.
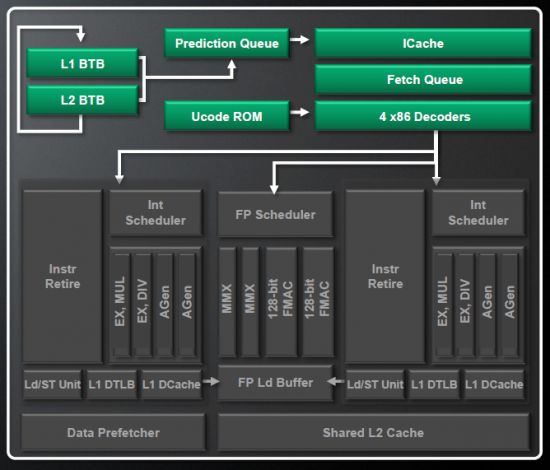
불도저’S X86 명령 디코더도 두 코어간에 공유되며 클록주기 당 최대 4 개의 수신 명령을 해독 할 수 있습니다. 그러나 성능은 4 개의 거시적 인 스트루크 (Decoding Process의 결과)로 제한됩니다’s 용어), x86 지침은 1-2 이상으로 분해 될 수 있습니다. 따라서 디코더가 이전 세대 마이크로 아키텍처에 비해 33% 더 효과적이되었지만 성능은 최적으로 2 개의 정수 클러스터와 1 개의 플로팅 포인트 클러스터를로드하기에 충분히 높지 않을 수 있습니다.
나는 또한 그들이 새로운 불도저에서 일종의 매크로 퓨전 기술을 사용했다고 말해야합니다. 특정 그룹의 X86 지침이 함께 결합하여 디코더를 단일 지침으로 진행할 수 있습니다.
디코딩 된 거시적 인 스트루크는 3 개의 계산 클러스터에 분산되며, 그 중 2 개는 본격적인 계산 코어의 나머지 부분이며 다른 하나 인 Floating-Point Cluster는 코어와 공유됩니다. 이 클러스터 각각에는 고유 한 지침이 있습니다. 논리와 자체 스케줄러에 대한 재정의 지침이 있습니다. 그것은 분명히 AMD가 미래의 제품에서 이러한 클러스터 중 일부를 완전히 교체하거나 수정할 수 있음을 의미합니다.
지침 각 클러스터의 재정렬 프로세스는 실제 레지스터 파일을 기반으로합니다. 이 파일은 링크를 저장하여 컨텐츠를 등록하고 프로세서 내부의 데이터를 지속적으로 이동할 필요가 없습니다. 이 접근법은 물리적 레지스터 파일이 프로세서 클록 주파수 증가에 더 에너지 효율적이고 더 내성적이기 때문에 재주문 버퍼를 대체했습니다.
정수 클러스터는 각각 2 개의 산술 실행 장치 (ALU)와 메모리 주소 (AGU) 작업을위한 2 개의 단위를 포함합니다. K10 Microarchitecture와 달리 ALU와 하나는 적은 AGU가 있지만 AMD에 따르면’t 다이 크기를 크게 줄이면서 성능에 심각하게 영향을 미칩니다. 나는 쉽게 믿을 수 있습니다’t 디코더는 두 클러스터에 의해 실행을 위해 시계 당 4 개 이상의 거대 검사를 보낼 수 있기 때문에 2 개 이상의 ALU와 2 개 이상의 AGU를 보유하는 것이 실용적입니다.
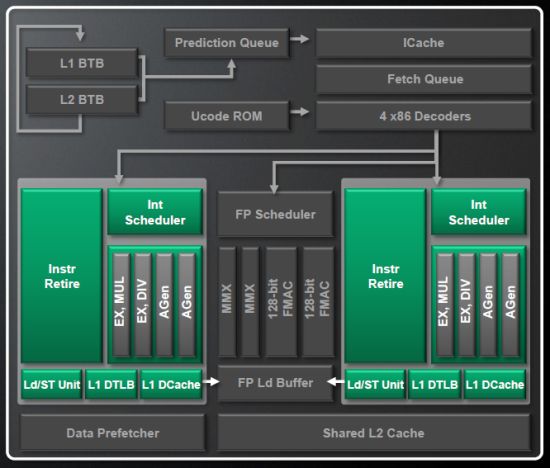
동시에, 실행 장치는 더 보편적이되고 기능이 거의 다릅니다.
캐시-메모리 시스템의 구성이 극적으로 변경되었습니다. 그들은 L1D 캐시의 크기를 64KB에서 16KB로 낮추고 쓰기 스루에 포함 시켰습니다. 동시에 그들은 4 방향에 대한 연관성을 높이고 “길 예측 자”. 크기의 심각한 감소를 보충하기 위해 L1 데이터 캐시의 대역폭을 상당히 실질적으로 증가시켜 이제 동시에 최대 3 개의 128 비트 작업을 처리 할 수 있습니다.
L1D 캐시 대역폭의 변경 사항은 분명히 공유 FPU 장치에서 지원되는 256 비트 AVX 명령어를 구현해야 할 필요성과 분명히 연결되어 있습니다. 그러나 그것은 그렇지 않습니다’t 플로팅 포인트 유닛은 이제 256 비트가되었음을 의미합니다. 실제로 단일 불도저 모듈에는 4 개의 128 비트 장치가 있으며 AVX 지침은 128 비트 작업의 연결된 쌍으로 해독됩니다. 따라서 FMAC (Floating-Point Multiply-Accumulate) 블록은이를 실행하기 위해 유니팅되며 Floating-Point 클러스터의 성능은 클록 사이클 당 프로세서 모듈 당 하나의 AVX-Instruction으로 떨어집니다.
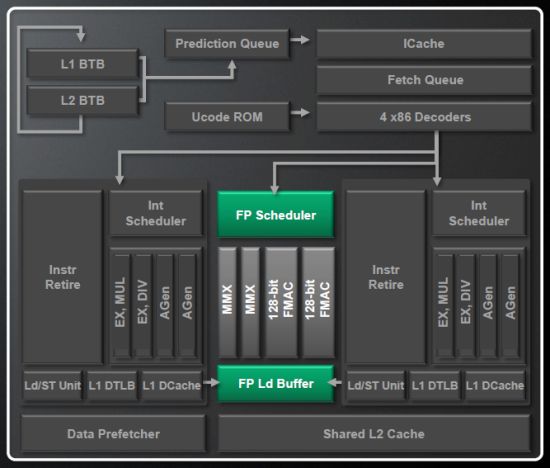
FPU는하지 않습니다’t 자체 L1 캐시가 있으므로이 클러스터는 정수 장치를 통해 데이터와 함께 작동합니다.
AMD 엔지니어가 인텔을 구현하기로 결정한 이후’불도저 프로세서에서 S AVX-Instructions 지원, SSE4와 같은 다른 현재 지침 세트에 대한 지원을 추가했습니다.암호화 가속을위한 2 및 Aesni. 더욱.
불도저’S L2 캐시는 프로세서 모듈 내부에서 단일 장치로 존재하며 코어가 공유합니다. 인상적인 2MB 크기이며 16 웨이 연관성이 있습니다. 그러나 캐시와 같은 캐시의 대기 시간은 18-20 클럭으로 증가했으며 버스 너비는 이전과 동일하게 유지되었습니다-128 비트. 불도저에도 불구하고’S L2 캐시는 크고 특히 빠르지 않습니다. 현재 경쟁 업체와 전임자는 대기 시간의 약 절반이있는 L2 캐시를 가지고 있습니다. 4 개의 클록 대기 시간 (K10 Microarchitecture보다 높음)이있는 작은 L1D 캐시와 함께’너무 좋아 보인다. 그러나 AMD는 불도저가 더 높은 클럭 속도로 실행할 수 있도록 캐시 메모리의 대기 시간을 증가 시켰다고 주장합니다.
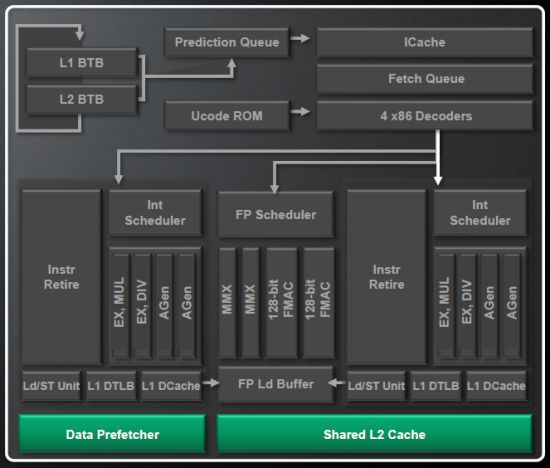
또한 AMD 엔지니어는 투기 데이터를 L1 및 L2 캐시에로드 할 수있는 효율적인 데이터 프리 페치 장치를 구현했습니다. 이 단위는 현재 훨씬 더 효과적으로 작동한다고 주장되며 불규칙한 데이터 구조를 인식 할 수 있어야합니다.
이론적으로 불도저는 매우 매력적으로 보입니다. AMD는 프로세서 마이크로 아키텍처에 대한 오래된 비전을 완전히 수정했으며 완전히 새로운 디자인을 제시했습니다. 그리고 새로운 마이크로 아키텍처가 한 프로세서 코어에서 3 개 대신 시계 당 4 개의 지침을 처리하는 데 최적화 되었기 때문에이 새로운 디자인이 매우 유망하다고 말해야합니다. 게다가, 그것은 또한 디코딩 스테이지 이전의 지침의 거시 융합을 지원하여 효과적인 성능을 더욱 증가시킵니다.
그러나 우리가 하나의 핵심을보고 실제로 그러한 코어가 쌍으로 결합된다는 사실을 고려하지 않을 때만 모든 것이 완벽하게 보입니다. 그리고 듀얼 코어 불도저 모듈에는 코어간에 공유되는 장치가 너무 많습니다. 특히, 이와 같은 모듈에는 하나의 명령식 프리 페치 장치와 하나의 디코더 만 있으므로 전체 듀얼 코어 블록은 여전히 시계 당 4 개의 지침 만 처리 할 수 있습니다. 그리고 이론적 성능 측면에서 불도저 모듈이지만 Sandy Bridge 프로세서의 단일 코어와 동등한 논리적 인 것으로 간주되는 실제 핵심은 아닙니다. 이 경우 모듈’s 두 스레드를 수행하는 능력은 AMD에서 Intel 로의 논리적 인 응답처럼 보입니다’S 하이퍼 스레딩 기술.
