
O Facebook tem seus próprios data centers?
Resumo:
Atualmente, a Meta (anteriormente Facebook) possui 47 data centers em construção, com planos de ter mais de 70 edifícios em um futuro próximo. Isso reflete a expansão da infraestrutura global da empresa, com 18 campi de data center em todo o mundo, totalizando 40 milhões de pés quadrados. Apesar dos desafios colocados pelas interrupções da pandemia e da cadeia de suprimentos, a Meta espera investir entre US $ 29 bilhões e US $ 34 bilhões em despesas de capital em 2022.
Pontos chave:
- Meta tem 47 data centers em construção e planos para mais de 70 edifícios em um futuro próximo.
- A empresa possui 18 campi de data center em todo o mundo.
- A expansão durante a pandemia e as interrupções da cadeia de suprimentos é um desafio.
- A Meta espera investir entre US $ 29 bilhões e US $ 34 bilhões em despesas de capital em 2022.
- Operadores de hiperescala como Meta e Microsoft estão despejando bilhões para expandir sua infraestrutura de data center.
- Open Compute Project, fundado pelo Facebook, impulsiona a inovação em hardware.
- A construção de data center requer processos flexíveis de seleção e construção de locais.
- Meta procura vendedores e contratados como parceiros na condução de melhores práticas e melhorias contínuas.
- Meta e outros operadores de hiperescala são pioneiros em novas estratégias para fornecer escala e velocidade.
- A escala e o desafio do programa de data center é uma força motriz para meta.
Questões:
- Qual é o status atual da construção de data center da Meta?
- Quantos campi de data centers meta têm em todo o mundo?
- Que desafios a meta enfrenta a expansão do data center?
- Quanto meta planeja investir em despesas de capital em 2022?
- Quais empresas também estão investindo em expansão de infraestrutura de data center?
- Qual é o papel do projeto de computação aberta?
- Quais fatores são importantes na construção de data centers?
- Como a meta vê vendedores e contratados?
- Quais estratégias são meta e outros operadores de escala de hiperescala pioneiros?
- O que impulsiona o programa de data center do Meta?
Atualmente, a Meta tem 47 data centers em construção, com planos para mais de 70 edifícios em um futuro próximo.
Meta tem 18 campi de data center em todo o mundo.
A expansão do data center durante a pandemia e as interrupções da cadeia de suprimentos apresenta desafios para a meta.
A Meta espera investir entre US $ 29 bilhões e US $ 34 bilhões em despesas de capital em 2022.
Operadores de hiperescala como a Microsoft também estão investindo bilhões na expansão de sua infraestrutura de data center.
O projeto de computação Open, fundada pelo Facebook, impulsiona a inovação em hardware.
A construção de data center requer processos flexíveis de seleção e construção de locais.
Meta vê fornecedores e contratados como parceiros na condução de melhores práticas e melhorias contínuas.
Meta e outros operadores de hiperescala são pioneiros em novas estratégias para fornecer escala e velocidade.
A escala e o desafio do programa de data center é uma força motriz para meta.
O Facebook tem seus próprios datacenters
O que mais o Facebook tira? Frankovsky disse que “muitas placas -mãe hoje vêm com muita gestão Goop. Esse é o termo técnico que eu gosto de usar para isso.”Este Goop pode ser o mecanismo de gerenciamento de ciclo de vida integrado da HP ou as ferramentas de gerenciamento de servidor remoto da Dell.
O Facebook tem 47 data centers em construção
Atualmente, a Meta possui 47 data centers em construção, informou a empresa nesta semana, refletindo o escopo extraordinário da expansão contínua do mundo’s infraestrutura digital.

Isto’S uma breve declaração, no fundo de uma longa revisão da inovação no Facebook’s infraestrutura digital. Mas para quem conhece a indústria do data center, é’é um verdadeiro surpresa.
“Como eu’estou escrevendo isso, temos 48 edifícios ativos e outros 47 edifícios em construção,” disse Tom Furlong, presidente de infraestrutura, data centers da Meta (anteriormente Facebook). “Então nós’vou ter mais de 70 edifícios em um futuro próximo.”
A declaração reflete o escopo extraordinário da meta’S expansão global de infraestrutura. A empresa possui 18 campi de data center em todo o mundo, que após a conclusão abrangem 40 milhões de pés quadrados de espaço para data center.
Ter 47 edifícios em construção seria um desafio em qualquer circunstância, mas principalmente durante uma pandemia global e interrupção da cadeia de suprimentos. Isto’não é fácil ou barato. A Meta diz que espera investir entre US $ 29 bilhões e US $ 34 bilhões em despesas de capital em 2022, contra US $ 19 bilhões no ano passado.
Isto’não está sozinho, pois os maiores operadores de hiperescala estão despejando bilhões de dólares para expandir sua infraestrutura de data center para atender à demanda por seus serviços digitais. Os gastos com hiperescalas aumentaram 30 % no primeiro semestre de 2021, de acordo com uma análise do Synergy Research Group, que rastreia 19 provedores de hiperescala que gastaram cerca de US $ 83 bilhões no período de seis meses.
Esses níveis de gastos podem aumentar facilmente, à luz do Facebook’S Projeções sobre os futuros gastos com Capex e Microsoft’s planeja construir de 50 a 100 data centers por ano.
Inovação de infraestrutura em escala épica
Furlong’s Postagem de blog sobre meta’S Data Center Journey vale a pena ler, assim como um post complementar que relembra o progresso do projeto de computação aberta, a iniciativa de hardware Open fundado pelo Facebook em 2011.
“Open Hardware impulsiona a inovação, e trabalhar com mais fornecedores significa mais oportunidades de desenvolver hardware de próxima geração para oferecer suporte a recursos atuais e emergentes na Meta’S Família de Tecnologias.,” Furlong escreve.
