
Facebook -134mg1q -webkit-align-se-si mesmo: Center-Ms-Flex-Item-Align: Center; Alinhado: centro; preenchimento: 0 10px; Visibilidade: escondida;. Radio de fronteira CSS-6Vrlzm: 0! importante; Exibição: inicial! importante; Margem: inicial! importante;. CSS-1L4S55V margem-top-175px; Posição: Absoluto; Botting-Bottom: 2px;
Consulte Configure um aplicativo do Facebook para obter informações sobre como configurar seu aplicativo do Facebook e encontrar o aplicativo segredo.
O Facebook usa MongoDB?
О эээ сйранibus
Ы з ззарегиgléria. С помощью этой страницы мы сможем определить, что запросы отправляете именно вы, а не робот. Почpels эээ моогitu произойth?
Эта страница отображается в тех случаях, когда автоматическими системами Google регистрируются исходящие из вашей сети запросы, которые нарушают Условия использования. Ponto. Ээth момо номттаая и оозз илэз и ээ и эз и эз и з и ззз и зз и ээз и ээз иth ээ эth ээзз эth эзз иthлз ио и зз и иth эз иээ эээо иth эз эээ ээо ээоо иth иэзз эth эзт эth эз ио эээ иth эз иэз иthлзз иоз ил иээ иээо иэээ иээо иth ио иээ эth иэ иээ эth иэ иээ эth ио иэ ээог seguir.
Ит и и и и и и и и и чззжfia м ирржжжfia м иржжжжfia м мжжжжжж<ь м м иржжжfia. não. Если вы используете общий доступ в Интернет, проблема может быть с компьютером с таким же IP-адресом, как у вас. Орратитеitivamente к с о и и с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с а с с а с а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а ”. ПодробнÉ.
Проверка по слову может также появляться, если вы вводите сложные запросы, обычно распространяемые автоматизированными системами, или же вводите запросы очень часто.
Autenticação do Facebook
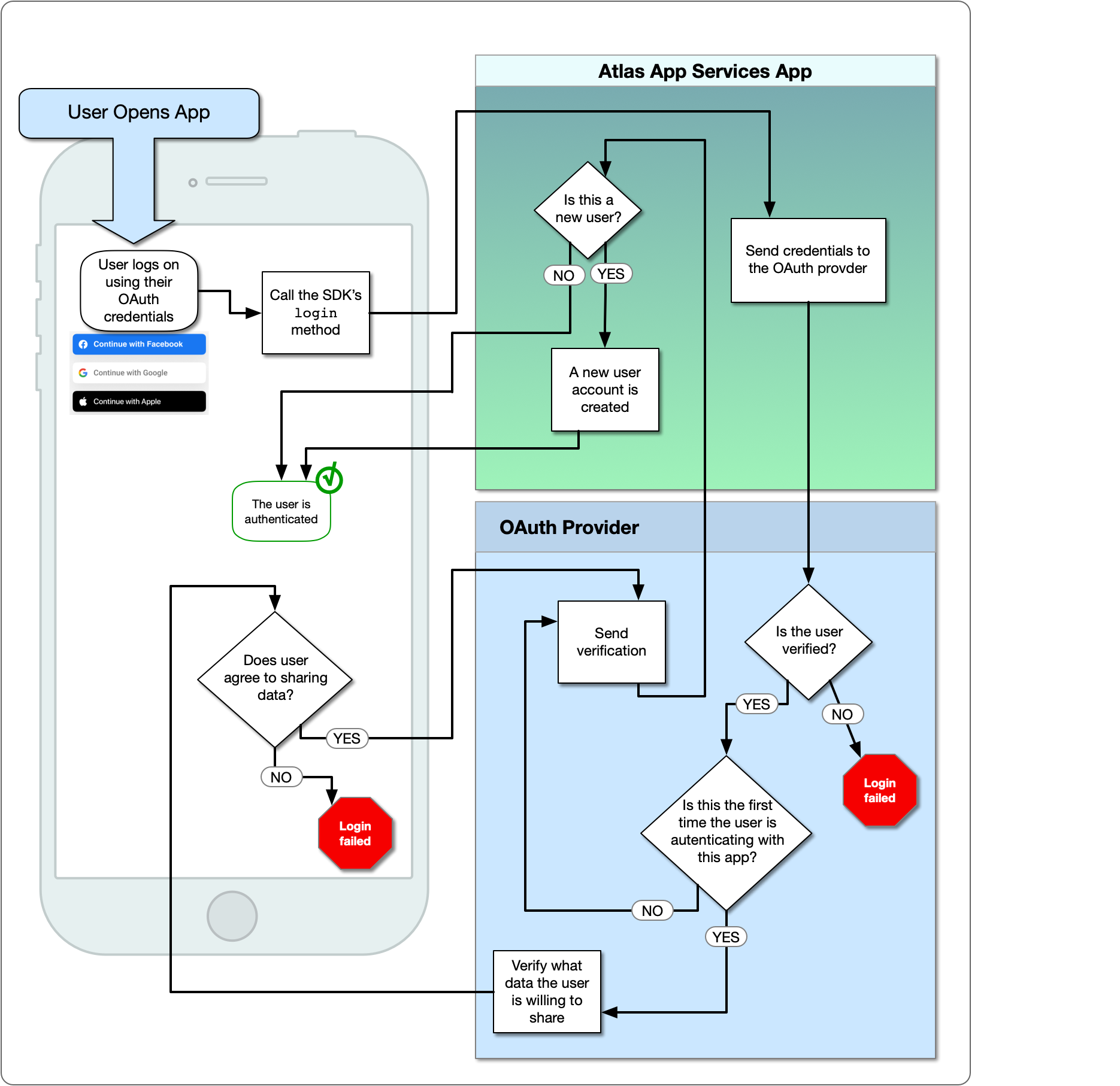
O provedor de autenticação do Facebook permite que os usuários façam login com sua conta do Facebook existente através de um aplicativo complementar do Facebook. Quando um usuário faz login, o Facebook fornece serviços de aplicativos Atlas com um OAuth 2.0 Acesso Token para o usuário. O App Services usa o token para identificar o usuário e acessar dados aprovados da API do Facebook em seu nome. Para obter mais informações sobre o Login do Facebook, consulte Login do Facebook para aplicativos.
O diagrama a seguir mostra o fluxo lógico do OAuth:
Configuração
O provedor de autenticação do Facebook possui as seguintes opções de configuração:
Descrição
Config.ID do Cliente
Obrigatório. O ID do aplicativo do aplicativo do Facebook.
Consulte Configure um aplicativo do Facebook para obter informações sobre como configurar seu aplicativo do Facebook e encontrar o ID do aplicativo.
