
Apresentando Apache Kafka no Netflix Studio e Finance World
Resumo:
Na Netflix, a maioria dos aplicativos usa a biblioteca de clientes Java para produzir dados para o pipeline Keystone. O oleoduto consiste em clusters de Kafka de frente, responsáveis pela coleta e buffer de dados e clusters de kafka do consumidor, contendo tópicos para consumidores em tempo real. A Netflix opera um total de 36 clusters de kafka que lidando com mais de 700 bilhões de mensagens diariamente. Para alcançar a entrega sem perdas, o oleoduto permite uma taxa de perda de dados inferior a 0.01%. Os produtores e corretores estão configurados para garantir a disponibilidade e boa experiência do usuário.
Pontos chave:
- Os aplicativos da Netflix usam a biblioteca de clientes Java para produzir dados para Keystone Pipeline
- Vários produtores de kafka existem em cada instância do aplicativo
- Os clusters kafka de frente
- Os clusters de consumidores Kafka contêm tópicos para consumidores em tempo real
- A Netflix opera 36 clusters kafka com mais de 700 bilhões de mensagens diariamente
- A taxa de perda de dados é menor que 0.01%
- Produtores e corretores estão configurados para garantir a disponibilidade
- Os produtores usam configuração dinâmica para roteamento de tópicos e isolamento de afundar
- Aplicativos que não são de Java podem enviar eventos para pontos de extremidade Keystone REST
- A ordem das mensagens é estabelecida na camada de processamento ou roteamento em lote
Questões:
- Como os aplicativos da Netflix produzem dados para Keystone Pipeline?
- Quais são os papéis de clusters de Kafka em frente?
- Que tipos de clusters kafka existem no oleoduto Keystone?
- Quantos clusters Kafka Netflix opera?
- Qual é a taxa média de ingestão de dados para Netflix?
- Qual é a versão atual do kafka usada pelo Netflix?
- Como a Netflix atinge a entrega sem perdas no pipeline?
- Qual é a configuração para produtores e corretores para garantir a disponibilidade?
- Como a ordem das mensagens é mantida?
- Por que os aplicativos de clientes não consomem diretamente de clusters de Kafka de frente?
- Que desafios surgem ao executar Kafka na nuvem?
- Como a replicação afeta a disponibilidade de Kafka?
- O que a Netflix fez para abordar incidentes e manter a estabilidade do cluster?
- Qual é a estratégia de implantação da Netflix para Clusters Kafka?
A maioria dos aplicativos da Netflix usa a biblioteca de clientes Java para produzir dados para o kerapo de Keystone. Cada instância do aplicativo tem vários produtores de kafka.
Os clusters Kafka de frente. Eles servem como um portal para injeção de mensagem.
O oleoduto Keystone consiste em aglomerados de Kafka e clusters de consumidores kafka.
A Netflix opera 36 clusters kafka.
Netflix ingere mais de 700 bilhões de mensagens diariamente.
A Netflix está transitando da versão Kafka 0.8.2.1 a 0.9.0.1.
Contabilizando o enorme volume de dados, a Netflix trabalhou com equipes para aceitar uma quantidade aceitável de perda de dados, resultando em uma taxa diária de perda de dados inferior a 0.01%.
Os produtores e corretores estão configurados com “acks = 1”, “bloco.sobre.amortecedor.completo = falso “e” impuro.líder.eleição.enable = true “.
Os produtores não usam mensagens de chave e a ordem das mensagens é restabelecida na camada de processamento em lote ou na camada de roteamento.
Os aplicativos do cliente não têm permissão para consumir diretamente de clusters de Kafka para garantir carga e estabilidade previsíveis.
Executar Kafka na nuvem apresenta desafios, como um ciclo de vida imprevisível de instância, problemas de rede transitórios e outliers, causando problemas de desempenho.
A replicação melhora a disponibilidade, mas um corretor externo pode causar efeitos em cascata e queda de mensagens devido ao atraso de replicação e exaustão de buffer.
A Netflix reduziu o estado e a complexidade, implementou a detecção externa e desenvolveu medidas para se recuperar rapidamente de incidentes.