물론, 새로운 프로세서의 성능 테스트는’S, 그러나이 시점에서도 우리는 할 수 있습니다’불도저를 생각하는 데 도움이됩니다’8 코어 프로세서로서의 포지셔닝은 더 많은 마케팅 움직임입니다. 실제로이 프로세서에 대한 더 나은 아이디어를 제공하는 모듈 수입니다’ 계산 잠재력. 이론적 성능과 관련하여 2 세대 Intel Core Microarchitecture의 관점에서 이러한 모듈을 코어와 비교하는 것이 더 논리적으로 보입니다.
따라서 논리적 질문이 나타납니다. AMD가 단일 프로세서 모듈 내에서 2 스레드 처리를 구현하기로 결정한 이유? 왜 할 수 있습니까?’t 그들은 단순히 두 개의 다른 코어의 실행 장치를 단일 클러스터로 결합합니다? 그 이유는 몇 가지 있습니다.
먼저, 수많은 실행 장치를 최적으로로드 할 수 있도록 고급 프로세서 간 논리가 필요합니다. 그러나 AMD는 그랬습니다’t 고효율 지점 예측 및 지시 및 데이터 프리 페치의 구현으로 성공했습니다. 따라서 소프트웨어 개발자의 책임은 다중 스레딩을 지원하는 불도저 호환 애플리케이션을 제공하는 것이 좋습니다.
둘째, 더 많은 수의 동시에 처리 된 계산 스레드가 좋은 것입니다. 데스크톱 사용자와 특히 게이머는 8 개의 간단한 불도저 코어에서 크게 혜택을받지 못하지만이 마이크로 아키텍처는 서버 환경에서 매우 환영해야합니다. 따라서 불도저의 주요 목표는 AMD를 되 찾는 것이 가능할 가능성이 있습니다’컴퓨터 애호가를 행복하게 만드는 대신 서버 시장에서의 리더십.
더 많은 터보를 얻는 터보 코어
에너지 효율성은 현대 프로세서의 가장 중요한 특성 중 하나입니다. 예를 들어, 인텔은 다가오는 미세 구조의 전력 소비를 낮추는 목표를 목록 위에 놓습니다. amd hasn’t는 아직 도착했고 엔지니어들은 여전히 더 높은 속도를 쫓고 있습니다. 그러나 그것은 그렇습니다’t는 개발자가하지 않았다는 것을 의미합니다’T Bulldozer에주의를 기울여야합니다’S 열 및 전력 특성. 반대로, Llano 이후, 주로 에너지 효율에 대한 새로운 접근 방식은 불도저 프로세서로 들어갔다. 그러나이 경우 개발자는 에너지 절약을 위해 그다지 많은 잠재력을 사용했지만 시계 주파수를 늘리고 성능을 훨씬 향상시키는 데 사용했습니다.
물론, 더 미세한 생산 공정은 전력 소비 및 열 소산 판독 값에 긍정적 인 영향을 미쳤습니다. Bulldozer는 High-K 유전체 32 nm 공정, 금속 게이트 트랜지스터 및 SOI 기술로 제조되었습니다. 다시 말해, Llano 제조에 사용되는 것과 동일한 GlobalFoundries 프로세스입니다. 결과적으로 대량 생산 8 코어 불도저 프로세서는 1.4 V 최대 코어 전압.
그러나 Llano에서 물려받은 주요 혁신은 전력 게이팅 사용입니다. 이는 CPU의 선택된 부분에서 전력을 분리해야합니다. 불도저 프로세서에서 선택한 듀얼 코어 모듈 및 캐시 메모리에서 전원을 끄는 것을 허용합니다.
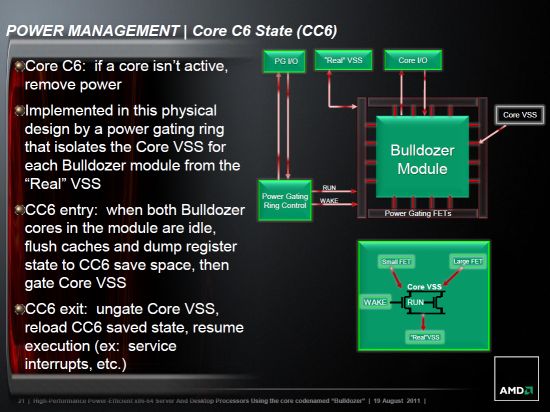
하나의 모듈 내의 두 계산 코어가 C6 전원 절약 모드로 전환되면 모듈 전원이 꺼집니다. 불행히도이 기술은 불도저 내부에 개별 코어가 없기 때문에 프로세서 코어에 적용 할 수 없습니다. 동일한 모듈 내의 다른 코어와 일부 리소스를 공유합니다.
C6 전원 절약 모드는 불도저 프로세서의 터보 코어 기술을 제어합니다. 불도저 프로세서 모듈의 절반 이상이 꺼져 있고 전원 절약 모드에서 코어 전압 및 시계 주파수가 증가하면. 이 강제 모드를 Max Turbo Boost라고합니다.
그러나 AMD가 K10 Microarchitecture의 Thuban 프로세서에 동일한 자동 오버 클럭을 도입함에 따라 Max Turbo Boost 모드에는 새로운 것이 없습니다. 여기서 주로 새로운 것은 모든 프로세서 코어가 활성화 된 경우에도 시계 주파수가 공칭 값을 넘어서 증가 할 수있는 모든 코어 부스트 모드입니다. 불도저 프로세서에서 구현 된 강화 된 터보 코어의 향상된 버전을 통해 실제 전력 소비와 다른 장치의 활용 수준에 의한 판단하는 실제 전력 소비 및 열 소산을 정확하게 평가할 수 있습니다. 따라서 프로세서에 따르면’s는 현재 전력 소비와 열 소산이 임계 값보다 훨씬 낮은 것으로 추정되며, 프로세서는 코어가 유휴 모드에 있지 않더라도 핵심 전압과 클럭 속도를 높일 수 있습니다.

따라서 불도저 기반 프로세서의 시계 주파수는 매우 가변적 값입니다. 그것은 매우 큰 간격 (최대 900MHz)으로 극적으로 변할 수 있습니다 “무거움” 실행 된 알고리즘 및 활성 코어 수.
데스크탑 플랫폼 새로 고침
새로운 마이크로 아키텍처가 시작되면서 AMD는 새로운 플랫폼의 설계를 유지했을뿐만 아니라 기존 인프라와 새로운 불도저 프로세서의 호환성을 유지했습니다. 결과적으로 이전 모델과 마찬가지로 새로운 프로세서에는 L3 캐시, 메모리 컨트롤러 및 하이퍼 트랜스 스포츠 버스 컨트롤러와 통합 된 North Bridge가 포함되어 있습니다. 최근에 출시 된 AMD 및 Intel 프로세서는 통합 PCI Express 그래픽 버스 컨트롤러를 가지고 있지만 New Bulldozer Dosn’t가 있습니다.
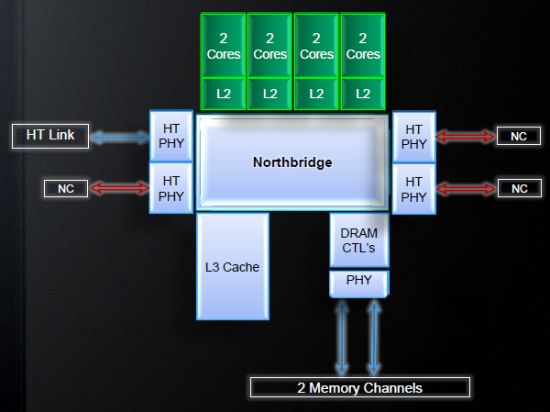
K10 Microarchitecture를 기반으로하는 프로세서와 마찬가지로 불도저 프로세서의 North Bridge는 자체 시계 주파수에서 작동하며 2로 설정됩니다.0-2.다른 CPU 모델의 경우 2GHz. 이 주파수는 L3 캐시의 속도에 직접적인 영향을 미치기 때문에 성능에 약간의 영향을 미칩니다. 우리가 이미 말했듯이, 새로운 프로세서에는 64- 웨이 연관성이있는 8MB L3 캐시가 있습니다. 회사 사용자의 특별 요청에 따라이 캐시 메모리에 저장된 데이터는 오류 수정 코드 (ECC)로 보호됩니다.
불도저 프로세서의 메모리 컨트롤러는 그렇습니다’T는 주로 새로운 것을 자랑합니다. 이전과 마찬가지로 DDR3 SDRAM을 지원하고 듀얼 채널 설계를 사용하며 실제로 쌍으로 또는 독립적으로 작동 할 수있는 두 개의 독립적 인 단일 채널 컨트롤러로 구성됩니다. 여기에 AMD가 추가 된 유일한 것은 DDR3-1867과 같은 더 빠른 메모리 유형에 대한 지원과 1에서 작동하는 에너지 효율적인 메모리 모듈과의 호환성입니다.25V 및 1.35 v.
Desktop Bulldozer Modification CodeNAMIM Zambezi에 대해 말하면 Scorpius라고도 알려진 새로운 소켓 AM3+ 플랫폼 용으로 설계되었다고 언급해야합니다. 소켓 AM3+에는 942 핀이 있으며 소켓보다 1 핀 AM3. 그러나 핀 차이에도 불구하고 새로운 Zambezi는 이전 소켓 AM3 메인 보드와도 호환됩니다. 이전 메인 보드에서 새 프로세서를 사용하는 경우 선택한 전력 관리 기능 만 손실됩니다. 예를 들어, 빈도는 활성 터보 코어로 느리게 전환되고 쿨합니다’N’조용하고 vdrop은 전혀 작동하지 않습니다.