Segredo do cliente
secret_config.clientes
Obrigatório. O nome de um segredo que armazena o segredo do aplicativo do aplicativo do Facebook.
Consulte Configure um aplicativo do Facebook para obter informações sobre como configurar seu aplicativo do Facebook e encontrar o aplicativo segredo.
Campos de metadados
metadata_fields
Opcional. Uma lista de campos descrevendo o usuário autenticado que seu aplicativo solicitará da API do gráfico do Facebook.
Todos os campos de metadados são omitidos por padrão e podem ser necessários em uma base campo a campo. Os usuários devem conceder explicitamente a permissão do seu aplicativo para acessar cada campo necessário. Se um campo de metadados for necessário e existir para um usuário em particular, ele será incluído em seu objeto de usuário.
Para exigir um campo de metadados de um arquivo de configuração de importação/exportação, adicione uma entrada para o campo à matriz Metadata_fields. Cada entrada deve ser um documento do seguinte formulário:
"" , ""
Banco de dados de usuários do Facebook – é SQL ou NOSQL?
Já se perguntou qual banco de dados Facebook (FB) usa para armazenar os perfis de seus 2.3b+ usuários? É SQL ou NOSQL? Como a arquitetura do banco de dados FB evoluiu nos últimos 15 anos? Como engenheiro na equipe de infraestrutura de banco de dados do FB de 2007 a 2013, tive um assento na primeira fila ao testemunhar essa evolução. Existem lições inestimáveis a serem aprendidas, entendendo melhor a evolução do banco de dados na maior rede social do mundo, embora a maioria de nós não enfrente exatamente os mesmos desafios em um futuro próximo. Isso ocorre porque os princípios fundamentais que sustentam a arquitetura de distribuição global e distribuída da Internet do FB se aplicam hoje a muitos aplicativos corporativos críticos de negócios, como SaaS multi-inquilinos, catálogo/check-out de produtos de varejo, reservas de viagens e tabelas de liderança para jogos.
Arquitetura inicial
Como qualquer usuário do FB pode entender facilmente, seu perfil não é simplesmente uma lista de atributos como nome, email, interesses e assim por diante. É de fato um rico gráfico social que armazena todos os relacionamentos de amigos/familiares, grupos, check-ins, curtidas, compartilhamentos e muito mais. Dada a flexibilidade de modelagem de dados do SQL e a onipresença do MySQL quando o FB começou, esse gráfico social foi inicialmente construído como um aplicativo PHP alimentado pelo MySQL como o banco de dados persistente e o memcache como um cache “Lookaside”.