A Netflix favorece vários pequenos aglomerados de kafka sobre um cluster gigante para reduzir as dependências e melhorar a estabilidade.
Kafka dentro do oleoduto Keystone
Temos dois conjuntos de clusters Kafka no Keystone Pipeline: Fronting Kafka e Consumer Kafka. Os clusters de Kafka em frente são responsáveis por receber as mensagens dos produtores que são praticamente todas as instâncias de aplicativos na Netflix. Seus papéis são coleta de dados e buffer para sistemas a jusante. Os clusters de kafka do consumidor contêm um subconjunto de tópicos roteados pela Samza para consumidores em tempo real.
Atualmente, operamos 36 clusters de Kafka que consistem em mais de 4.000 instâncias de corretores para Kafka e o consumidor Kafka. Mais de 700 bilhões de mensagens são ingeridas em um dia médio. Atualmente, estamos fazendo a transição da versão Kafka 0.8.2.1 a 0.9.0.1.
Princípios de design
Dada a arquitetura Kafka atual e nosso enorme volume de dados, para obter entrega sem perdas para o nosso pipeline de dados é proibitivo no AWS EC2. Contabilizando isso, nós’Trabalhou com equipes que dependem de nossa infraestrutura para chegar a uma quantidade aceitável de perda de dados, enquanto o custo de equilíbrio. Nós’Consegui uma taxa diária de perda de dados inferior a 0.01%. As métricas são coletadas para mensagens descartadas para que possamos agir se necessário.
O oleoduto Keystone produz mensagens de forma assíncrona sem bloquear aplicações. Caso uma mensagem não possa ser entregue após tentativas, ela será descartada pelo produtor para garantir a disponibilidade do aplicativo e a boa experiência do usuário. É por isso que escolhemos a seguinte configuração para nosso produtor e corretor:
- acks = 1
- bloquear.sobre.amortecedor.completo = false
- imundo.líder.eleição.Ativar = true
A maioria dos aplicativos na Netflix usa nossa biblioteca de clientes Java para produzir para Keystone Pipeline. Em cada instância dessas aplicações, existem vários produtores de Kafka, com cada um produzindo para um cluster de Kafka de frente para o isolamento do nível de pia. Os produtores têm roteamento de tópicos flexíveis e configuração de afundamento que são acionados por configuração dinâmica que podem ser alterados em tempo de execução sem precisar reiniciar o processo de aplicação. Isso torna possível para coisas como redirecionar o tráfego e migrar tópicos em clusters Kafka. Para aplicativos que não são de Java, eles podem optar por enviar eventos para pontos de extremidade Keystone Rest que transmitem mensagens para clusters de Kafka em frente.
Para maior flexibilidade, os produtores não usam mensagens de chave. A ordem aproximada de mensagens é restabelecida na camada de processamento em lote (Hive / Elasticsearch) ou camada de roteamento para streaming de consumidores.
Colocamos a estabilidade de nossos aglomerados de Kafka em frente, porque eles são o gateway para injeção de mensagem. Portanto, não permitimos que os aplicativos do cliente consumam diretamente deles para garantir que eles tenham carga previsível.
Desafios de correr Kafka na nuvem
Kafka foi desenvolvido com o Data Center como alvo de implantação no LinkedIn. Fizemos esforços notáveis para fazer Kafka funcionar melhor na nuvem.
Na nuvem, as instâncias têm um ciclo de vida imprevisível e podem ser encerradas a qualquer momento devido a problemas de hardware. Os problemas de rede transitórios são esperados. Esses não são problemas para serviços sem estado, mas representam um grande desafio para um serviço com estado que exige o Zookeeper e um único controlador para coordenação.
A maioria de nossos problemas começa com corretores outlier. Um outlier pode ser causado por carga de trabalho desigual, problemas de hardware ou seu ambiente específico, por exemplo, vizinhos barulhentos devido à multi-literidade. Um corretor externo pode ter respostas lentas a solicitações ou tempo limite de TCP/retransmissões frequentes. Os produtores que enviam eventos a um corretor terão uma boa chance de esgotar seus amortecedores locais enquanto aguardam as respostas, após o que a queda da mensagem se torna uma certeza. O outro fator que contribui para a exaustão de buffer é que Kafka 0.8.2 Produtor não’t Suporte a tempo limite para mensagens esperando em buffer.