A necessidade de inovar em escala também inclui a construção de data centers.
“Há muita atividade nas indústrias de data center e na construção hoje, o que nos pressiona para encontrar os sites e parceiros certos,” disse Furlong. “Isso também significa que precisamos criar processos mais flexíveis de seleção e construção de sites. Todo esse esforço também envolve olhar mais para nossos fornecedores e contratados como parceiros em tudo isso. Pudermos’T apenas faço isso sobre dólares. Temos que fazer isso sobre o desempenho. Temos que fazer isso sobre a condução das melhores práticas e a melhoria contínua.
“Mas isso’não é a maneira como a indústria da construção normalmente funciona,” Ele continuou. “Então, nós’Tive que trazer muitas de nossas próprias idéias sobre operações de corrida e fazer melhorias e impressioná -las nas empresas com as quais trabalhamos.”
A infraestrutura digital está se tornando mais importante todos os dias, e a Meta e suas contrapartes em hiperescala são pioneiras em novas estratégias para fornecer a escala e a velocidade de que precisam. Isto’é um processo contínuo, como Furlong reflete.
“Mudar para a arena do data center nunca seria fácil,” ele escreve. “Mas acho que nós’Acabei com um programa incrível em uma escala que eu nunca teria imaginado. E nós’está sempre sendo solicitado a fazer mais. Que’é o desafio de negócios, e isso’é provavelmente uma das principais coisas que mantêm eu e minha equipe entrando para trabalhar todos os dias. Temos esse enorme desafio pela frente de fazer algo que é inacreditavelmente massivo em escala.”
O Facebook tem seus próprios datacenters


Voltar para o blog em casa
20 2016
Infraestrutura do Facebook: Inside Data Center Strategy and Development
Por meta carreiras
Rachel Peterson lidera a equipe de estratégia de data center de infraestrutura do Facebook. Sua equipe gerencia o portfólio de data center do Facebook e fornece suporte estratégico para identificar oportunidades para mais infraestrutura de sustentabilidade, eficiência e confiabilidade. Dê uma olhada em sua experiência no Facebook e como sua equipe está trabalhando para conectar o mundo.
Qual é a sua história do Facebook?
Entrei para o Facebook em 2009, quando a empresa estava prestes a lançar seu primeiro data center em Prineville, Oregon. Naquela época, toda a equipe do Data Center consistia em menos de 30 membros da equipe e o Facebook ocupava duas pequenas pegadas de co-localização nos EUA. Eu entrei para ajudar a criar o programa de seleção de sites para data centers do Facebook. Hoje, nossa equipe compreende mais de 100 pessoas em vários locais em todo o mundo.
Avançando hoje, o Facebook agora é dono e opera um grande portfólio de data centers, abrangendo os EUA, Europa e Ásia. O programa de seleção de sites lançou com sucesso quinze centers de dados maciços e estamos comprometidos em alimentar esses data centers com energia 100% renovável. Em 2012, estabelecemos nossa primeira meta de 25% de energia limpa e renovável em nosso mix de suprimentos de eletricidade em 2015 para todos os data centers. Em 2017, superamos 50% de energia limpa e renovável para todas as operações do Facebook. Em 2018, estabelecemos nossa próxima meta agressiva – com o objetivo de atender 100% de energia limpa e renovável para todas as operações de crescimento do Facebook até o final de 2020.
Foi realmente emocionante estar na vanguarda desse crescimento e construir a equipe que desempenhou um papel crítico no crescimento da infraestrutura do Facebook. Nunca houve um momento de tédio nesta jornada incrível! O crescimento do Facebook tornou desafiador e divertido, e eu não acho que um dia tenha passado por onde eu não tenho aprendido. Eu amo o que faço, e tenho a sorte de trabalhar com uma equipe tão incrível e divertida. A cultura do Facebook capacita minha equipe a ter um impacto de longo alcance e juntos estamos tornando o mundo mais aberto e conectado. Um data center de cada vez.

A missão do Facebook é tornar o mundo mais aberto e conectado, qual o papel que sua equipe tem neste?
Lidera a estratégia de localização global do Facebook e os esforços de seleção de sites com base em vários critérios críticos de localização, incluindo nova energia renovável para apoiar os sites.
Gerencia os programas globais de conformidade ambiental do Facebook, desde a seleção de sites ao longo das operações, incluindo conformidade com ar e água.
Lidera os programas de energia global do Facebook, desde a seleção de sites ao longo das operações, otimizando o fornecimento de energia para 100% de energia renovável, garantindo responsabilidade e confiabilidade fiscais.
Lidera o planejamento estratégico, a habilitação e o monitoramento do roteiro global de data center.
Fornece suporte à ciência de dados para permitir decisões estratégicas e otimização de desempenho em todo o ciclo de vida do data center.
Lidera nosso trabalho de engajamento da comunidade em locais onde temos data centers.
Desenvolve e gerencia estratégias de mitigação de políticas e riscos para permitir a expansão global do Facebook’s Pessão de infraestrutura.
O Facebook está comprometido em ser uma força para o bem onde quer que trabalhemos, fornecendo empregos, cultivando a economia e apoiando programas que beneficiam as comunidades em que vivemos.
Nossa equipe de sustentabilidade’A missão é apoiar o Facebook’a capacidade de operar e crescer de maneira eficiente e responsável e capacitar as pessoas a construir comunidades sustentáveis.
Lidera a estratégia em toda a empresa para impulsionar a excelência operacional do projeto, construção e operação de nossos negócios. Priorizamos a eficiência, a conservação da água e a excelência na cadeia de suprimentos e estamos orgulhosos de dizer que nossas instalações estão entre os mais eficientes em termos de água e energia do mundo.