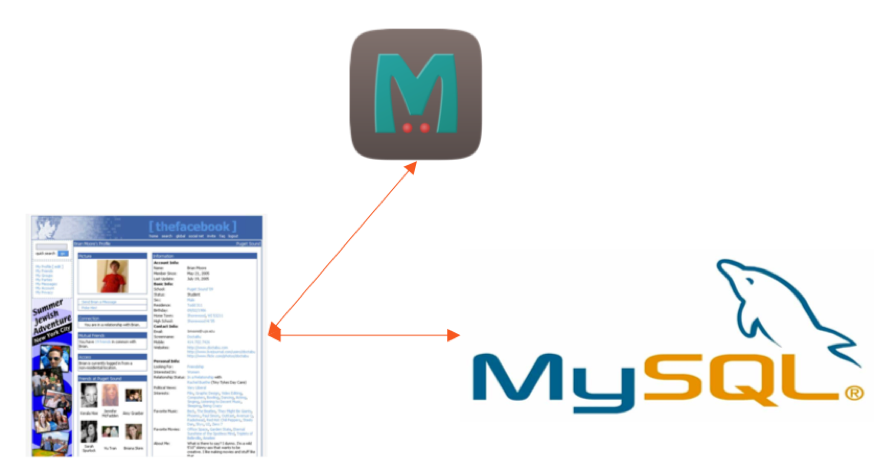
Arquitetura de banco de dados original do Facebook
No padrão de cache do Lookaside, o aplicativo primeiro solicita dados do cache em vez do banco de dados. Se os dados não forem armazenados em cache, o aplicativo recebe os dados do banco de dados de apoio e o coloca no cache para leituras subsequentes. Observe que o aplicativo PHP estava acessando MySQL e Memcache diretamente sem qualquer camada de abstração de dados intermediária.
Dores crescentes
Perda de agilidade do desenvolvedor
Os engenheiros tiveram que trabalhar com duas lojas de dados com dois modelos de dados muito diferentes: uma grande coleção de MySQL
Facebook -134mg1q -webkit-align-se-si mesmo: Center-Ms-Flex-Item-Align: Center; Alinhado: centro; preenchimento: 0 10px; Visibilidade: escondida;. Radio de fronteira CSS-6Vrlzm: 0! importante; Exibição: inicial! importante; Margem: inicial! importante;. CSS-1L4S55V margem-top-175px; Posição: Absoluto; Botting-Bottom: 2px;
Consulte Configure um aplicativo do Facebook para obter informações sobre como configurar seu aplicativo do Facebook e encontrar o aplicativo segredo .
O Facebook usa MongoDB?
О эээ сйранibus
Ы з ззарегиgléria. С помощью этой страницы мы сможем определить, что запросы отправляете именно вы, а не робот. Почpels эээ моогitu произойth?
Эта страница отображается в тех случаях, когда автоматическими системами Google регистрируются исходящие из вашей сети запросы, которые нарушают Условия использования. Ponto. Ээth момо номттаая и оозз илэз и ээ и эз и эз и з и ззз и зз и ээз и ээз иth ээ эth ээзз эth эзз иthлз ио и зз и иth эз иээ эээо иth эз эээ ээо ээоо иth иэзз эth эзт эth эз ио эээ иth эз иэз иthлзз иоз ил иээ иээо иэээ иээо иth ио иээ эth иэ иээ эth иэ иээ эth ио иэ ээог seguir.
Ит и и и и и и и и и чззжfia м ирржжжfia м иржжжжfia м мжжжжжж<ь м м иржжжfia. não. Если вы используете общий доступ в Интернет, проблема может быть с компьютером с таким же IP-адресом, как у вас. Орратитеitivamente к с о и и с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с с а с с а с а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а а ”. ПодробнÉ.
Проверка по слову может также появляться, если вы вводите сложные запросы, обычно распространяемые автоматизированными системами, или же вводите запросы очень часто.