Kafka’A replicação da s melhora a disponibilidade. No entanto, a replicação leva a interdependências entre os corretores, onde um outlier pode causar efeito em cascata. Se um estranho diminuir a replicação, o atraso da replicação pode se acumular e, eventualmente, fazer com que os líderes da partição leiam do disco para servir as solicitações de replicação. Isso diminui os corretores afetados e, eventualmente.
Durante nossos primeiros dias de operação de Kafka, experimentamos um incidente em que os produtores estavam lançando uma quantidade significativa de mensagens para um cluster de Kafka com centenas de instâncias devido a um problema de Zookeeper, enquanto havia pouco que poderíamos fazer. Questões de depuração como essa em uma pequena janela de tempo com centenas de corretores simplesmente não é realista.
Após o incidente, foram feitos esforços para reduzir o estado e a complexidade dos nossos aglomerados Kafka, detectar outliers e encontrar uma maneira de começar rapidamente com um estado limpo quando ocorre um incidente.
Estratégia de implantação de Kafka
A seguir, são apresentadas as principais estratégias que usamos para implantar clusters Kafka:
- Favorecer vários aglomerados Kafka em oposição a um cluster gigante. Isso reduz as dependências e melhora a estabilidade.
- Implementar mecanismos de detecção externa para identificar e lidar com corretores problemáticos.
- Desenvolver medidas para se recuperar rapidamente de incidentes e começar com um estado limpo.
Apresentando Apache Kafka no Netflix Studio e Finance World
A maioria dos aplicativos na Netflix usa nossa biblioteca de clientes Java para produzir para Keystone Pipeline. Em cada instância dessas aplicações, existem vários produtores de Kafka, com cada um produzindo para um cluster de Kafka de frente para o isolamento do nível de pia. Os produtores têm roteamento de tópicos flexíveis e configuração de afundamento que são acionados por configuração dinâmica que podem ser alterados em tempo de execução sem precisar reiniciar o processo de aplicação. Isso torna possível para coisas como redirecionar o tráfego e migrar tópicos em clusters Kafka. Para aplicativos que não são de Java, eles podem optar por enviar eventos para pontos de extremidade Keystone Rest que transmitem mensagens para clusters de Kafka em frente.
Kafka dentro do oleoduto Keystone
Temos dois conjuntos de clusters Kafka no Keystone Pipeline: Fronting Kafka e Consumer Kafka. Os clusters de Kafka em frente são responsáveis por receber as mensagens dos produtores que são praticamente todas as instâncias de aplicativos na Netflix. Seus papéis são coleta de dados e buffer para sistemas a jusante. Os clusters de kafka do consumidor contêm um subconjunto de tópicos roteados pela Samza para consumidores em tempo real.
Atualmente, operamos 36 clusters de Kafka que consistem em mais de 4.000 instâncias de corretores para Kafka e o consumidor Kafka. Mais de 700 bilhões de mensagens são ingeridas em um dia médio. Atualmente, estamos fazendo a transição da versão Kafka 0.8.2.1 a 0.9.0.1.
Princípios de design
Dada a arquitetura Kafka atual e nosso enorme volume de dados, para obter entrega sem perdas para o nosso pipeline de dados é proibitivo no AWS EC2. Contabilizando isso, nós’Trabalhou com equipes que dependem de nossa infraestrutura para chegar a uma quantidade aceitável de perda de dados, enquanto o custo de equilíbrio. Nós’Consegui uma taxa diária de perda de dados inferior a 0.01%. As métricas são coletadas para mensagens descartadas para que possamos agir se necessário.