Estamos comprometidos em combater as mudanças climáticas e estabelecemos um alvo científico para reduzir nossas emissões em 75 % até 2020.

Os principais valores do Facebook são rápidos, concentram -se no impacto, criam valor social, sejam abertos, sejam ousados. Qual valor realmente ressoa com sua equipe?
Concentre -se no impacto. Nossa equipe é relativamente magra e, no entanto, temos a capacidade de fornecer muitas iniciativas de alto impacto para a empresa.
O que é algo que a maioria das pessoas não sabe sobre sua equipe?
Temos uma equipe muito diversificada composta por advogados, gerentes de políticas públicas, analistas financeiros, gerentes de programas, cientistas de dados, profissionais de energia, engenheiros e especialistas em processos de negócios.
Você pode compartilhar sobre ser líder feminina na indústria de tecnologia e a importância da diversidade no Facebook e tecnologia em geral?
Uma das razões pelas quais eu amo trabalhar no Facebook é o nosso compromisso com a diversidade. A diversidade não é uma atividade extracurricular no Facebook, mas algo que pretendemos implementar em todos os níveis da empresa. Embora nós, e a indústria de tecnologia como um todo, tenhamos mais trabalho a fazer aqui, reforçamos continuamente esse compromisso através de nossa cultura, nossos produtos e nossas prioridades de contratação.
Como mulher em tecnologia, sei em primeira mão a importância da diversidade para a nossa indústria e como diversas perspectivas geram melhores resultados. É extremamente importante que façamos tudo o que pudermos para melhorar a contratação de diversos candidatos e incentivar as mulheres a se juntarem aos setores que normalmente são dominados por homens. Encontrei minha carreira chamando na seleção de sites imobiliários, uma indústria tradicionalmente dominada por homens, e encontrei minha inspiração através das muitas mulheres talentosas que me inspiraram e me orientavam ao longo do caminho. Hoje, como líder de mulher em tecnologia, é meu dever e privilégio ser um mentor para as mulheres e fazer o possível para apoiar ativamente o crescimento e o avanço das mulheres nesta indústria.