Autenticação do Facebook
O provedor de autenticação do Facebook permite que os usuários façam login com sua conta do Facebook existente através de um aplicativo complementar do Facebook. Quando um usuário faz login, o Facebook fornece serviços de aplicativos Atlas com um OAuth 2.0 Token de acesso
para o usuário. O App Services usa o token para identificar o usuário e acessar dados aprovados da API do Facebook em seu nome. Para obter mais informações sobre o Login do Facebook, consulte Login do Facebook para aplicativos
O diagrama a seguir mostra o fluxo lógico do OAuth:
Configuração
O provedor de autenticação do Facebook possui as seguintes opções de configuração:
Descrição
Config.ID do Cliente
Obrigatório. O ID do aplicativo do aplicativo do Facebook.
Consulte Configure um aplicativo do Facebook para obter informações sobre como configurar seu aplicativo do Facebook e encontrar o ID do aplicativo .
Segredo do cliente
secret_config.clientes
Obrigatório. O nome de um segredo que armazena o segredo do aplicativo do aplicativo do Facebook.
Consulte Configure um aplicativo do Facebook para obter informações sobre como configurar seu aplicativo do Facebook e encontrar o aplicativo segredo .
Campos de metadados
metadata_fields
Opcional. Uma lista de campos descrevendo o usuário autenticado que seu aplicativo solicitará da API do gráfico do Facebook .
Todos os campos de metadados são omitidos por padrão e podem ser necessários em uma base campo a campo. Os usuários devem conceder explicitamente a permissão do seu aplicativo para acessar cada campo necessário. Se um campo de metadados for necessário e existir para um usuário em particular, ele será incluído em seu objeto de usuário.
Para exigir um campo de metadados de um arquivo de configuração de importação/exportação, adicione uma entrada para o campo à matriz Metadata_fields. Cada entrada deve ser um documento do seguinte formulário:
< nome: "", obrigatório: "" >
Facebook’s Banco de dados de usuário – é SQL ou NoSQL?
Já se perguntou qual banco de dados Facebook (FB) usa para armazenar os perfis de seus 2.3b+ usuários? É SQL ou NOSQL? Como a arquitetura do banco de dados FB evoluiu nos últimos 15 anos? Como engenheiro na equipe de infraestrutura de banco de dados do FB de 2007 a 2013, tive um assento na primeira fila ao testemunhar essa evolução. Existem lições inestimáveis a serem aprendidas, entendendo melhor a evolução do banco de dados no mundo’é a maior rede social, embora a maioria de nós vencesse’estarmos enfrentando exatamente os mesmos desafios em um futuro próximo. Isso ocorre porque os princípios fundamentais que sustentam o FB’A arquitetura de distribuição global em escala na Internet se aplica hoje a muitos aplicativos corporativos críticos de negócios, como SaaS de inquilinos com vários inquilinos, catálogo/checkout de produtos de varejo, reservas de viagens e tabelas de classificação de jogos.
Arquitetura inicial
Como qualquer usuário do FB pode entender facilmente, seu perfil não é simplesmente uma lista de atributos como nome, email, interesses e assim por diante. É de fato um rico gráfico social que armazena todos os relacionamentos de amigos/familiares, grupos, check-ins, curtidas, compartilhamentos e muito mais. Dada a flexibilidade de modelagem de dados do SQL e a onipresença do MySQL quando o FB começou, esse gráfico social foi inicialmente construído como um aplicativo PHP alimentado pelo MySQL como banco de dados persistente e memcache como um “olhe para o lado” cache.
Facebook’s Arquitetura de banco de dados original
No padrão de cache do Lookaside, o aplicativo primeiro solicita dados do cache em vez do banco de dados. Se os dados não forem armazenados em cache, o aplicativo recebe os dados do banco de dados de apoio e o coloca no cache para leituras subsequentes. Observe que o aplicativo PHP estava acessando MySQL e Memcache diretamente sem qualquer camada de abstração de dados intermediária.
Dores crescentes
Fb’S Sucessão meteórica a partir de 2005 em diante colocou uma tensão enorme sobre a arquitetura simplista de banco de dados destacada na seção anterior. A seguir, alguns dos engenheiros de crescimento do FB tiveram que resolver em um curto período de tempo.
Perda de agilidade do desenvolvedor
Os engenheiros tiveram que trabalhar com duas lojas de dados com dois modelos de dados muito diferentes: uma grande coleção de pares de escravos mestre MySQL para armazenar dados persistentemente em tabelas relacionais e uma coleção igualmente grande de servidores de memcache para armazenar e servir pares de valor-chave plano derivados (alguns indiretamente) dos resultados de SQL consultas. Trabalhar com o nível do banco de dados agora exigiu primeiro obter conhecimento intrincado de como as duas lojas funcionavam em conjunto. O resultado líquido foi perda na agilidade do desenvolvedor.