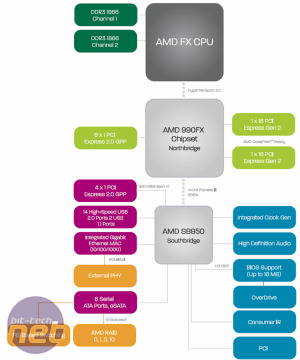
그럼에도 불구하고 AMD는 모든 메인 보드 제조업체와 긴밀히 협력하여 Zambezi가 출시 될 때까지 900 시리즈의 새로운 칩셋을 기반으로 사용할 수있는 수많은 신제품이있을 것입니다. 아래 흐름 차트는 Zambezi 프로세서와 새로운 칩셋 주위에 제작 된 일반적인 시스템을 보여줍니다
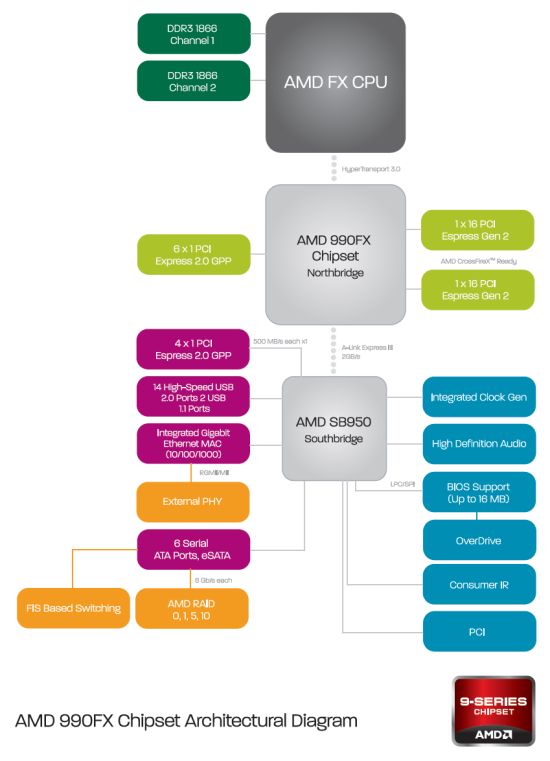
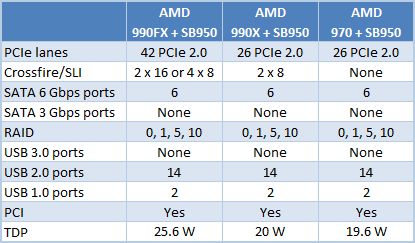
새로운 AMD 990FX의 특징 및 더 간단한 수정 – AMD 990X 및 AMD 970)는 기본적으로 새로운 소켓 AM3의 특정 전기 특성을 지원하는 것입니다+. 어떤 종류의 새로운 인터페이스도 없습니다. 800 시리즈 칩셋과 마찬가지로 New South Bridge는 6 개의 6Gbps 포트와 14 개의 USB 2를 지원합니다.0 포트. 우리가 PCI Express 3과 같은 것들을보기 위해 죽어 가고 있었음에도 불구하고.0 또는 최소 USB 3.0 새로운 칩셋에서 지원, 그런 것은 없습니다. 하위 엔드 소켓 FM1 플랫폼의 칩셋이 USB 3을 획득했기 때문에 실제로는 매우 이상합니다.0 지원.
새로운 칩셋 수정의 유일한 차이점은 지원되는 다중 GPU 구성의 유형입니다
Zambezi CPU 라인업
Zambezi 프로세서의 출시는 AMD를 완료합니다’S 프로세서 라인업 업데이트. 새로운 불도저 마이크로 아키텍처를 기반으로 한 데스크탑 CPU는 새로운 플래그십 제품이 될 것이며, 모든 Phenom II 모델 시장에서 빠르게 추방됩니다.
새로운 마이크로 아키텍처의 혁신적인 특성을 강조하기 위해 AMD는 Zambezi 프로세서 인 FX의 차이 마케팅 이름을 사용할 것입니다. 한편으로, 그것은 CPU 마킹에 문자를 사용하는 것을 암시하는 새로운 이름 지정 시스템에 완벽하게 맞지만 반면에 6-7 년 전에 가장 빠른 데스크탑 CPU 인 전설적인 Athlon 64 FX 프로세서를 상기시킵니다. 그러나 그 시대는 오랫동안 사라 졌으므로’s 오늘 우리가 제공하는 것을 자세히 살펴보십시오.
시장에는 4 개의 FX 프로세서 모델이 곧있을 것입니다. Zambezi 프로세서 모델은 클럭 속도뿐만 아니라 활성 계산 코어의 수에 따라 다르지만 모두 동일한 통합 반도체 다이에서 구축됩니다. 여기있어:
코어가 8 개보다 적은 프로세서를 구축하기 위해 AMD는 반도체 다이에서 일부를 비활성화합니다. K10 Microarchitecture에서 프로세서와 같은 방식으로 잠금을 해제 할 수 있는지 여부는 여전히 의문입니다. 그럼에도 불구하고, 우리는 새로운 900 시리즈 칩셋을 중심으로 구축 된 여러 메인 보드의 BIOS 설정에서 해당 모든 옵션을 보았으므로 긍정적 인 결과에 대한 희망이 분명히 있습니다.
6 코어 및 쿼드 코어 프로세서의 생산은 모듈 당 코어 잠금을 암시합니다. 이는 두 가지 모듈에서 두 번째 코어가 아닌 전체 듀얼 코어 모듈을 잠그는 것을 의미하지만, 후자의 접근 방식은 성능 관점에서 훨씬 더 효율적일 수 있습니다. 그러나 6 및 쿼드 코어 불도저 프로세서는 단지 결함있는 다이를 활용하는 방법 일뿐입니다. 새로운 생산 공정을 사용하고 다이의 크기가 상당히 많기 때문에 상당히 많을 수 있습니다.
AMD는 고속 클럭 속도로 작동을 위해 새로운 마이크로 아키텍처를 최적화했지만’t는 그들이 인상적인 돌파구에 도달했다고 말합니다. 4GHz 임계 값은 여전히 연출되지 않았으며 상단 FX 프로세서의 공칭 주파수는 Phenom II X4 980보다 훨씬 낮습니다. 우리는 그들이 생산 공정을 마스터함에 따라 Zambezi 주파수가 계속 빠르게 성장하기를 바랍니다. 현재 AMD 로드맵에 따르면 새로운 프로세서 패밀리는 2012 년 1 분기보다 빨리 속도를 높이기 시작해야합니다.
우리는 돈입니다’t 전력 소비 및 열 소산 측면에서 극적인 승리를보십시오. AMD는 새로운 불도저가 이전 모델보다 에너지 효율이 높을 것이라고 오랫동안 우리에게 약속 해 왔지만 실제로 8 코어 모델은 최고 Phenom II CPU와 동일한 TDP를 가지고 있습니다. 조만간 그들은 95 W FX-8120 모델과 라인업과 동일한 TDP가있는 FX-8100을 추가해야합니다.
반면에 새로운 FX 프로세서의 가격은 매력적인 것 같습니다. AMD는 그렇습니다’t 경쟁보다 저렴한 가격으로 플랫폼을 계속 제공하려는 계획에서 벗어나기를 원하기 때문에 상위 8 코어 Zambezi 프로세서가 최고 코어 i5 CPU에 대항하여 배치됩니다. 전반적으로 AMD는 다음과 같은 포지셔닝 계획을 고수 할 것입니다

다시 말해, AMD는 6 코어 인텔 CPU와 다가오는 LGA2011과 경쟁 할 의도가 없으며 주류 세그먼트에 중점을 둘 계획입니다.
애호가에게 좋은 소식은 모든 FX 프로세서가 잠금 해제 된 승수와 함께 제공된다는 것입니다. 모든 Zambezi CPU는 단순히 기본 시계 승수를 조정할뿐만 아니라 터보 코어 기술을 재구성하여 쉽게 오버 클럭을 수 있습니다. 메모리 하위 시스템과 프로세서에 통합 된 North Bridge의 주파수를 오버 클럭할 수도 있습니다.
AMD FX-8150을 자세히 살펴보십시오
AMD는 새로운 Zambezi 프로세서-FX-8150을 확인할 수있는 기회를 제공했습니다.

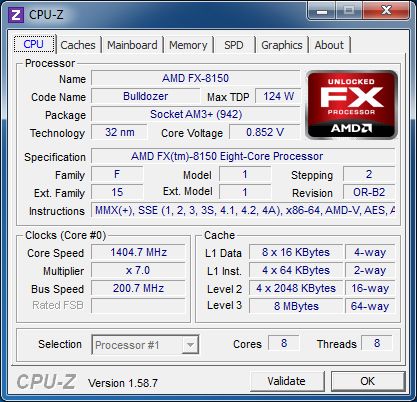
공칭 클럭 속도는 3입니다.6GHz 및 다음 CPU-Z 스크린 샷에서 자세한 내용을 확인할 수 있습니다
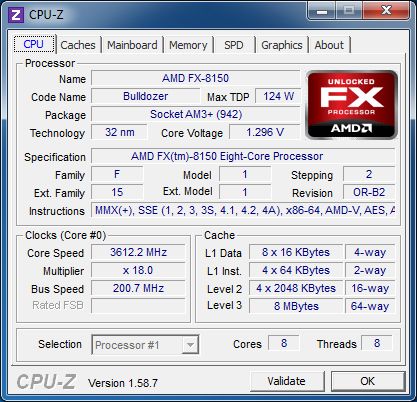
B2 프로세서 스텝핑을 사용하고 이미 첫 번째 버전이 아닙니다. 반도체 다이의 이전 변형은 그랬습니다’원래 계획된 클럭 속도에서 일을 거부했기 때문에. 이것이 실제로 봄 런칭이 여름으로 약간 밀려나서 넘어져서 마침내 10 월 중순에 일어난 이유입니다.
그러나 오늘’S 주파수 3.6GHz’매우 인상적입니다. 인텔뿐만 아니라 AMD 모두 더 높은 주파수에서 작동하는 제품이 있습니다. 그러나 FX-8150은 매우 유망한 터보 코어 기술을 지원하며, 이는 CPU 클럭 주파수를 4로 자동으로 증가시킬 수 있습니다.낮은 부하에서 2GHz.