Meu conselho para mulheres? Encontre suas paixões e siga -as, mesmo se você acabar em uma área onde você’reú normalmente a única mulher na sala. Seus pontos fortes se desenvolverão através de suas paixões e você’trabalhará mais em seu ofício. Sua carreira encontrará sua própria trajetória. Mais importante, permita -se algum espaço para falhar e volte se você tropeçar no caminho.
O Facebook tem seus próprios datacenters

Facebook’Os serviços são dependem de frotas de servidores em data centers em todo o mundo – todos os aplicativos em execução e entregando o desempenho que nossa necessidade de serviços. É por isso que precisamos garantir que o hardware do nosso servidor seja confiável e que possamos gerenciar falhas de hardware do servidor em nossa escala com o mínimo possível de interrupções em nossos serviços.
Os próprios componentes de hardware podem falhar por vários motivos, incluindo degradação do material (e.g., os componentes mecânicos de uma unidade de disco rígido giratório), um dispositivo sendo usado além do seu nível de resistência (e.g., Dispositivos flash nand), impactos ambientais (e.g., corrosão devido a umidade) e defeitos de fabricação.
Em geral, sempre esperamos algum grau de falha de hardware em nossos data centers, e é por isso que implementamos sistemas como nosso sistema de gerenciamento de cluster para minimizar as interrupções de serviço. Neste artigo nós’estar introduzindo quatro metodologias importantes que nos ajudam a manter um alto grau de disponibilidade de hardware. Construímos sistemas que podem detectar e remediar problemas . Monitoramos e remediamos eventos de hardware sem afetar adversamente o desempenho do aplicativo . Adotamos abordagens proativas para reparos de hardware e usamos a metodologia de previsão para remediações . E automatizamos a análise de causa raiz para falhas de hardware e sistema em escala para chegar ao fundo dos problemas rapidamente.
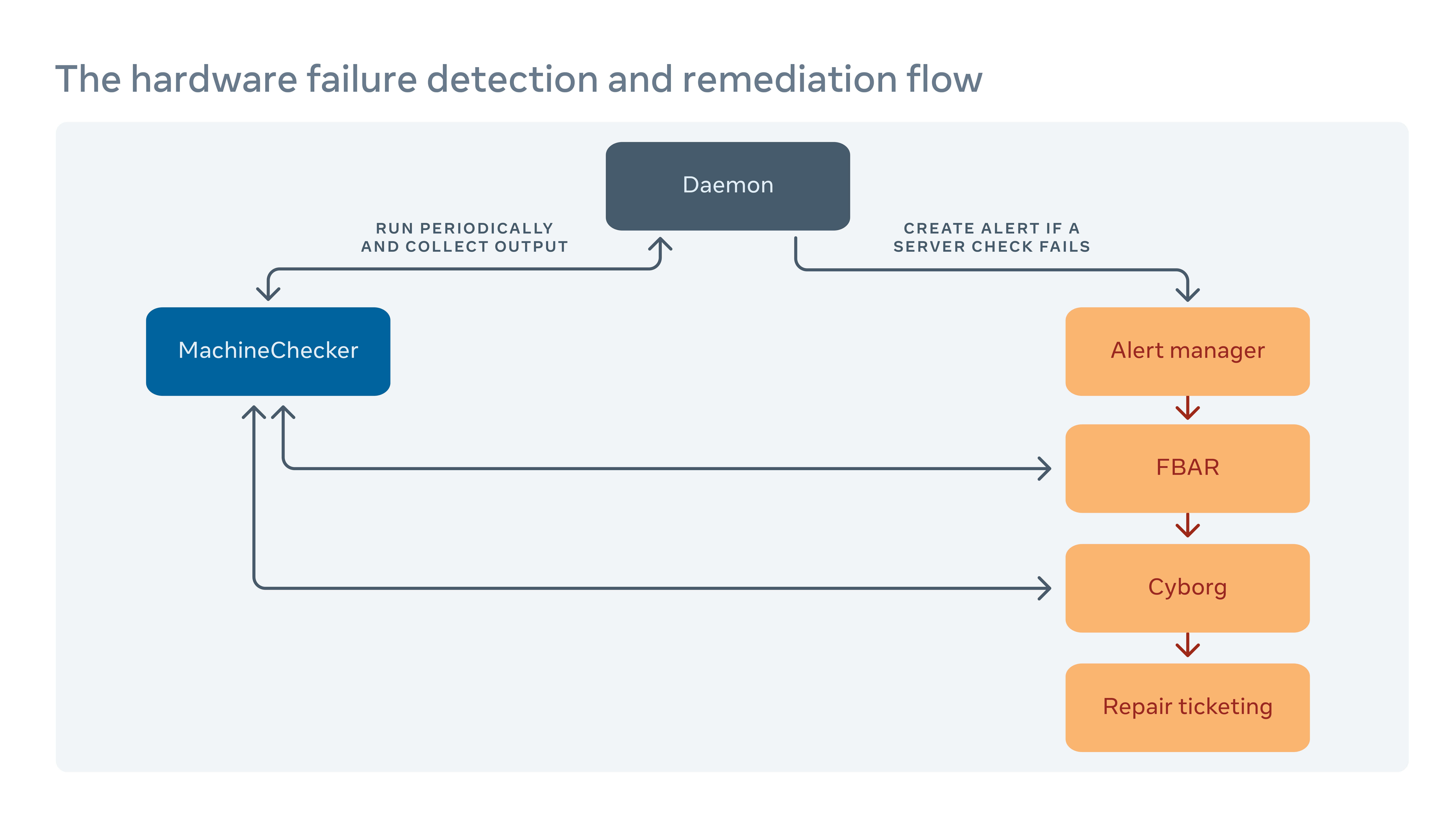
Como lidamos com a remediação de hardware
Executamos periodicamente uma ferramenta chamada MachineChecker em cada servidor para detectar falhas de hardware e conectividade. Uma vez que o MachineChecker cria um alerta em um sistema de manuseio de alerta centralizado, uma ferramenta chamada Facebook Remediação automática (FBAR) capta o alerta e executa remediações personalizáveis para corrigir o erro. Para garantir que lá’ainda é capacidade suficiente para o Facebook’S Serviços, também podemos definir limites de taxa para restringir quantos servidores estão sendo reparados a qualquer momento.