Sharding de banco de dados no nível do aplicativo
A incapacidade do MySQL de escalar solicitações de gravação além de um nó se tornou um problema assassino à medida que os volumes de dados cresceram aos trancos e barrancos. Mysql’s arquitetura monolítica essencialmente forçou o sharding no nível do aplicativo muito cedo. Isso significava que o aplicativo agora rastreava qual a instância do MySQL é responsável por armazenar qual usuário’perfil s. O desenvolvimento e a complexidade operacional crescem exponencialmente quando o número de tais instâncias cresce de 1 a 100s e, posteriormente, explodir em 1000s. Observe que a adesão a essa arquitetura significava que o aplicativo não usa mais o banco de dados para realizar junções e transações transversal, desistindo assim de todo o poder do SQL (como uma linguagem de consulta flexível) para dimensionar horizontalmente.
Replicação geogundante multi-dataacenter e geo-redundante
O manuseio de falhas do datacenter também se tornou uma preocupação crítica, o que significava armazenar escravos do MySQL (e instâncias correspondentes do memcache) em vários datacenters geográficos. Aperfeiçoar e operacionalizar failover não era uma tarefa fácil, mas, dada a replicação assíncrona de escravo mestre, dados recentemente comprometidos ainda estariam faltando sempre que esse failover era realizado.
Perda de consistência entre cache e db
O Memcache em frente a uma região remota MySQL Slave não pode servir imediatamente a leitura fortemente (também conhecida como leitura de leitura) por causa da replicação assíncrona entre o mestre e o escravo. E as leituras obsoletas resultantes na região remota podem facilmente levar a usuários confusos. E.g. Um pedido de amizade pode aparecer como aceito para um amigo enquanto aparece como ainda pendente para o outro.
Digite Tao, uma API de gráfico NoSQL no sql sharded
No início de 2009, o FB começou a construir o Tao, uma API de gráfico NOSQL específica do FB, construída para ser executada no Mysql sharded. O objetivo era resolver os problemas destacados na seção anterior. Tao significa “As associações e objetos”. Embora o design do TAO tenha sido publicado pela primeira vez como artigo em 2013, a implementação para o TAO nunca foi de origem aberta, dada a natureza proprietária do gráfico social do FB.
O TAO representou itens de dados como nós (objetos) e relacionamentos entre eles como bordas (associações). Os desenvolvedores de aplicativos do FB adoraram a API porque agora podiam gerenciar facilmente atualizações e consultas de banco de dados necessárias para sua lógica de aplicativo sem conhecimento direto do MySQL ou mesmo do Memcache.
Arquitetura
Conforme mostrado na figura abaixo, Tao essencialmente convertiu FB’s existentes 1000s de pares de escravos MySql-mestres de nó de manualmente para um cluster de banco de dados geo-distribuído altamente escalável e com discursos geográficos. Todos os objetos e associações no mesmo fragmento são armazenados persistentemente na mesma instância MySQL e são armazenados em cache no mesmo conjunto de servidores em cada cluster de cache. Colocação de objetos e associações individuais pode ser direcionada para fragmentos específicos no momento da criação quando necessário. Controlar o grau de colocação de dados provou ser uma importante técnica de otimização para fornecer acesso a dados de baixa latência.
Os padrões de acesso baseados em SQL, como transações de ácido transversal e junções. No entanto, apoiou escritos não atômicos não atômicos no contexto de uma atualização de associação (cujos dois objetos podem estar em dois fragmentos diferentes). Em caso de falhas após uma atualização do Shard, mas antes da segunda atualização do Shard, um trabalho de reparo assíncrono limparia o “pendurado” Associação posteriormente.
Os fragmentos podem ser migrados ou clonados para diferentes servidores no mesmo cluster para equilibrar a carga e suavizar picos de carga. Os picos de carga eram comuns e acontecem quando um punhado de objetos ou associações se torna extremamente popular à medida que aparecem nos feeds de notícias de dezenas de milhões de usuários ao mesmo tempo.