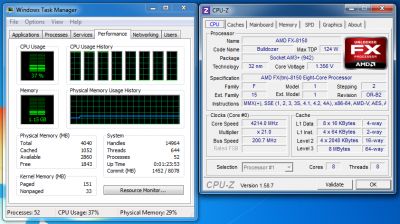
3이라는 것은 놀라운 일입니다.모든 프로세서 코어가 작동하는 경우에도 9GHz 주파수에 도달 할 수 있지만 전력 소비 및 열 소비 한도를 넘지 않고 자동 오버 클럭킹에 충분한 마진이 있습니다.
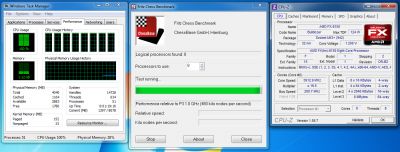
유휴 모드에서 시원합니다’N’조용한 기술은 FX-8150 프로세서의 시계 주파수를 1.4GHz. 이 경우 Vcore는 0으로 떨어집니다.85 v.
테스트 베드 구성
Bulldozer Microarchitecture의 새로운 8 코어 AMD FX-8150 프로세서를 전임자 중 하나 인 6 코어 Phenom II X6 및 인텔-쿼드 코어 코어 i5-2500 및 Core I7-2600의 경쟁자에 대한 새로운 8 코어 AMD FX-8150 프로세서를 비교할 것입니다. 또한 6 코어 코어 i7-990X CPU의 성능 숫자도 추가했습니다.
결과적으로 테스트 베드는 다음 하드웨어 및 소프트웨어 구성 요소를 사용하여 구축되었습니다
- 프로세서 :
- AMD FX-8150 (Zambezi, 8 Cores, 3.6GHz, 8 MB L2 + 8 MB L3);
- AMD PHENOM II X6 1100T (Thuban, 6 Cores, 3.3GHz, 3MB L2 + 6 MB L3);
- 인텔 코어 i7-2600K (Sandy Bridge, 4 Cores, 3.4GHz, 1MB L2 + 8 MB L3);
- 인텔 코어 i5-2500K (Sandy Bridge, 4 Cores, 3.3GHz, 1MB L2 + 6 MB L3);
- Intel Core i7-990X Extreme Edition (Gulftown, 6 Cores, 3.46GHz, 1.5 MB L2 + 12MB L3).
- 기가 바이트 990FXA-UD5 (소켓 AM3 +, AMD 990FX + SB950);
- ASUS P8Z68-V PRO (LGA1155, Intel Z68 Express);
- 기가 바이트 X58A-UD5 (LGA1366, Intel X58 Express).
- 2 x 2 GB, DDR3-1600 SDRAM, 9-9-9-27 (Kingston KHX1600C8D3K2/4GX);
- 3 x 2 GB, DDR3-1600 SDRAM, 9-9-9-27 (중요한 BL3KIT25664TG1608).
- 인텔 칩셋 드라이버 9.2.0.1030;
- 인텔 관리 엔진 드라이버 7.1.10.1065;
- 인텔 빠른 저장 기술 10.6.0.1022;
- AMD 촉매 11.10 디스플레이 드라이버.
현재 Windows 7 버전에서 모든 테스트를 실행했지만 AMD는이 OS의 작업 관리가’t 계산 스레드를 최적의 방식으로 분배합니다. Windows 7은 모든 스레드를 다른 모듈 내부의 코어로 주로 지시하는 것을 선호합니다. 실제로 각 모듈 내부의 공유 장치의 부하를 줄일 수 있기 때문에 실제로 가장 높은 상대 성능을 제공합니다. 그러나이 전략은 Turbo-Modes의 사용을 방지하며, 일부 듀얼 코어 프로세서 모듈이 전원 절약 모드에 있으면 시작될 수 있습니다.
다가오는 Windows 8 OS는 컴퓨터 스레드를 동일한 모듈 내의 코어에 다르게 할당합니다. 결과적으로 AMD는 일부 선택된 응용 프로그램에서 Zambezi 성능이 10%까지 증가 할 수 있다고 약속합니다.
성능
New Bulldozer Microarchitecture의 예상 효율성
실제 벤치마킹 부분에 도달하기 전에, 우리는 새로운 불도저 미세 아키텍처가 일반적으로 가능할 것으로 기대할 수있는 것을 예측하고 예측하기로 결정했습니다. 이를 달성하기 위해 우리는 새로운 프로세서를 K10의 다른 CPU와 비교하여 합성 적으로 생성 된 동일한 환경에서 Sandy Bridge Microarchitectures를 비교했습니다. 동일한 시계 주파수와 동일한 수의 활성 코어.
보다 정확하게 우리는 AMD FX-8150, PHENOM II X6 1100T 및 CORE I7-2600에서 3을 비교했습니다.6GHz 주파수 및 2 개의 활성 계산 코어 만. 실험의 순도를 보장하기 위해 모든 전원 절약 및 자동 청소 기술을 비활성화했습니다. 우리는 Sisoft Sandra 2011 Suite에서 간단한 합성 벤치 마크 세트를 사용했는데, 여기서 K10 Microarchitecture는 SSE3 이상의 모든 지침을 수동으로 비활성화했습니다’t 그들을 지원하십시오.
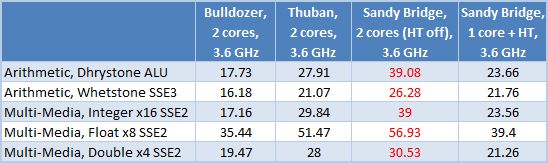
이 테이블의 숫자는 말보다 더 크게 말합니다. Bulldozer Microarchitecture의 성능은 이전 세대 프로세서의 성능보다 훨씬 낮아졌습니다. 한 쌍의 코어를 공유 리소스와 단일 모듈로 결합하여 Bulldozer Microarchitecture의 단순화로 인해 이전 세대 AMD Microarchitecture와 비교하여 특정 성능이 상당한 (25-40%) 감소했습니다. 결과적으로 불도저 코어는 모래 다리 코어의 절반으로 작동하지 않습니다. 두 개의 코어를 갖는 불도저 프로세서 모듈의 성능은 활성화 된 하이퍼 스레딩 기술을 갖춘 단일 샌디 브리지 코어의 성능보다 훨씬 낮습니다. 그러한 미세 구조로 CPU의 성과 기록을 기대해야합니까?? 이것은 더 많은 수사적 질문입니다…
동시에’s 캐시와 메모리 하위 시스템의 실질적인 특성을 살펴보십시오. 이 기능 단위의 성능을 추정하기 위해 AIDA64 Suite의 Cachemem 유틸리티에 의지했습니다. 우리는 9-9-9-27-1T 타이밍과 함께 DDR3-1600 SDRAM을 사용했습니다. 이전의 경우와 마찬가지로 프로세서는 모두 3시에 작동했습니다.6GHz 시계 주파수.
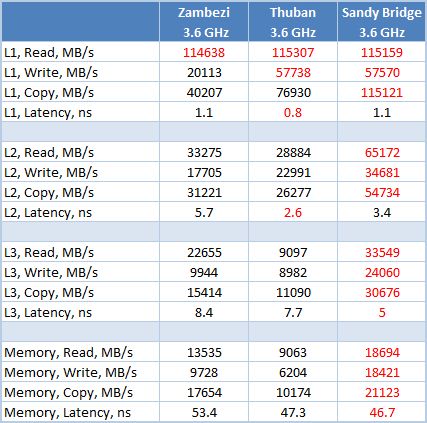
우리가 볼 수 있듯이 Zambezi 프로세서의 모든 캐시 및 메모리 하위 시스템의 실질적인 대기 시간이 증가했습니다. 우리는 이미 Bulldozer Microarchitecture에 전념하는 장에서 이미 논의했습니다. 그러나 내부 캐시 메모리 조직의 수정으로 인해 모든 경우에 메모리 대역폭이 거의 증가했습니다.
동시에 가장 빠른 듀얼 채널 메모리 컨트롤러와 가장 빠른 캐시 메모리 하위 시스템은 Sandy Bridge의 것입니다. 캐시 크기 측면에서는 NE 불도저가 우수합니다.
일반적인 성능
평소와 같이 Bapco Sysmark 2012 Suite를 사용하여 일반 목적 작업의 프로세서 성능을 추정합니다. 인기있는 사무실 및 디지털 컨텐츠 생성 및 처리 응용 프로그램의 사용 모델을 모방합니다. 이 테스트의 아이디어는 상당히 간단합니다. 평균 컴퓨터 성능을 특징으로하는 단일 점수를 생성합니다.
당신이 아마 기억 하듯이, 조금 뒤로 AMD는 Sysmark를 트롤하려고 시도했습니다’t 객관적인 벤치 마크 “불공정” 사용 된 응용 프로그램의 조합. 그러나 우리의 의견으로는,이 불만은 널리 퍼져 있고 실제로 인기있는 프로그램을 사용하여 추정 되었기 때문에 정당하지 않습니다. 최종 테스트 점수에 각 프로그램의 기여는 다음 다이어그램에 제공됩니다
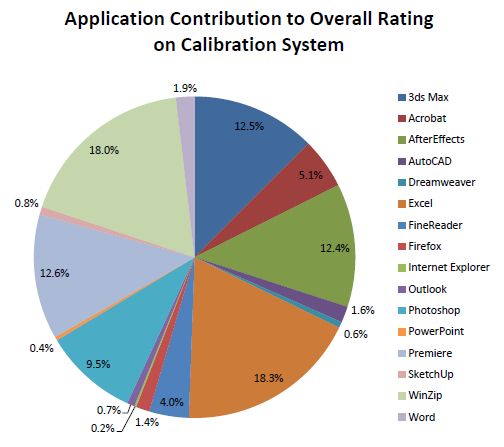
따라서 우리는 Sysmark 2012를 포기하지 않고이 제품군을 계속 사용하여 일반 목적 응용 프로그램의 성능을 추정했습니다.