O oleoduto Keystone produz mensagens de forma assíncrona sem bloquear aplicações. Caso uma mensagem não possa ser entregue após tentativas, ela será descartada pelo produtor para garantir a disponibilidade do aplicativo e a boa experiência do usuário. É por isso que escolhemos a seguinte configuração para nosso produtor e corretor:
- acks = 1
- bloquear.sobre.amortecedor.completo = false
- imundo.líder.eleição.Ativar = true
A maioria dos aplicativos na Netflix usa nossa biblioteca de clientes Java para produzir para Keystone Pipeline. Em cada instância dessas aplicações, existem vários produtores de Kafka, com cada um produzindo para um cluster de Kafka de frente para o isolamento do nível de pia. Os produtores têm roteamento de tópicos flexíveis e configuração de afundamento que são acionados por configuração dinâmica que podem ser alterados em tempo de execução sem precisar reiniciar o processo de aplicação. Isso torna possível para coisas como redirecionar o tráfego e migrar tópicos em clusters Kafka. Para aplicativos que não são de Java, eles podem optar por enviar eventos para pontos de extremidade Keystone Rest que transmitem mensagens para clusters de Kafka em frente.
Para maior flexibilidade, os produtores não usam mensagens de chave. A ordem aproximada de mensagens é restabelecida na camada de processamento em lote (Hive / Elasticsearch) ou camada de roteamento para streaming de consumidores.
Colocamos a estabilidade de nossos aglomerados de Kafka em frente, porque eles são o gateway para injeção de mensagem. Portanto, não permitimos que os aplicativos do cliente consumam diretamente deles para garantir que eles tenham carga previsível.
Desafios de correr Kafka na nuvem
Kafka foi desenvolvido com o Data Center como alvo de implantação no LinkedIn. Fizemos esforços notáveis para fazer Kafka funcionar melhor na nuvem.
Na nuvem, as instâncias têm um ciclo de vida imprevisível e podem ser encerradas a qualquer momento devido a problemas de hardware. Os problemas de rede transitórios são esperados. Esses não são problemas para serviços sem estado, mas representam um grande desafio para um serviço com estado que exige o Zookeeper e um único controlador para coordenação.
A maioria de nossos problemas começa com corretores outlier. Um outlier pode ser causado por carga de trabalho desigual, problemas de hardware ou seu ambiente específico, por exemplo, vizinhos barulhentos devido à multi-literidade. Um corretor externo pode ter respostas lentas a solicitações ou tempo limite de TCP/retransmissões frequentes. Os produtores que enviam eventos a um corretor terão uma boa chance de esgotar seus amortecedores locais enquanto aguardam as respostas, após o que a queda da mensagem se torna uma certeza. O outro fator que contribui para a exaustão de buffer é que Kafka 0.8.2 Produtor não’t Suporte a tempo limite para mensagens esperando em buffer.
Kafka’A replicação da s melhora a disponibilidade. No entanto, a replicação leva a interdependências entre os corretores, onde um outlier pode causar efeito em cascata. Se um estranho diminuir a replicação, o atraso da replicação pode se acumular e, eventualmente, fazer com que os líderes da partição leiam do disco para servir as solicitações de replicação. Isso diminui os corretores afetados e, eventualmente.
Durante nossos primeiros dias de operação de Kafka, experimentamos um incidente em que os produtores estavam lançando uma quantidade significativa de mensagens para um cluster de Kafka com centenas de instâncias devido a um problema de Zookeeper, enquanto havia pouco que poderíamos fazer. Questões de depuração como essa em uma pequena janela de tempo com centenas de corretores simplesmente não é realista.
Após o incidente, foram feitos esforços para reduzir o estado e a complexidade dos nossos aglomerados Kafka, detectar outliers e encontrar uma maneira de começar rapidamente com um estado limpo quando ocorre um incidente.
Estratégia de implantação de Kafka
A seguir, são apresentadas as principais estratégias que usamos para implantar clusters Kafka
- Favorecer vários aglomerados Kafka em oposição a um cluster gigante. Isso reduz a complexidade operacional para cada cluster. Nosso maior cluster tem menos de 200 corretores.
- Limitar o número de partições em cada cluster. Cada cluster tem menos de 10.000 partições. Isso melhora a disponibilidade e reduz a latência para solicitações/respostas que estão vinculadas ao número de partições.