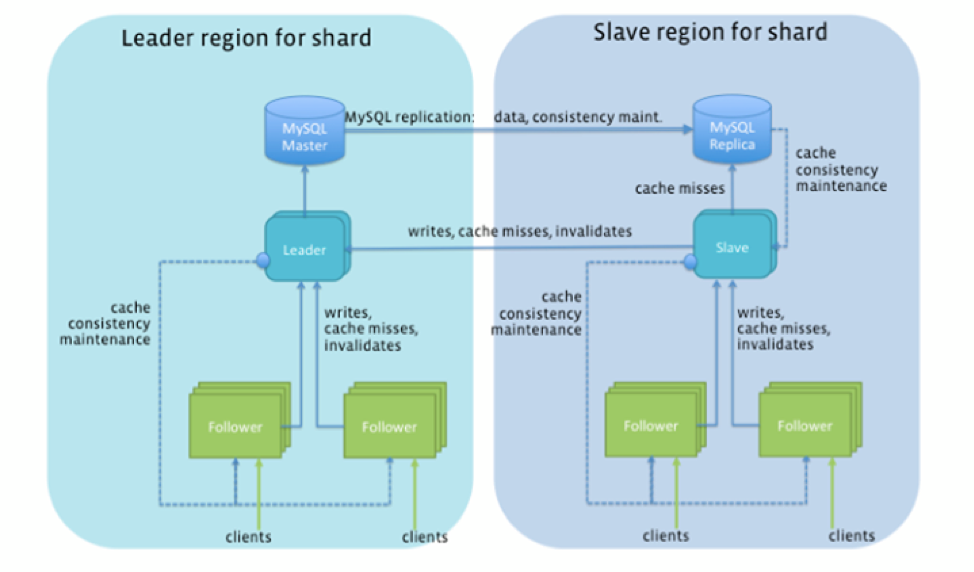
Existe uma solução corporativa de uso geral?
O FB não teve escolha a não ser escalar massivamente a camada de banco de dados MySQL responsável por seu usuário’s Social Gráfico. Nem o MySQL nem os outros bancos de dados SQL disponíveis naquele momento poderiam resolver esse problema por conta própria. Portanto, o FB usou sua engenharia significativa para criar essencialmente uma camada de consulta de banco de dados personalizada que abstraiu os bancos de dados MySQL subjacentes MySQL. Ao fazer isso, forçou seus desenvolvedores a desistir completamente do SQL como uma API de consulta flexível e adotar Tao’s API NOSQL Custom.
A maioria de nós no mundo corporativo não tem problemas em escala do Facebook, mas, no entanto. Adoramos o SQL por sua flexibilidade e onipresença, o que significa que queremos escalar sem desistir do SQL. Existe uma solução de uso geral para empresas como nós? A resposta é sim!
Olá SQL distribuído!
Os bancos de dados SQL monolíticos tentam há mais de 10 anos para se distribuir para resolver o problema de escala horizontal. Como “Aumento de bancos de dados SQL distribuídos globalmente” Destaques, a primeira onda desses bancos de dados foram chamados NewsQL e incluíam bancos de dados como Clustrix, Nuodb, Citus e Vitess. Estes tiveram sucesso limitado no deslocamento dos bancos de dados SQL manualmente fragmentados. O motivo é que o novo valor criado não é suficiente para simplificar radicalmente a experiência de desenvolvedor e operações. CLUSTRIX e NUODB Mandato especializado, altamente confiável e de baixa latência Infraestrutura – Infraestrutura nativa em nuvem moderna parece exatamente o oposto. Citus e Vitess simplificam a experiência de operações até certo ponto, afastando-se automaticamente no banco de dados, mas depois deficiente o desenvolvedor, não dando a ele um único banco de dados SQL distribuído lógico.
Agora estamos na segunda geração de bancos de dados SQL distribuídos, onde a enorme escalabilidade e a distribuição global de dados são incorporadas na camada de banco de dados, em oposição a 10 anos atrás, quando o Facebook teve que criar esses recursos na camada de aplicativos.
Inspirado no Google Spanner
Enquanto o FB estava construindo o TAO, o Google estava construindo Spanner, um banco de dados completamente consistente globalmente para resolver desafios muito semelhantes. Spanner’S O modelo de dados era menos um gráfico social, mas mais uma carga de trabalho tradicional e de acesso aleatório OLTP que gerencia o Google’s usuários, organizações de clientes, créditos do Google AdWords, Preferências do Gmail e muito mais. Spanner foi apresentado pela primeira vez ao mundo na forma de um artigo de design em 2012. Tudo começou em 2007 como uma loja de valor-chave transacional, mas depois evoluiu para um banco de dados SQL. A mudança para o SQL como o único idioma do cliente acelerou, pois o Google Engineers percebeu que o SQL tem todos os construtos certos para o desenvolvimento de aplicativos ágeis, especialmente na era nativa da nuvem, onde a infraestrutura é muito mais dinâmica e propensa a falhas do que os datacenters privados altamente confiáveis do passado. Hoje, vários bancos de dados modernos (incluindo YugabytedB) trouxeram o design do Google Spanner à vida completamente em código aberto.