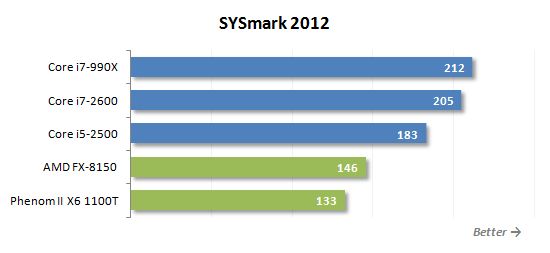
첫 번째 테스트는 큰 실망으로 밝혀졌습니다. 8 코어 FX-8150 프로세서는 6 코어 Phenom II X6 1100T보다 10% 빠르며 물론 쿼드 코어 인텔 CPU 뒤에 있습니다. 따라서 AMD처럼 보입니다’s는 적당한 수의 복잡한 코어를 사용하는 대신 낮은 특정 성능을 갖춘 많은 코어를 갖춘 프로세서를 구축하기로 결정했습니다’그들이 예상했던 것만 큼 작동합니다.
허락하다’s Sysmark 2012가 다양한 사용 시나리오에서 생성하는 성능 점수를 자세히 살펴보십시오.
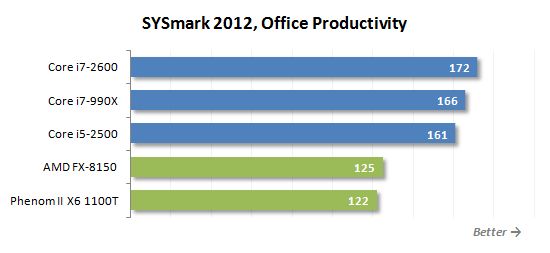
사무실 생산성 시나리오는 텍스트 편집, 전자 테이블 처리, 이메일 및 인터넷 서핑과 같은 일반적인 사무실 작업을 에뮬레이션합니다. 이 시나리오는 다음 응용 프로그램을 사용합니다. Abbyy Finereader Pro 10.0, Adobe Acrobat Pro 9, Adobe Flash Player 10.1, Microsoft Excel 2010, Microsoft Internet Explorer 9, Microsoft Outlook 2010, Microsoft PowerPoint 2010, Microsoft Word 2010 및 Winzip Pro 14.5.
미디어 제작 시나리오는 이전에 찍은 디지털 이미지 및 비디오를 사용하여 비디오 클립 생성을 모방합니다. 여기에서 그들은 인기있는 Adobe Suites를 사용합니다 : Photoshop CS5 Extended, Premiere Pro CS5 및 After Effects CS5.
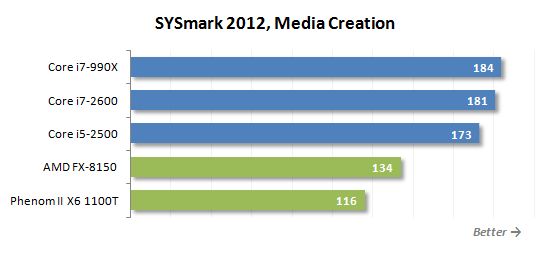
웹 개발은 웹 사이트 디자인을 모방하는 시나리오입니다. Adobe Photoshop CS5 확장, Adobe Premiere Pro CS5, Adobe Dreamweaver CS5, Mozilla Firefox 3.6.8 및 Microsoft Internet Explorer 9.
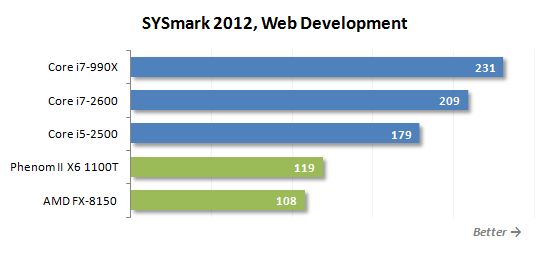
데이터/재무 분석 시나리오는 Microsoft Excel 2010에서 수행 된 통계 분석 및 시장 동향 예측에 전념합니다.
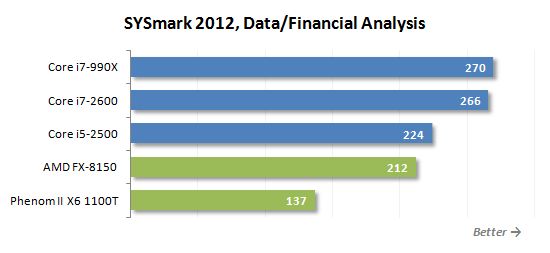
3D 모델링 시나리오는 Adobe Photoshop CS5 확장, Autodesk 3d Max 2011, Autodesk Autocad 2011 및 Google Sketchup Pro 8을 사용하여 3D 객체 및 정적 및 동적 장면 렌더링 전용 전용입니다.
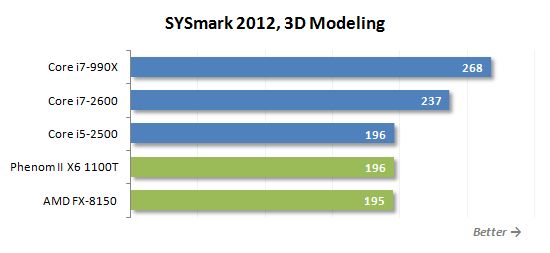
시스템 관리라는 마지막 시나리오는 백업을 생성하고 소프트웨어 및 업데이트를 설치합니다. 여기에는 여러 버전의 Mozilla Firefox 설치 프로그램 및 Winzip Pro 14가 포함됩니다.5.
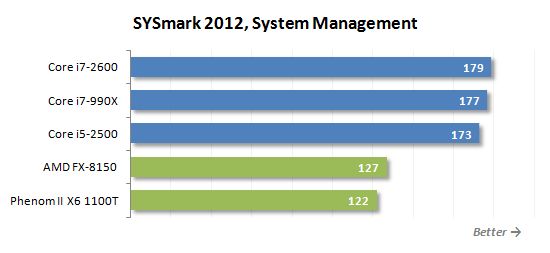
불도저 기반 프로세서는 다른 사용 모델에서 다른 결과를 보여줍니다. 어떤 경우에는 Phenom II X6보다 느리게 실행되지만 몇 가지 반대 상황도 있습니다. 전체적으로 일반 규칙은 다음과 같이 정의 될 수 있습니다. FX-8150은 다중 스레드 및 잘 알려진 부하가있는 응용 분야에서 특히 효율적이며 동시에 계산적으로 도전하지 않습니다.
그러나 가장 유리한 상황에서도 FX-8150은 핵심 i5-2500 뒤에 있습니다. 이 프로세서가 비슷한 속도를 보여주는 유일한 시나리오는 3D 렌더링입니다. 그 외에도 인텔 제품은 평균 25% 더 빠르며 슬프다…
게임 성능
아시다시피, 대부분의 현대 게임에서 상당한 고속 프로세서가 장착 된 전체 플랫폼의 성능을 결정하는 그래픽 하위 시스템입니다. 따라서 테스트 세션 중에 그래픽 카드가 너무 많이로드되지 않도록 최선을 다합니다. 우리는 가장 많은 CPU 의존성 테스트를 선택하고 모든 테스트는 항아리아를 사용하지 않고 가장 높은 화면 해상도가 아닙니다. 다시 말해, 얻은 결과는 현대 그래픽 가속기가 장착 된 시스템에서 달성 할 수있는 FPS 속도가 많지 않고 현대 프로세서가 게임 워크로드에 얼마나 잘 대처할 수 있는지를 분석 할 수 있습니다. 따라서 결과는 새로운 빠른 그래픽 카드 모델이 널리 사용될 때 테스트 된 CPU가 가장 가까운 미래에 어떻게 행동 할 것인지 결정하는 데 도움이됩니다.
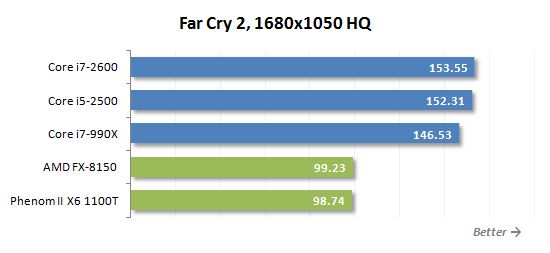
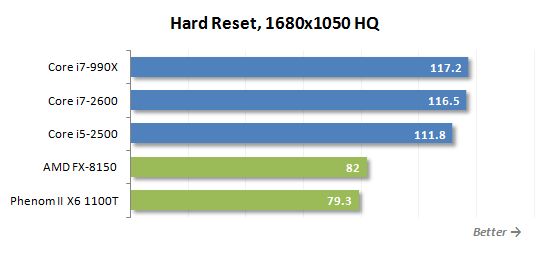
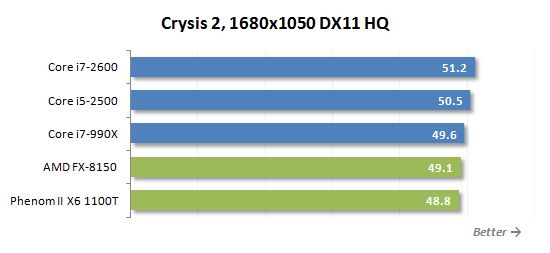
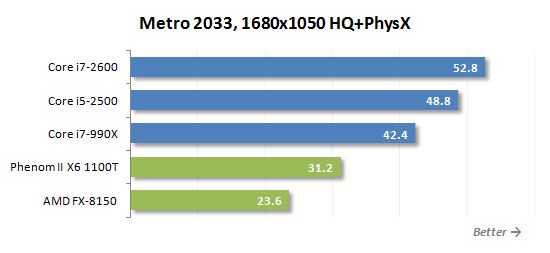

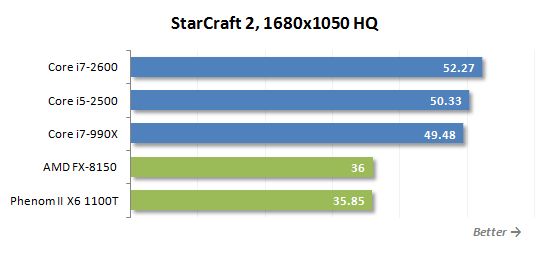
게임은 병렬 다중 스레드로드를 만드는 작업 중 하나가 아닙니다. 따라서 쿼드 코어 프로세서는 게이머에게 적합합니다’ AMD보다 훨씬 나은 것이 필요합니다’S 멀티 코어 몬스터. 위의 다이어그램은 그 좋은 예입니다. 새로운 8 코어 FX-8150은 6 코어 전임자보다 빠르지 않습니다. Phenom II X6.