- Lute para a distribuição uniforme de réplicas para cada tópico. Até a carga de trabalho é mais fácil para planejar a capacidade e detecção de outliers.
- Use cluster de Zookeeper dedicado para cada cluster Kafka para reduzir o impacto dos problemas do Zookeeper.
A tabela a seguir mostra nossas configurações de implantação.
Failover de Kafka
Automatizamos um processo em que podemos failover tráfego de produtor e consumidor (roteador) para um novo cluster Kafka quando o cluster primário está com problemas. Para cada cluster de Kafka em frente, há um cluster de espera frio com a configuração de lançamento desejada, mas a capacidade inicial mínima. Para garantir um estado limpo para começar, o cluster de failover não tem tópicos criados e não compartilha o cluster do Zookeeper com o cluster Kafka primário. O cluster de failover também foi projetado para ter o fator de replicação 1, para que fique livre de qualquer problema de replicação que o cluster original possa ter.
Quando o failover acontece, as seguintes medidas são tomadas para desviar o produtor e o tráfego do consumidor:
- Redimensione o cluster de failover para o tamanho desejado.
- Crie tópicos e inicie os trabalhos de roteamento para o cluster de failover em paralelo.
- (Opcionalmente) Aguarde que os líderes de partições sejam estabelecidos pelo controlador para minimizar a queda da mensagem inicial ao produzir para ela.
- Altere dinamicamente a configuração do produtor para mudar de tráfego do produtor para o cluster de failover.
O cenário de failover pode ser retratado no gráfico a seguir:
Com a automação completa do processo, podemos fazer failover em menos de 5 minutos. Depois que o failover tiver concluído com sucesso, podemos depurar os problemas com o cluster original usando logs e métricas. Também é possível destruir completamente o cluster e reconstruir com novas imagens antes de mudarmos o tráfego. De fato, geralmente usamos a estratégia de failover para desviar o tráfego enquanto fazemos manutenção offline. É assim que estamos atualizando nossos clusters kafka para a nova versão Kafka sem ter que fazer a atualização rolante ou definir a versão do protocolo de comunicação entre corretores.
Desenvolvimento para Kafka
Desenvolvemos muitas ferramentas úteis para Kafka. Aqui estão alguns dos destaques:
Particionante Produtor Sticky
Este é um particionador personalizado especial que desenvolvemos para nossa biblioteca de produtores Java. Como o nome sugere, ele se apega a uma certa partição para produzir por uma quantidade configurável de tempo antes de escolher aleatoriamente a próxima partição. Descobrimos que o uso do Partiote Sticky junto com a perspectiva ajuda a melhorar o lote de mensagens e reduzir a carga para o corretor. Aqui está a tabela para mostrar o efeito do Particionário Sticky:
Atribuição de réplica ciente do rack
Todos os nossos clusters Kafka estendem em três zonas de disponibilidade da AWS. Uma zona de disponibilidade da AWS é conceitualmente um rack. Para garantir a disponibilidade no caso de uma zona diminuir, desenvolvemos a atribuição de réplica ciente do rack (zona) para que as réplicas para o mesmo tópico sejam atribuídas a diferentes zonas. Isso não apenas ajuda a reduzir o risco de interrupção da zona, mas também melhora nossa disponibilidade quando vários corretores co-localizados no mesmo host físico são encerrados devido a problemas do host. Nesse caso, temos melhor tolerância a falhas do que kafka’s n – 1 onde n é o fator de replicação.
O trabalho é contribuído para a comunidade Kafka no KIP-36 e o Apache Kafka Github Pull Solicy #132.
Visualizador de metadados kafka
Kafka’s Metadados é armazenado em Zookeeper. No entanto, a vista da árvore fornecida pelo expositor é difícil de navegar e é demorado encontrar e correlacionar informações.