Se o FBAR puder’T trago um servidor de volta a um estado saudável, a falha é passada para uma ferramenta chamada Cyborg. O cyborg pode executar remediações de nível inferior, como atualizações de firmware ou kernel e reimaginar. Se o problema exigir reparo manual de um técnico, o sistema cria um ticket em nosso sistema de emissão de emissão de reparo.
Nós nos aprofundamos nesse processo em nosso artigo “Remediação de hardware em escala.”
Como minimizamos o impacto negativo do relatório de erros no desempenho do servidor
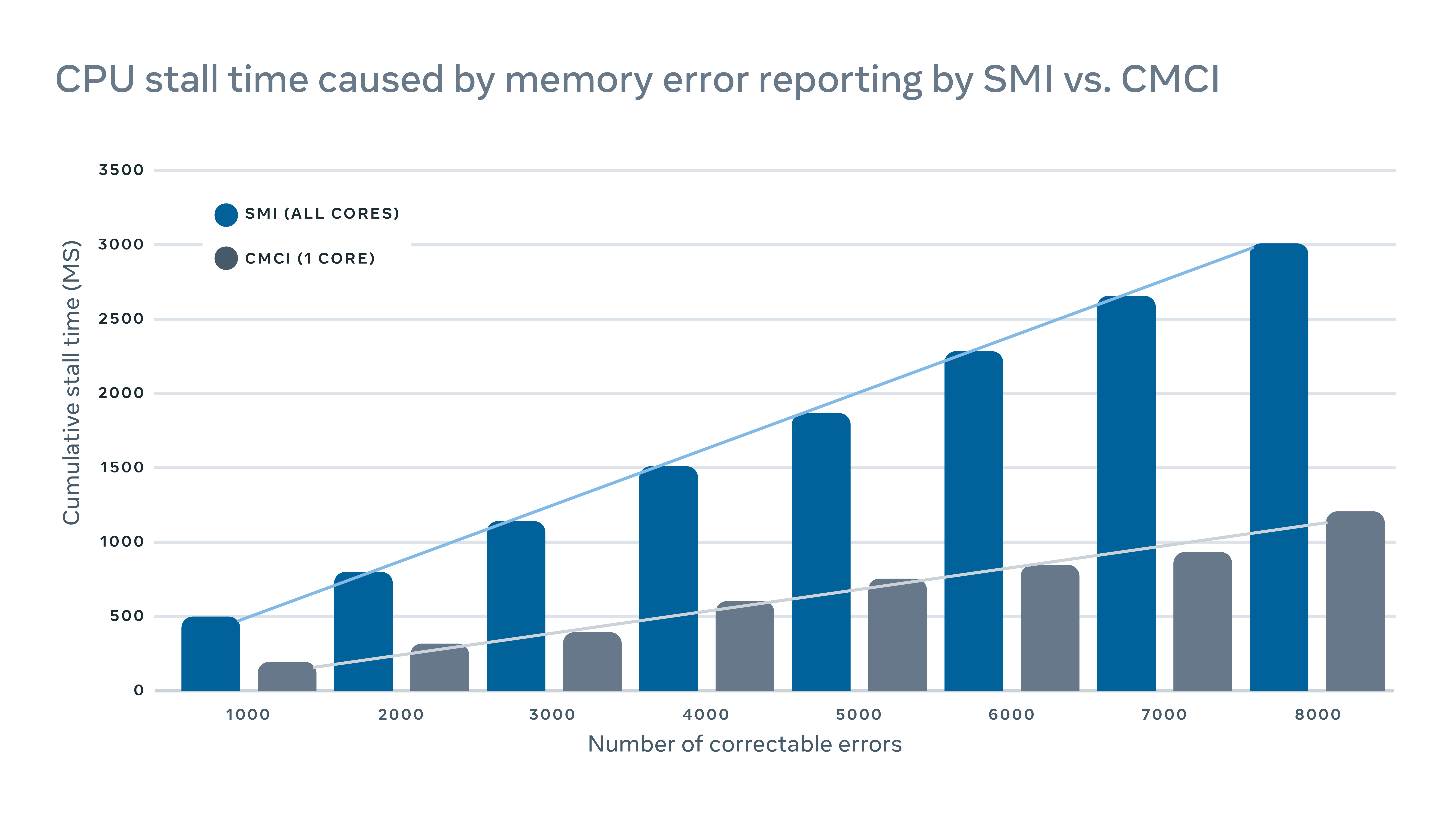
O MachineChecker detecta falhas de hardware, verificando vários logs do servidor para os relatórios de erro. Normalmente, quando ocorre um erro de hardware, ele será detectado pelo sistema (e.g., falhando em uma verificação de paridade), e um sinal de interrupção será enviado à CPU para manusear e registrar o erro.
Como esses sinais de interrupção são considerados sinais de alta prioridade, a CPU interromperá sua operação normal e dedicará sua atenção ao manuseio do erro. Mas isso tem um impacto negativo no servidor. Para registrar erros de memória corretos, por exemplo, uma interrupção tradicional de gerenciamento de sistema de interrupção (SMI) impediria todos os núcleos da CPU, enquanto a interrupção de verificação de máquina corrigível (CMCI) impedia apenas um dos núcleos da CPU, deixando o restante dos núcleos da CPU disponível para operação normal.
Embora as barracas da CPU normalmente duram apenas algumas centenas de milissegundos, elas ainda podem interromper os serviços sensíveis à latência. Em escala, isso significa que as interrupções em algumas máquinas podem ter um impacto adverso em cascata no desempenho do nível de serviço.
Para minimizar o impacto do desempenho causado pelos relatórios de erros, implementamos um mecanismo híbrido para relatórios de erros de memória que usam CMCI e SMI sem perder a precisão em termos do número de erros de memória corrigível.
Como aproveitamos o aprendizado de máquina para prever reparos
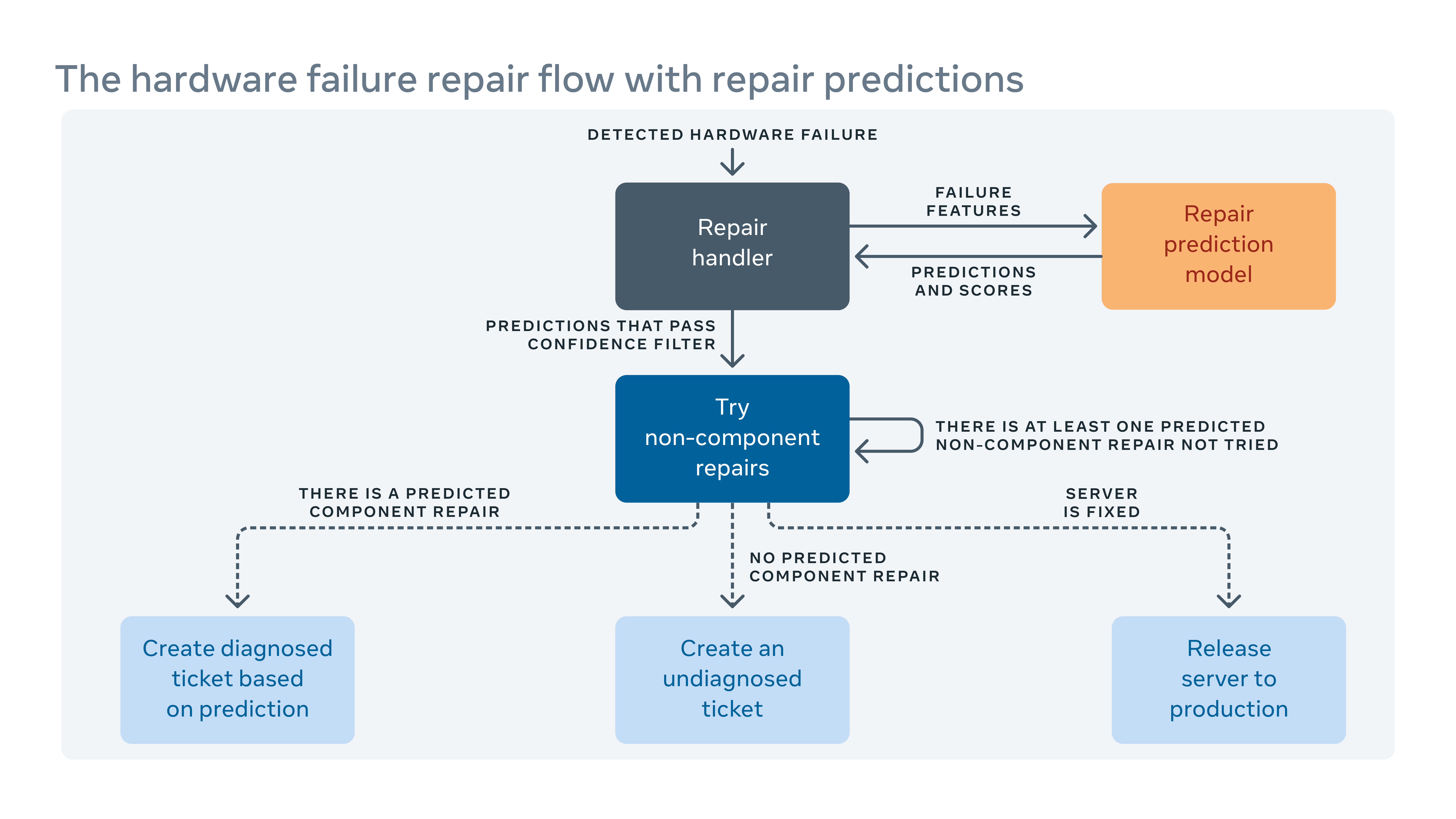
Como frequentemente introduzimos novas configurações de hardware e software em nossos data centers, também precisamos criar novas regras para o nosso sistema de remuneração automática.