Lidar com o volume de dados em escala na Internet com facilidade
O sharding é completamente automático na arquitetura Spanner. Além disso, os fragmentos ficam equilibrados automaticamente em todos os nós disponíveis, à medida que novos nós são adicionados ou os nós existentes são removidos. Os microsserviços que precisam de escalabilidade de gravação maciça agora podem contar com o banco de dados diretamente em vez de adicionar novas camadas de infraestrutura semelhantes às que vimos na arquitetura do FB. Não há necessidade de um cache na memória (que descarrega as solicitações de leitura do banco de dados, liberando-o para servir solicitações de gravação) e também não há necessidade de uma camada de aplicativo do tipo Tao que faça gerenciamento de shard.
Extrema resiliência contra falhas
Uma diferença fundamental entre os bancos de dados do Spanner e os Legacy NewsQL que analisamos na seção anterior é Spanner’s O uso de consenso distribuído por cliques para garantir que cada fragmento (e não simplesmente cada instância) permaneça altamente disponível na presença de falhas. Semelhante ao TAO, as falhas de infraestrutura sempre afetam apenas um subconjunto de dados (apenas os fragmentos cujos líderes são divididos) e nunca todo o cluster inteiro. E, dada a capacidade das replicas restantes de shard de eleito automaticamente um novo líder em segundos, o cluster exibe características de autocura quando submetidas a falhas. O aplicativo permanece transparente para essas alterações de configuração de cluster e continua a funcionar normalmente sem interrupções ou desacelerações.
Replicação perfeita em todo o mundo
O benefício de uma arquitetura de banco de dados consistente globalmente é que os microsserviços que precisam de dados absolutamente corretos em cenários de gravação multi-zona e multi-region podem finalmente confiar no banco de dados diretamente. Conflitos e perda de dados observados em implantações típicas de vários mestres do passado não ocorrem. Recursos como a participação geográfica no nível da tabela e no nível da linha garantem que os dados relevantes para a região local permaneçam líderes na mesma região. Isso garante que o caminho de leitura fortemente consistente nunca incorre em latência cruzada/wan.
Poder total do SQL e transações de ácido distribuído
Ao contrário dos bancos de dados do NewsQL Legacy, as transações SQL e ácido em seu formulário completo podem ser suportadas na arquitetura Spanner. As operações de chave única são, por padrão, fortemente consistentes e transacionais (o termo técnico é linearizável). As transações de um pouco do lado, por definição. As transações ácidas multi-Shard (também conhecidas como distribuídas) envolvem uma composição de duas fases usando um gerenciador de transações distribuído que também rastreia o relógio se inclina nos nós. As junções multi-shard são tratadas da mesma forma por consultas de dados nos nós. A chave aqui é que todas as operações de acesso a dados são transparentes ao desenvolvedor que simplesmente usa construções regulares de SQL para interagir com o banco de dados.
Resumo
A infraestrutura de dados Scaling Stories em qualquer um dos gigantes da tecnologia, incluindo FB e Google, contribui para um ótimo aprendizado de engenharia. No FB, seguimos o caminho da construção do Tao, o que nos permitiu preservar nosso investimento existente em Mysql sharded. Nossos engenheiros de aplicativos perderam a capacidade de usar o SQL, mas ganharam vários outros benefícios. Os engenheiros do Google foram confrontados com desafios semelhantes, mas escolheram um caminho diferente criando Spanner, um banco de dados SQL totalmente novo que pode escalar horizontalmente, perfeitamente replicado geo e toleram facilmente falhas de infraestrutura. FB e Google são histórias de sucesso incríveis, por isso não podemos dizer que um caminho era melhor que o outro. No entanto, quando expandimos o horizonte para arquiteturas corporativas de uso geral, Spanner vem à frente de Tao por causa de todas as razões destacadas neste post. Construindo YugabytedB’S Camada de armazenamento na arquitetura Spanner, acreditamos que podemos trazer a agilidade do desenvolvedor dos gigantes da tecnologia para as empresas de hoje.
Atualizado em março de 2019.
O que’está a seguir?
- Compare Yugabytedb em profundidade com bancos de dados como barraca, google nuvem spanner e mongodb.
- Comece com Yugabytedb no macOS, Linux, Docker e Kubernetes.
- Entre em contato conosco para saber mais sobre licenciamento, preços ou para agendar uma visão geral técnica.