Zambezi와 Sandy Bridge 간의 게임 성능 상관 관계에 관해서는 AMD에 대한 낙관적이지 않습니다. 현재 Intel Microarchitecture는 3D 게임에서 생성 된 일반적인 워크로드와 훨씬 더 잘 대처하며 AMD가 여기에서 경쟁을 따라 잡을 것이라는 희망은 전혀 없습니다. 다시 말해, 게임에 불도저를 사용하는 것이 의미가있는 유일한 시간은 특정 그래픽 하위 시스템 및 특정 게임에서 주어진 프로세서가 충분히 빠를 것이라고 확신 할 때 상황이 될 것입니다. 그러나이 경우에도 다음 그래픽 카드 업그레이드는 실제로 부정적인 영향을 미칠 수 있으며 처음에 인텔 플랫폼을 선호 한 사용자보다 최악의 상황에 처하게 될 것임을 이해하는 것이 중요합니다.
게임 테스트 외에도 Extreme Settings 프로필로 합성 FutureMark 3DMark11 테스트 실행 결과를 제공하고 싶습니다.
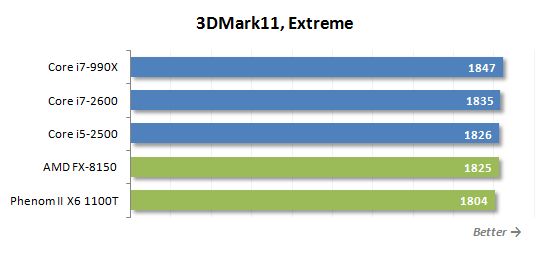
FX-8150의 이상적인 상황을 보여주기 위해이 결과를 추가했습니다. 즉, 비디오 하위 시스템이’실제로 프로세서가 잠재력을 최대한 발휘할 수 있도록. 이 경우 그래픽 카드가 최대로로드되고 CPU는 보조 기능을 수행합니다. 이 경우 불도저와 샌디 브리지 프로세서가 똑같이 빠르다고 말할 수 있지만, 이것이 사실이 아닙니다.
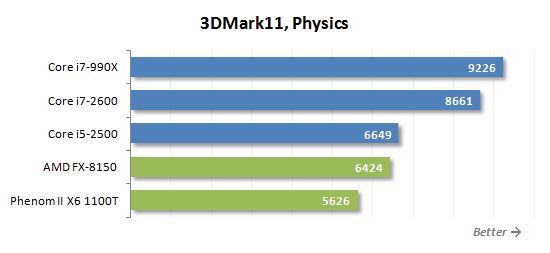
그러나 새로운 FX-8150은 3DMark11 Physics 테스트에서 매우 좋아 보입니다 (특히 이전 결과의 배경에 비해). 새로운 8 코어 AMD 프로세서는 게임 물리 모델의 멀티 스레드 계산 중에 쿼드 코어 인텔 코어 i5-2500과 비교하여 수행됩니다.
응용 프로그램의 성능
새로운 데스크톱 불도저의 일반 및 게임 공연은 우리가 예상했던 것보다 낮게 나타 났다고 말해야합니다. 그러나 우리는 포기하지 않고 새로운 AMD Microarchitecture가 실제로 빛날 상황을 찾을 준비가되어 있습니다.
데이터 보관 중 프로세서 성능을 테스트하기 위해 Winrar Archiving 유틸리티에 의지합니다. 최대 압축 속도를 사용하여 여러 파일로 폴더를 보관합니다 1.총 크기가 4GB.
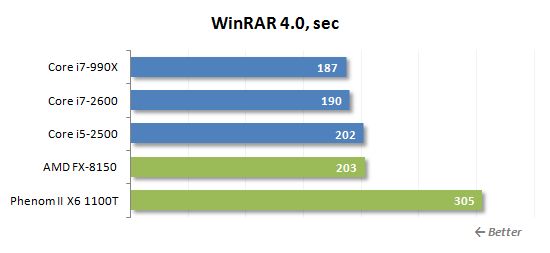
FX-8150 성능은 Core i5-2500의 성능에 가깝게 나타납니다. Winrar는 8 개의 불도저 코어 모두에 대한 8 개의 병렬 스레드로 하중을 분할 할 수있는 애플리케이션 중 하나는 아니지만 거대한 캐시 메모리는 여기에서 상황을 절약하는 것으로 보입니다.
아카이빙 속도의 두 번째 유사한 테스트는 LZMA2 압축 알고리즘을 사용하는 7-ZIP에서 수행됩니다.
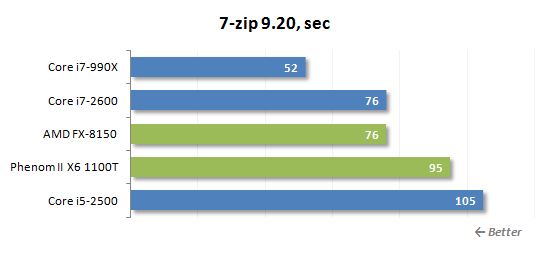
FX-8150은 7-zip에서 정말 훌륭합니다. 이 8 코어 프로세서는 활성화 된 하이퍼 스레딩이있는 쿼드 코어 코어 i7-2600에 매우 가깝습니다.
암호화 중 프로세서 성능은 TrueCrypt라는 인기있는 암호화 유틸리티의 통합 벤치 마크로 측정됩니다. 나는 그것이 수많은 프로세서 코어를 효과적으로 활용할 수있을뿐만 아니라 특수 AES 지침을 지원할 수 있다고 말해야합니다.

잘 평면이있는 단순한 정수 알고리즘은 Bulldozer Microarchitecture가 필요로하는 것입니다. 우리가 볼 수 있듯이이 경우 성능은 매우 인상적 일 수 있습니다. 즉, 유일한 프로세서 FX-8150은 할 수 있습니다’t 성능은 6 코어 코어 i7-990x였습니다. 모든 LGA1155 프로세서에 관해서는, 우리의 영웅.
우리는 Apple iTunes 유틸리티를 사용하여 오디오 트랜스 코딩 속도를 테스트합니다. CD 디스크의 내용을 AAC 형식으로 트랜스 코딩합니다. 이 유틸리티의 전형적인 특성은 한 쌍의 프로세서 코어를 활용하는 능력입니다.
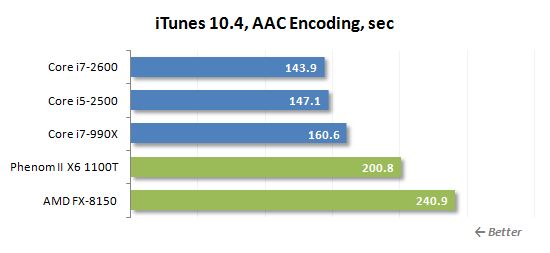
몇 가지 계산 스레드를 생성하는 응용 프로그램은 불도저와 잘 어울리지 않습니다. 이 프로세서의 개별 코어는 여기에서 잘 수행하기에는 너무 약합니다.
우리는 창의적으로 수정 된 Redouch Artists Photoshop Speed Test에서 만든 자체 벤치 마크를 사용하여 Adobe Photoshop의 성능을 측정했습니다. 디지털 사진 카메라에서 4 개의 10 메가 픽셀 이미지를 일반적인 편집하는 것이 포함됩니다.
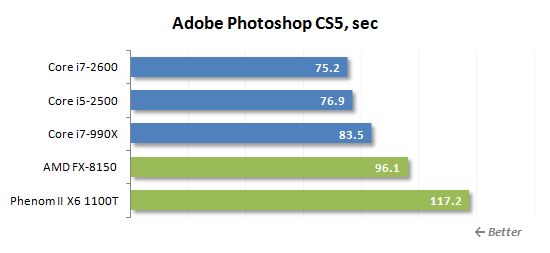
Photoshop에서 fx-8150에서’t는 K10 기반 프로세서만큼 제대로 성능을 발휘하지만 여전히 Core i5-2500을 따라 잡을 수 없습니다. 이 경우 대형 캐시 메모리는 불도저 소액 건축물을 많이 돕지 만 승리를 보장하기에는 충분하지 않습니다. 계산 코어의 효율성과 특정 성능은 여전히 주요 요인입니다.
우리는 또한 Adobe Photoshop Lightroom 3 프로그램에서 일부 테스트를 수행했습니다. 테스트 시나리오에는 후 처리 및 jpeg 형식으로 수백 12 메가 픽셀 이미지로 내보내기가 포함됩니다.
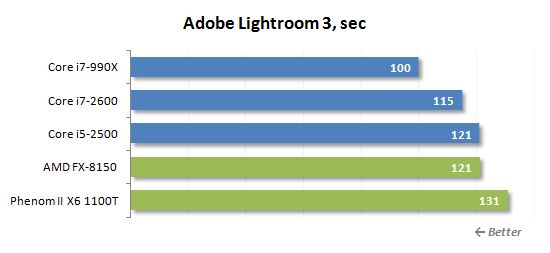
Lightroom은 수많은 코어들 사이에서 사진 처리를 분할 할 수 있으므로 8 코어 FX-8150은 여기에서 꽤 잘하는 이유입니다. 나는 그것을 인정해야하지만 “꽤 잘” 이 경우 매우 상대적인 용어로 간주 될 수 있습니다. 그 성능은 핵심 I5-2500의 성능과 비교할 수 있기 때문입니다. 따라서 두 개의 불도저 코어가 하이퍼 스레딩없이 하나의 샌디 브리지 코어와 동일하다는 것을 의미합니다.
Adobe Premiere Pro의 성능은 HDV 1080p25 비디오가있는 Blu-ray 프로젝트를 H로 렌더링하는 데 걸리는 시간에 따라 결정됩니다.264 형식과 다른 특수 효과를 적용하십시오.