Quando o sistema automatizado não pode corrigir uma falha de hardware, o problema é atribuído a um ticket para reparo manual. Novo hardware e software significam novos tipos de falhas em potencial que devem ser abordadas. Mas pode haver uma lacuna entre quando um novo hardware ou software é implementado e quando podemos incorporar novas regras de remediação. Durante essa lacuna, alguns bilhetes de reparo podem ser classificados como “não diagnosticado,” Significando que o sistema não tem’t sugeriu uma ação de reparo, ou “incorretamente diagnosticado,” significando que a ação de reparo sugerida não é’t eficaz. Isso significa mais tempo de mão -de -obra e sistema, enquanto os técnicos precisam diagnosticar o problema.
Para fechar a lacuna, construímos uma estrutura de aprendizado de máquina que aprende com a forma como as falhas foram corrigidas no passado e tenta prever quais reparos seriam necessários para os ingressos atuais de reparo não diagnosticados e diagnosticados. Com base no custo e nos benefícios das previsões incorretas e corretas, atribuímos um limite à confiança da previsão para cada ação de reparo e otimizamos a ordem das ações de reparo. Por exemplo, em alguns casos, preferimos experimentar uma reinicialização ou atualização de firmware primeiro porque esses tipos de reparos don’T requer qualquer reparo físico de hardware e reserve um tempo para terminar, para que o algoritmo deve recomendar esse tipo de ação primeiro. Claramente, o aprendizado de máquina nos permite não apenas prever como reparar um problema não diagnosticado ou diagnosticado, mas também priorizar os mais importantes.
Como nós’Análise de causa raiz automatizada no nível da frota
Além de logs de servidores que registram reinicializações, o kernel entra em pânico fora da memória, etc., Também existem logs de software e ferramentas em nosso sistema de produção. Mas a escala e a complexidade de tudo isso significam’é difícil examinar todos os troncos em conjunto para encontrar correlações entre eles.
Implementamos uma ferramenta escalável de análise de raízes-raízes (RCA) que classifica milhões de entradas de log (cada uma descrita por potencialmente centenas de colunas) para encontrar correlações fáceis de entender e acionáveis e acionáveis.
Com a pré-agregação de dados usando o SCUBA, um banco de dados de memória em tempo real, melhoramos significativamente a escalabilidade de um algoritmo de mineração de padrões tradicional, crescimento de FP, para encontrar correlações nesta estrutura da RCA. Também adicionamos um conjunto de filtros nas correlações relatadas para melhorar a interpretabilidade do resultado. Implantamos esse analisador amplamente no Facebook para a RCA na taxa de falha de componentes de hardware, reinicializações inesperadas de servidores e falhas de software.
Quem precisa de HP e Dell? O Facebook agora projeta todos os seus próprios servidores
O mais novo data center do Facebook não terá nenhum servidor OEM.
Jon Brodkin – 14 de fevereiro de 2013 22:35 UTC

Comentários do leitor
Quase dois anos atrás, o Facebook revelou o que chamou de Open Compute Project. A idéia era compartilhar designs de hardware de data center, como servidores, armazenamento e racks para que as empresas pudessem construir seu próprio equipamento, em vez de confiar nas opções estreitas fornecidas pelos fornecedores de hardware.
Enquanto qualquer um poderia se beneficiar, o Facebook liderou o caminho para implantar o hardware personalizado em seus próprios data centers. O projeto agora avançou até o ponto em que todos os novos servidores implantados pelo Facebook foram projetados pelo próprio Facebook ou projetados por outros para as especificações exigentes do Facebook. O equipamento personalizado hoje ocupa mais da metade do equipamento nos data centers do Facebook. Em seguida, o Facebook abrirá um data center de 290.000 pés quadrados na Suécia estocada inteiramente com servidores de seu próprio design, um primeiro para a empresa.
“É o primeiro em que teremos 100 % de servidores de computação aberta”, disse Frank Frankovsky, vice.
Como os data centers existentes do Facebook na Carolina do Norte e Oregon, o que está chegando online neste verão em Luleå, a Suécia terá dezenas de milhares de servidores. O Facebook também coloca seu equipamento no espaço do data center alugado para manter uma presença perto de usuários em todo o mundo, incluindo em 11 sites de colocação nos EUA. Vários fatores contribuem para a escolha dos locais: impostos, trabalho técnico disponível, fonte e custo de energia e o clima. O Facebook não usa o ar condicionado tradicional, em vez de confiar completamente no “ar externo e no sistema de refrigeração evaporativo exclusivo para manter nossos servidores simplesmente frios”, disse Frankovsky.