Conectar
Leads do Facebook
para MongoDB
Depois de fazer a integração com o MongoDB, as seguintes opções estarão disponíveis: agora você tem a capacidade de automatizar a transferência de leads do Facebook para o MongoDBB. Ao fazer isso, você pode automatizar seus processos de negócios e economizar tempo.
Vote para criar uma integração com o MongoDB
SYNC Facebook leva a MongoDB
Quero transferir automaticamente leads do Facebook? No momento, não temos uma integração pronta com o MongoDB, mas nossos desenvolvedores estão trabalhando nessa integração.
Depois de concluirmos a integração, você não precisará baixar manualmente leads do Facebook para MongoDB. Nosso sistema verificará novos leads 24 horas por dia, 7 dias por semana. Sem dias de folga e feriados.
Em breve

Integrar em 1 clique
Integrar o Facebook lidera anúncios com MongoDB
Como vai funcionar?
- Savemyades constantemente monitora informações sobre novos leads no Facebook
- Assim que um novo lead aparece, nosso serviço levará automaticamente todos os dados sobre o líder e o transferirá para o MongoDB.
O que você precisa para começar?
- Conecte a conta de anúncios do Facebook Leads
- Conecte a conta do MongoDB
- Ativar transferência de leads do Facebook para MongoDB
Vote na integração com o MongoDB. Quanto mais votos, mais rápido faremos a integração. A forma de votação está no topo da página.
Perguntas e respostas sobre o Connect & Sync Facebook Leads com MongoDB
Como integrar os leads do Facebook e MongoDB?
Depois de concluirmos a integração:
- Você precisa se registrar em savemyades
- Escolha quais dados transferir do Facebook para MongoDB
- Ligue a atualização automática
- Agora os dados serão transferidos automaticamente do Facebook para o MongoDB
Quanto tempo leva para integrar o Facebook leva ao MongoDB?
Dependendo do sistema com o qual você integrará, o tempo de configuração pode variar e variar de 5 a 30 minutos. Em média, a configuração leva de 10 a 15 minutos.
Quanto custa integrar o Facebook com o MongoDB?
Oferecemos planos para diferentes volumes de tarefas. Vou ao “Preço” seção e escolha o conjunto de funcionalidades que melhor atende às suas necessidades. Além disso, você tem a oportunidade de testar o serviço gratuitamente por 14 dias.
Quantos serviços prontos para integração e enviar leads do FB?
Teremos mais de 40 integrações prontas.
O que é MongoDB?
MongoDB é um sistema de gerenciamento de banco de dados. Não requer uma descrição do esquema da tabela e é um exemplo clássico de um sistema NOSQL. A plataforma está escrita em C ++. Usado na programação, suporta solicitações ad-hoc. Ele implementa uma pesquisa entre expressões regulares e você também pode personalizar consultas para retornar conjuntos aleatórios de resultados. Ele suporta índices e sabe como trabalhar com conjuntos de réplicas, ou seja, você pode salvar 2 ou mais cópias de dados em diferentes nós. Cada cópia pode atuar como uma réplica primária ou secundária. As gravações de leitura são feitas pela cópia mestre. Auxiliares mantêm os dados atualizados. Se a cópia mestre não funcionar, o sistema escolhe qual cópia se torna o mestre.
A escala do sistema é horizontal de acordo com as regras para segmentar bancos de dados com distribuição em peças em diferentes nós do cluster. A chave de emulação é determinada pelo administrador, bem como pelo critério segundo o qual os dados serão espalhados pelos cantos. A carga é equilibrada porque os pedidos podem ser aceitos por todos os nós no cluster. MongoDB pode ser usado para armazenar arquivos. O sistema divide os arquivos em peças e armazena cada uma delas como um documento independente.
Desde 2018, a versão 4 adicionou suporte para transações que atendem aos regulamentos de ácido. Os motoristas oficiais são fornecidos para todas as principais linguagens de programação. Além disso, um grande número de motoristas não oficiais foram desenvolvidos, que são lançados por desenvolvedores de terceiros. Eles são apoiados pela comunidade e podem ser usados para outros idiomas e estruturas. A interface do banco de dados foi fornecida pelo invólucro do MongoDB, mas todas as versões com mais de 3º recebimento receberam bússola MongoDB em vez.
Se você deseja se conectar, integrar ou sincronizar o Facebook lidera anúncios com o MongoDB – cantar agora e em 5 minutos novos leads serão enviados automaticamente para o MongoDBB. Experimente uma avaliação gratuita!