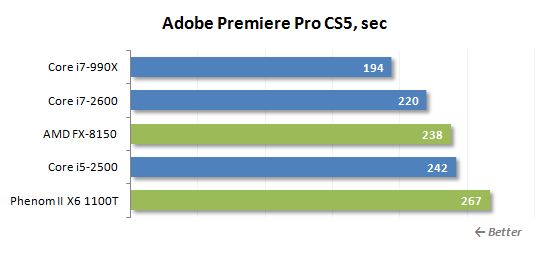
이전 세대 AMD 프로세서는 비디오 트랜스 코딩과 잘 대처했습니다. Bulldozer Microarchitecture는 이러한 유형의 응용 분야에서 더 나은 결과를 얻었으므로 FX-8150은 Core i5-2500보다 더 빠르게 성능.
블러, 벌지, 컬러 키, 프레임 블렌딩, 글로우, 모션 흐리기, 페이딩, 2D 및 3D 조작, 그림자, 에코, 중앙, 방사 방향 흐림, 인력 등과 같은 특수 효과의 조합을 적용하는 데 걸리는 시간을 측정하여 Adobe After Effects의 비디오 편집 속도를 추정했습니다.
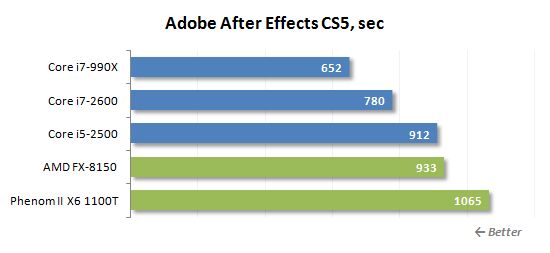
이것은 잘 알려진 부하 유형이지만, FX-8150.
테스트 참가자가 비디오를 H로 트랜스 코딩 할 수있는 정도를 측정하기 위해.264 형식 X264 HD 벤치 마크를 사용했습니다. 4Mbps 비트 전송률로 720p 해상도로 녹음 된 원래 MPEG-2 비디오와 함께 작동합니다. X264 코덱은 핸드 브레이크, Megui, VirtualDub 등과 같은 수많은 인기있는 트랜스 코딩 유틸리티의 일부이기 때문에이 테스트의 결과는 실질적인 가치가 있다고 말해야합니다.
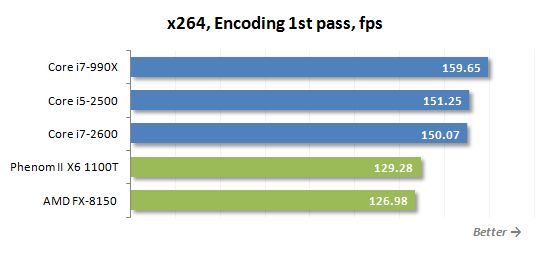
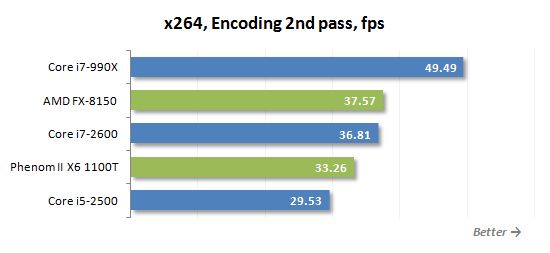
AMD 프로세서는 X264 비디오 트랜스 코딩 테스트 중에 항상 잘 수행되었습니다. 이제 8 코어 소액 건축물이 나왔으므로 결과가 더욱 향상되었습니다. FX-8150은 두 번째로 가장 자원이 많은 패스 중에 핵심 i7-2600보다 우수합니다. 마지막으로, 우리는 Bulldozer Microarchitecture의 프로세서가 절대적으로 훌륭하게하는 Truecrypt 외에 두 번째 응용 프로그램을 찾았습니다.
Autodesk 3ds Max 2011의 렌더링 속도는 특수 사양 테스트를 사용하여 측정되었습니다. 이 리뷰를 시작으로 우리는 3ds Max 2011에 새로운 전문 버전의 Specapc를 사용할 것입니다.
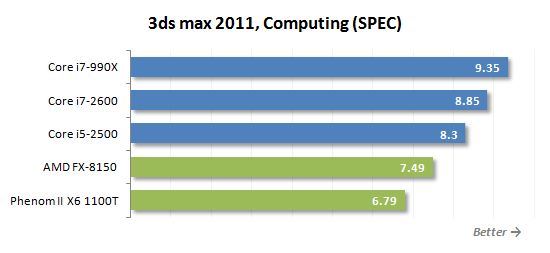
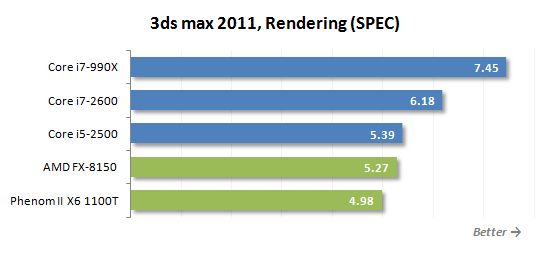
렌더링은 또한 작업이며, 다중 코어 미세 구조에 잘 최적화됩니다. 그러나이 사실에도 불구하고 FX-8150은 Core i5-2500 및 Core i7-2600보다 여전히 느리게 실행되며 Core i7-990X는 말할 것도 없습니다. 반면에, 새로운 AMD 프로세서는’t 전임자에게 잃어 버리므로 상황이 발생합니다’결국 T가 나쁘다.
개별 응용 분야에서 얻은 모든 결과를 요약하여 테스트에서 새로운 FX-8150이 Phenom II X6 1100T보다 약 14% 빠르다고 결론을 내릴 수 있습니다. 결과적으로 모든 테스트의 거의 절반에서 코어 i5-2500보다 느리지 않았습니다. 그러나 다음 인텔 모드 인 Core i7-2600의 지연은 여전히 꽤 심각하고 10%를 초과합니다.
전력 소비
불도저 성능이 상당히 좋은 응용 프로그램 세트를 찾을 수 있었지만이 새로운 마이크로 아키텍처를 기반으로 한 CPU는 혁명적 인 것으로 간주되지 않습니다. 이 시점에서 우리의 유일한 희망. 그러나 이제 새로운 미세 구조가 훨씬 더 에너지 효율적이라고 약속했습니다. 또한 새로운 미세한 32 nm 프로세스는 새로운 프로세서의 전기적 특성 개선에 기여해야합니다. 그래서,하자’S 새로운 FX-8150의 와트 당 성능을 확인하십시오.
아래 그래프는 전원 공급 장치 후 측정 된 컴퓨터 (모니터없이)의 전체 전력 드로우를 보여줍니다. 모든 시스템 구성 요소의 전력 소비의 총계입니다. PSU’S 효율은 고려되지 않습니다. CPU는 64 비트 LINX 0을 실행하여로드됩니다.6.4 유틸리티. 컴퓨터의 올바른 측정을 위해 모든 전원 절약 기술을 활성화했습니다’유휴 모드의 전력 드로우 : C1E, C6, AMD COOL’N’조용하고 향상된 인텔 스피드 스텝.
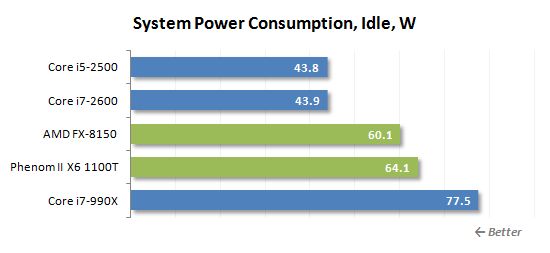
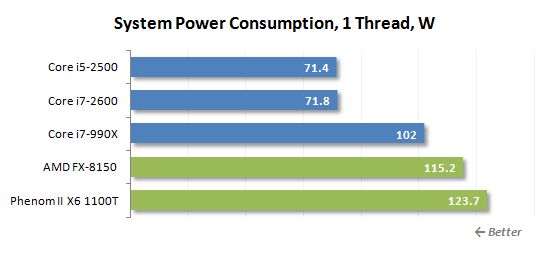
단일 스레드로드의 경우 소켓 AM3+ 시스템의 전력 소비가 빠르게 증가하며, 이는 공격적인 터보 코어 기술로 인해 발생할 가능성이 높습니다. Intel Base Systems는 그와 비슷한 것을 보여주지 않으며 다시 훨씬 더 나은 에너지 효율을 자랑 할 수 있습니다.
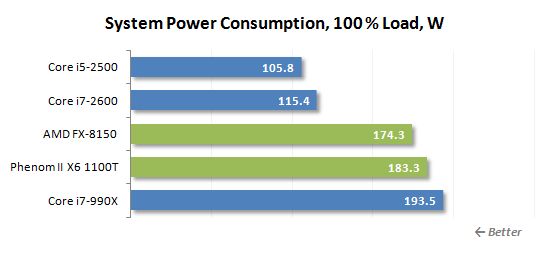
무거운 멀티 스레드로드의 경우 실제로는 크게 변하지 않습니다. 유일한 차이점은 코어 i7-990x가있는 LGA1366 시스템이 앞으로 돌진한다는 것입니다. 그렇지 않으면 상황이 정확히 동일합니다. FX-8150 캔’T는 특정 전력 절약 성공을 자랑합니다. 그것은 Phenom II X6 1100T보다 약간 적지 만 Intel Sandy Bridge 프로세서는 여전히 1 이상입니다.5 배 더 에너지 효율.
AMD는 새로운 마이크로 아키텍처에서 얻은 모든 에너지 효율을 사용하여 클럭 속도를 높였습니다. 그리고 결국 에너지 효율이나 성능에서 주로 크게 개선되지 않습니다. 따라서 와트 당 성과 측면에서 새로운 불도저는 전임자들과 마찬가지로 경쟁하는 인텔 미시적 구조물보다 여전히 심각하게 뒤떨어져 있습니다.