Economizando dinheiro retirando o que você não’T necessidade
Na escala do Facebook, é mais barato manter seus próprios data centers do que confiar nos provedores de serviços em nuvem, ele observou. Além disso, também é mais barato para o Facebook evitar fornecedores de servidores tradicionais.
Como o Google, o Facebook projeta seus próprios servidores e os criados pela ODMS (fabricantes originais de design) em Taiwan e China, em vez de OEMs (fabricantes de equipamentos originais) como HP ou Dell. Ao rolar o seu próprio, o Facebook elimina o que Frankovsky chama de “diferenciação gratuita”, recursos de hardware que tornam os servidores únicos, mas não beneficiam o Facebook.
Pode ser tão simples quanto a moldura de plástico em um servidor com um logotipo da marca, porque esse pedaço extra de material força os fãs a trabalharem mais. Frankovsky disse que um estudo mostrou um servidor OEM de tamanho 1U padrão “usado 28 watts de energia do ventilador para puxar o ar através da impedância causada por esse painel de plástico”, enquanto o servidor de computação aberta equivalente usou apenas três watts para esse fim.

O que mais o Facebook tira? Frankovsky disse que “muitas placas -mãe hoje vêm com muita gestão Goop. Esse é o termo técnico que eu gosto de usar para isso.”Este Goop pode ser o mecanismo de gerenciamento de ciclo de vida integrado da HP ou as ferramentas de gerenciamento de servidor remoto da Dell.
Esses recursos podem muito bem ser úteis para muitos clientes, principalmente se tiverem padronizado em um fornecedor. Mas, do tamanho do Facebook, não faz sentido confiar apenas em um fornecedor, porque “uma falha de design pode levar grande parte da sua frota ou porque uma falta de peças pode prejudicar sua capacidade de entregar o produto aos seus data centers.”
O Facebook tem suas próprias ferramentas de gerenciamento de data center, para que o material HP ou Dell faça é desnecessário. Um produto do fornecedor “vem com seu próprio conjunto de interfaces de usuário, conjunto de APIs e uma boa GUI para lhe dizer a rapidez com que os fãs estão girando e algumas coisas que, em geral, a maioria dos clientes implantando essas coisas em escala como diferenciação gratuita”, disse Frankovsky. “É diferente de uma maneira que não importa para mim. Essa instrumentação extra na placa -mãe, não apenas custa dinheiro para comprá -lo da perspectiva de um materiais, mas também causa complexidade nas operações.”
Um caminho para HP e Dell: adapte -se à computação aberta
Isso não significa que o Facebook está xingando HP e Dell para sempre. “A maior parte do nosso novo equipamento é construída por ODMs como Quanta”, disse a empresa em uma resposta por e-mail a uma de nossas perguntas de acompanhamento. “Fazemos várias fontes todo o nosso equipamento e, se um OEM puder construir para nossos padrões e trazê-lo dentro de 5 %, eles geralmente estão nessas discussões de várias fontes.”
HP e Dell começaram a criar designs em conformidade com as especificações de computação, e o Facebook disse que está testando um da HP para ver se pode fazer o corte. A empresa confirmou, no entanto, que seu novo data center na Suécia não incluirá servidores OEM quando abrir.
O Facebook diz que recebe 24 % de economia financeira de ter uma infraestrutura de menor custo e economiza 38 % nos custos operacionais em andamento como resultado da construção de suas próprias coisas. Os servidores personalizados do Facebook não executam cargas de trabalho diferentes do que qualquer outro servidor-eles apenas os executam com mais eficiência.
“Um servidor HP ou Dell, ou servidor de computação aberto, todos podem executar as mesmas cargas de trabalho”, disse Frankovsky. “É apenas uma questão de quanto trabalho você faz por watt por dólar.”
O Facebook não virtualiza seus servidores, porque seu software já consome todos os recursos de hardware, o que significa que a virtualização resultaria em uma penalidade de desempenho sem um ganho de eficiência.
A gigante da mídia social publicou os projetos e especificações de seus próprios servidores, placas -mãe e outros equipamentos. Por exemplo, a placa-mãe “Windmill” usa dois processadores Intel Xeon E5-2600, com até oito núcleos por CPU.
A folha de especificações do Facebook divide -a:
- 2 Processadores da série Intel® Xeon® E5-2600 (LGA2011) até 115W
- 2 Intel QuickPath Interconect (QPI) de largura completa (QPI) até 8 gt/s/direção
- Até 8 núcleos por CPU (até 16 threads com tecnologia de hiper-threading)
- Até 20 MB de cache de último nível
- Modo de processador único
- DDR3 Suporte direto de memória anexada na CPU0 e CPU1 com:
- Interface de memória registrada de 4 canais DDR3 nos processadores 0 e 1
- 2 slots DDR3 por canal por processador (total de 16 DIMMs na placa -mãe)
- Rdimm/lv-rdimm (1.5V/1.35V), LRDIMM e ECC UDIMM/LV-UDIMM (1.5V/1.35V)
- DIMMS solteiros, duplos e quadrados
- Velas DDR3 de 800/1066/1333/1600 MHz
- Até o máximo de 512 GB de memória com 32 GB RDimm DIMMS
E agora um diagrama da placa -mãe:
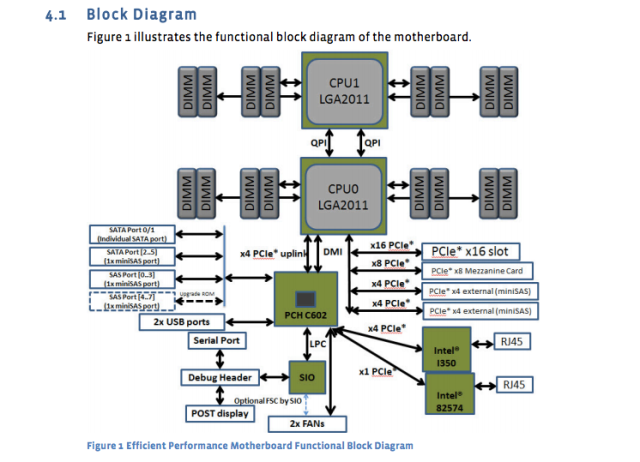
Essas especificações da placa -mãe foram publicadas há quase um ano, mas ainda são o padrão. O recém -projetado servidor de banco de dados “Dragonstone” e Web Server “Winterfell” depende da placa -mãe do moinho de vento, embora as CPUs Intel mais recentes possam atingir a produção no Facebook no final deste ano.