Criamos nossa própria interface para visualizar os metadados. Ele fornece vistas tabulares e tabulares e usa esquemas de cores ricos para indicar o estado do ISR. Os principais recursos são os seguintes:
- Guia individual para visualizações para corretores, tópicos e clusters
- A maioria das informações é classificável e pesquisável
- Procurando tópicos em clusters
- Mapeamento direto do ID do corretor para a AWS Instância ID
- Correlação de corretores pelo relacionamento de seguidor de líder
A seguir, são apresentadas as capturas de tela da interface do usuário:
Monitoramento
Criamos um serviço de monitoramento dedicado para Kafka. É responsável pelo rastreamento:
- Status do corretor (especificamente, se estiver offline do Zookeeper)
- Corretor’S Capacidade de receber mensagens de produtores e entregar mensagens aos consumidores. O serviço de monitoramento atua como produtor e consumidor para mensagens contínuas de batimentos cardíacos e mede a latência dessas mensagens.
- Para os consumidores antigos baseados em Zookeeper, ele monitora a contagem de partições para o grupo de consumidores para garantir que cada partição seja consumida.
- Para os roteadores Samza Keystone, ele monitora as compensações postadas em verificação e se compara ao corretor’S Offsets de log para garantir que eles não estejam presos e não tenham atraso significativo.
Além disso, temos painéis extensos para monitorar o fluxo de tráfego até um nível de tópico e a maioria do corretor’s Métricas.
Plano futuro
Atualmente, estamos em processo de migração para Kafka 0.9, que possui alguns recursos que queremos usar, incluindo novas APIs de consumidores, tempo limite da mensagem do produtor e cotas. Também moveremos nossos clusters Kafka para a AWS VPC e acreditamos que sua rede aprimorada (em comparação com o clássico EC2) nos dará uma vantagem para melhorar a disponibilidade e a utilização de recursos.
Vamos apresentar um SLA em camadas para tópicos. Para tópicos que podem aceitar pequenas perdas, estamos pensando em usar uma réplica. Sem replicação, não apenas economizamos enormes na largura de banda, mas também minimizamos as mudanças de estado que devem depender do controlador. Este é outro passo para tornar Kafka menos com estado em um ambiente que favorece os serviços sem estado. A desvantagem é a potencial perda de mensagem quando um corretor desaparece. No entanto, aproveitando o tempo limite da mensagem do produtor em 0.9 Volume de liberação e possivelmente AWS EBS, podemos mitigar a perda.
Fique atento aos futuros blogs Keystone em nossa infraestrutura de roteamento, gerenciamento de contêineres, processamento de fluxos e muito mais!
Apresentando Apache Kafka no Netflix Studio e Finance World
A Netflix gastou cerca de US $ 15 bilhões para produzir conteúdo original de classe mundial em 2019. Quando as apostas são tão altas, é fundamental permitir que nossos negócios com insights críticos que ajudam a planejar, determinar os gastos e explicar todo o conteúdo da Netflix. Esses insights podem incluir:
- Quanto devemos gastar no próximo ano em filmes e séries internacionais?
- Estamos tendendo a repassar nosso orçamento de produção e alguém precisa intervir para manter as coisas no caminho certo?
- Como programamos um catálogo anos de antecedência com dados, intuição e análise para ajudar a criar a melhor slate possível?
- Como produzimos finanças para conteúdo em todo o mundo e relatamos Wall Street?
Semelhante a como os VCs se sintonizam rigorosamente nos olhos de bons investimentos, a equipe de engenharia de financiamento de conteúdo’A Carta é ajudar a Netflix a investir, rastrear e aprender com nossas ações, para que façamos continuamente melhores investimentos no futuro.
Abraçar eventos
Do ponto de vista da engenharia, todo aplicativo financeiro é modelado e implementado como um microsserviço. A Netflix abrange a governança distribuída e incentiva uma abordagem orientada por microsserviços para os aplicativos, o que ajuda a alcançar o equilíbrio certo entre abstração de dados e velocidade, enquanto a empresa escala. Em um mundo simples, os serviços podem interagir através do HTTP muito bem, mas, à medida que escalamos, eles evoluem para um gráfico complexo de interações síncronas baseadas em solicitação que podem levar a um cérebro/estado dividido e a disponibilidade de interrupções.