당신의 참조를 위해 여기에 고립 된 CPU 및 메인 보드 파워 레일의 전력 소비 판독 값이 있습니다
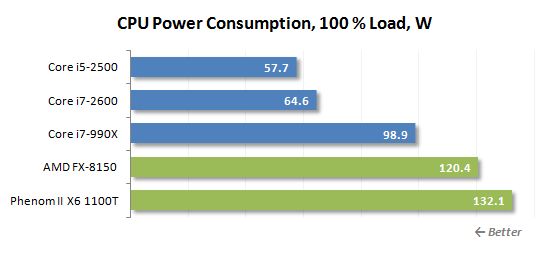
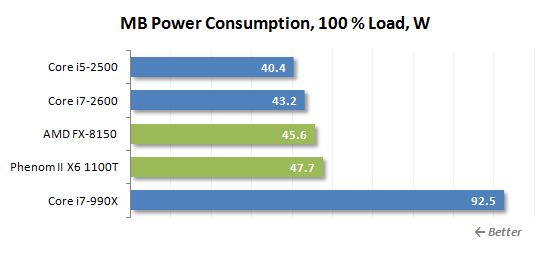
그만큼 “순수한” 8 코어 FX-8150의 전력 소비는 Sandy Bridge 프로세서의 전력 소비량보다 약 2 배입니다. 이들 모두는 동일한 생산 공정을 사용하여 제조되고 유사한 코어 전압을 가지고 있기 때문에 Bulldozer Microarchitecture의 에너지 효율이 정확히 AMD의 의미가 매우 흥미로워집니다.
오버 클로킹
소켓 AM3+ 플랫폼 및 FX 시리즈 프로세서는 처음부터 오버 클로킹 친화적으로 배치됩니다. 이는 모든 FX 프로세서가 멀티 플라이어 잠금 해제 된 사실뿐만 아니라 AMD가 지원하는 다수의 극단적 인 오버 클로킹 실험에서 나온 것입니다. 그 회사’고주파수에서의 작업을 위해 잘 최적화 된 새로운 마이크로 아키텍처에 대한 S 진술도 매우 유망한 것 같습니다. 새로운 오버 클로킹 경이가 될 수 있습니까?? 허락하다’s 알아 봅니다.
모든 FX 프로세서를 오버 클럭하는 것은 매우 쉽습니다. 로고 상태 “잠금 해제” 이런 이유로. 메인 보드 BIOS 설정에서 멀티 플라이어를 바로 변경하거나 AMD (Overdrive Utility)의 특수 유틸리티 및 메인 보드 공급 업체를 통해 프로세서 클록 주파수를 변경할 수 있습니다. 소켓 AM3+ 시스템의 통합 노스 브리지 및 시스템 메모리를 동일한 방식으로 오버 클럭 할 수도 있습니다.
테스트 중에 우리는 FX-8150을 4시에 안정적으로 일하게했습니다.6GHz. 안정성을 높이기 위해 프로세서 코어 전압을 1로 올렸습니다.475 V 및 활성화로드 라인 교정 옵션. 안정성을 테스트하는 동안이 주파수의 CPU 온도는’CPU 자체의 통합 열 다이오드에 따르면 T는 85 ° C 및 75 ° C를 초과합니다. 우리가 이미 말했듯이, 우리는 매우 효율적인 Air-Cooler-NZXT Havik 140을 사용했습니다.
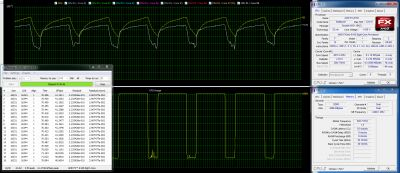
또한 주파수를 증가시키는 것은 L3 캐시 메모리 및 메모리 컨트롤러 성능에 긍정적 인 영향을 미치기 때문에 프로세서에 통합 된 North Bridge를 동시에 오버 클럭하려고했습니다. 그러나 불행히도 우리는 할 수있었습니다’t 2를지나갑니다.우리가 전압을 높이려고했지만 4GHz 주파수.
어쨌든 FX-8150 오버 클로킹 실험의 결과-4.6GHz 주파수 – 특히 AMD Phenom II 프로세서가 4를 넘어서 오버 클럭되지 않았기 때문에 확실한 성공입니다.기냉이가있는 0GHz. 다시 말해, 불도저 마이크로 아키텍처.
그러나 실제로 FX 프로세서 오버 클로킹 결과를 Intel Core I5 및 LGA1155 시스템의 Core I7 프로세서 결과와 비교해야합니다. 그리고이 사람들은 오버 클럭을 좋아합니다. 예를 들어, 코어 i5-2500K는 일반적으로 4로 오버 클럭됩니다.Air-Cooler에서 7GHz와 VCORE가 0만큼 증가했습니다.15 v. 그리고이 비교에서 FX-8150은’더 이상 너무 승리 해 보입니다.
오버 클럭 된 FX-8150과 코어 i5-2500K의 성능을 비교하면 잠 베지 오버 클로킹의 인상이 더욱 손상 될 것입니다 (공칭 모드와 비교하여 증가는 괄호 안에 제공됩니다)
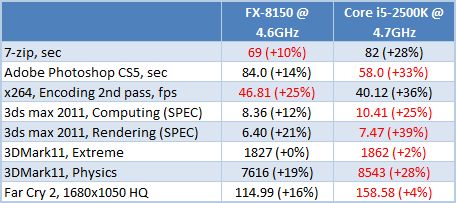
전반적으로 오버 클로킹은 그렇습니다’실제로 상황을 바꿉니다. 그러나 공칭 모드에서 FX-8150이 더 빠른 응용 분야에서는 더 이상 그 차이가 그렇게 극적이지 않습니다. 그리고 Core i5-2500이 앞서있는 테스트에서, 그것은 더 많은 위치를 강화했습니다. 실제로, FX-8150 프로세서의 클록 주파수는 오버 클로킹 중에 28% 증가한 반면 코어 i5-2500K의 주파수는 42% 더 높았습니다. 또한, 오버 클로킹 중에 주파수가 증가하는 방식에서 알 수 있듯이 Intel Sandy Bridge Microarchitecture는 주파수 증가에 더 민감합니다. 다시 말해, 우리가 오버 클로킹을 고려하더라도 새로운 불도저 프로세서는’T는 인텔보다 우월 해 보입니다’비록 그들이 꽤 잘 보이지만.
결론
따라서 성공 또는 실패입니다? 나는 여러분 대부분이 여기에서 명확하고 확실한 평결을보고 싶어 할 것이라고 확신합니다. 그러나 이번에는 상황이 그렇게 간단하지 않으며 AMD Bulldozer는 모든 리뷰어들에게 일을 정말 어렵게 만들었습니다.
문제는 AMD가 새로운 마이크로 아키텍처를 개발하는 데 완전히 독특한 접근 방식을 공개했다는 것입니다. 프로세서 성능은 시계 당 지침 수, 코어 주파수 및 코어 수와 같은 세 가지 주요 구성 요소로 구성되어 있으며 AMD 엔지니어는 이번에 우선 순위를 코어 수로 바꾸 었습니다. 그들은 특정 핵심 성능을 낮추었지만 동시에 저렴한 8 코어 또는 훨씬 더 복잡한 프로세서를 만들 수있는 기회를 얻었습니다. 이것은 다중 스레드 하중이 지배하고 멀티 코어 프로세서가 수요가 높은 서버 시장에서 매우 중요한 이정표입니다. 따라서 AMD의 새로운 Bulldozer Microarchitecture는 회사가 고성능 서버 부문에서 자신의 위치를 강화하는 데 도움이 될 것입니다.
그러나 오늘 우리는 새로운 Bulldozer Microarchitecture를 기반으로 FX 프로세서를 소개했지만 데스크탑 세그먼트 용으로 설계되었습니다. 그리고 이것은 우리가 불도저 사이의 불일치를 극적으로 관찰 한 곳입니다’S 하드웨어 기능 및 일반적인 데스크톱 응용 프로그램의 요구 사항. 전체 마케팅 노력이 불도저가 데스크탑 시장의 떠오르는 스타가 될 것이라고 믿게 만드는 것은 특히 실망 스럽습니다. 불행히도, 이것은 결코 일어나지 않았습니다.

Bulldozer Microarchitecture를 기반으로 한 FX 프로세서. 인기있는 응용 프로그램은 거의 없으며 간단한 멀티 스레드 정수 부하를 생성 할 수있는 인기있는 응용 프로그램이 거의 없으며 불도저가 실제로 최고의 공연을하는 유일한 경우입니다. 결과적으로, 특정 응용 분야에서 새로운 불도저는 인텔의 경쟁자보다 느리게 느리게 진행되며, 이전 세대 Phenom II X6보다 느리게됩니다. 그리고 그것은 AMD가하지 않았다는 것을 의미합니다’t 혁신적인 데스크탑 CPU를 시작하는 데 성공했습니다.
사실, FX는 또 다른 현상으로, 특히 전임자들과 비교할 때 꽤 좋아 보입니다. 전반적으로 FX 프로세서는 Phenom II보다 빠르고 훨씬 더 잘 클럭하고 전력이 약간 덜 소비하므로 Old K10 Microarchitecture에서 CPU를 대체 할 수 있습니다.
그러나 AMD가 그 자체뿐만 아니라 인텔과의 경쟁하고 있음을 상기시키고 싶습니다. 따라서 우리는 FX 프로세서가 주로 비디오 처리 및 트랜스 코딩에 사용될 데스크탑 시스템에만 적합한 선택이 될 것이라는 불쾌한 결론을 도출해야합니다. 다른 모든 경우에 불도저 프로세서는 불행히도 Sandy Bridge와 경쟁 할 수 없습니다. 전력 소비와 오버 클로킹에 대해서도 마찬가지입니다. 또한 AMD FX 프로세서가 게이머에게는 불량한 선택이 될 것으로 예상된다고 덧붙이고 싶습니다. 현대 3D 게임은 진정한 멀티 스레드 알고리즘을 거의 사용하지 않기 때문입니다. 그러나 게임의 FPS 속도가 대부분의 경우 프로세서가 아닌 그래픽 카드에 의해 제한되어 있기 때문에 전용 AMD 팬이이를 참을 수있을 것이라고 확신합니다.
다시 말해, 새로운 FX 프로세서의 마케팅 성공은 두 가지 요소에만 의존 할 것입니다. 그러나 데스크탑 불도저 기반 프로세서는 거의 인기가 없을 것입니다.