Os designs de servidores do Facebook são adaptados a diferentes tarefas. Como o Timothy Pickett Morgan do registro relatou no mês passado, certas funções de banco de dados no Facebook exigem fontes de alimentação redundantes, enquanto outras tarefas podem ser tratadas por servidores com vários nós de computação compartilhando uma única fonte de alimentação.
Os data centers usam uma mistura de armazenamento flash e discos de fiação tradicionais, com flash servir a funcionalidade do Facebook exigindo as velocidades mais rápidas disponíveis. Servidores de banco de dados usam todo o flash. Os servidores da Web normalmente têm CPUs muito rápidas, com quantidades relativamente baixas de armazenamento e RAM. 16 GB é uma quantidade típica de RAM, disse Frankovsky. Chips Intel e AMD estão presentes no Facebook Gear.
E o Facebook está sobrecarregado com muito “armazenamento a frio”, coisas escritas uma vez e raramente acessadas novamente. Mesmo lá, Frankovsky quer usar cada vez mais flash devido à taxa de falha dos discos de giro. Com dezenas de milhares de dispositivos em operação, “não queremos que os técnicos corram por aí substituindo os discos rígidos”, disse ele.
O flash da classe de data center é tipicamente muito mais caro do que os discos giratórios, mas Frankovsky diz que pode haver uma maneira de fazer valer a pena. “Se você usar a classe de Nand [flash] em unidades de polegar, que normalmente é considerado varredura ou sucata de NAND, e você usa um tipo de algoritmo de controlador muito legal para caracterizar quais células são boas e quais células não são, você pode potencialmente construir uma solução de armazenamento a frio de alto desempenho a um custo muito baixo”, disse ele, disse ele, disse ele, ele.
Tomando a flexibilidade do data center ao extremo
Frankovsky quer designs tão flexíveis que componentes individuais possam ser trocados em resposta à mudança de demanda. Um esforço ao longo dessa linha é a nova especificação de “abraço de grupo” do Facebook para placas -mãe, que pode acomodar processadores de vários fornecedores. AMD e Intel, assim como os fornecedores de chips de braço aplicados Micro e Calxeda, já prometeram suportar essas placas com novos produtos SoC (System on Chip).
Essa foi uma das várias notícias que saíram da cúpula de computação aberta do mês passado em Santa Clara, CA. No total, os anúncios apontam para um futuro em que os clientes podem “atualizar através de várias gerações de processadores sem precisar substituir as placas-mãe ou a rede interna”, observou Frankovsky em uma postagem no blog.
Calxeda criou uma placa de servidor baseada em braço que pode deslizar para o sistema de armazenamento Open Vault do Facebook, codinome “Knox.”” Ele transforma o dispositivo de armazenamento em um servidor de armazenamento e elimina a necessidade de um servidor separado para controlar o disco rígido “, disse Frankovsky. (O Facebook não usa servidores ARM hoje porque requer suporte de 64 bits, mas Frankovsky diz que “as coisas estão ficando interessantes” na tecnologia ARM “.)
A Intel também contribuiu com os designs para uma próxima tecnologia de silício Photonics que permitirá interconexões de 100 Gbps, 10 vezes mais rápido que as conexões Ethernet que o Facebook usa em seus data centers hoje. Com a baixa latência ativada por esse tipo de velocidade, os clientes podem separar as CPUs, DRAM e armazenamento em diferentes partes do rack e apenas adicionar ou subtrair componentes em vez de servidores inteiros quando necessário, Frankovsky disse. Nesse cenário, vários hosts podem compartilhar um sistema de flash, melhorando a eficiência.
Apesar de todos esses designs personalizados vindos de fora do mundo OEM, HP e Dell não estão sendo completamente deixados para trás. Eles se adaptaram para tentar capturar alguns clientes que desejam a flexibilidade de designs de computação aberta. Um executivo da Dell entregou uma das palestras na cúpula de computação aberta deste ano, e a HP e a Dell anunciaram no ano passado “servidor de folha limpa e designs de armazenamento” que são compatíveis com a especificação “Open Rack” do projeto aberto do projeto.
Além de ser bom para o Facebook, Frankovsky espera que o Open Compute beneficie os clientes do servidor em geral. Fidelity e Goldman Sachs estão entre os que usam designs personalizados sintonizados em suas cargas de trabalho como resultado de computação aberta. Os clientes menores também podem se beneficiar, mesmo que aluguem espaço de um data center onde não podem alterar o design do servidor ou do rack, ele disse. Eles poderiam “pegar os blocos de construção [de computação aberta] e reestruturá -los em projetos físicos que se encaixam nos slots do servidor”, disse Frankovsky.
“O setor está mudando e mudando de um jeito bom, a favor dos consumidores, por causa da computação aberta”, disse ele.