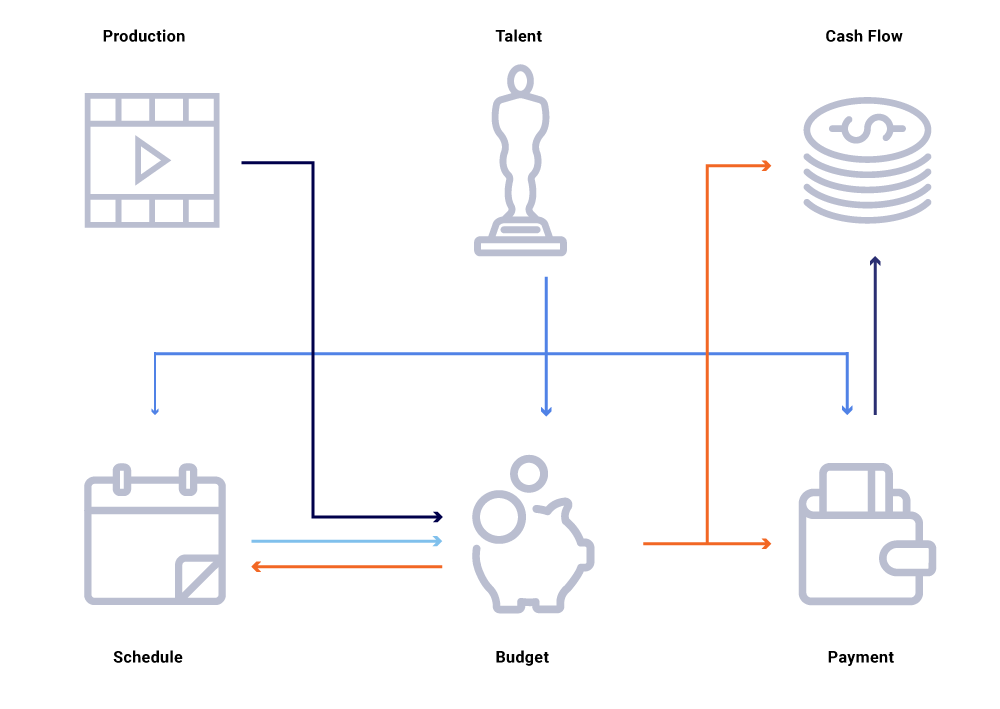
Considere no gráfico acima de entidades relacionadas, uma mudança na data de produção de um show. Isso afeta nossa lousa de programação, que por sua vez influencia projetos de fluxo de caixa, pagamentos de talentos, orçamentos para o ano, etc. Muitas vezes, em uma arquitetura de microsserviço, alguma porcentagem de falha é aceitável. No entanto, uma falha em qualquer um dos microsserviços exige a engenharia de financiamento de conteúdo levaria a uma infinidade de cálculos fora de sincronia e poderia resultar em dados desativados por milhões de dólares. Isso também levaria a problemas de disponibilidade à medida que o gráfico de chamadas se estende e causaria pontos cegos enquanto tentava rastrear e responder efetivamente a perguntas comerciais, como: por que as projeções de fluxo de caixa se desviam do nosso cronograma de lançamento? Por que a previsão para o ano atual não está levando em consideração os programas que estão em desenvolvimento ativo? Quando podemos esperar que nossos relatórios de custos reflitam com precisão as mudanças upstream?
Repensando as interações de serviço como fluxos de trocas de eventos – em oposição a uma sequência de solicitações síncronas – nos lança infraestrutura que seja inerentemente assíncrona. Promove a dissociação e fornece rastreabilidade como cidadão de primeira classe em uma rede de transações distribuídas. Os eventos são muito mais do que gatilhos e atualizações. Eles se tornam o fluxo imutável do qual podemos reconstruir todo o estado do sistema.
Movendo -se para um modelo de publicação/subscrição permite que todos os serviços publiquem suas mudanças como eventos em um barramento de mensagens, que pode ser consumido por outro serviço de interesse que precisa ajustar seu estado do mundo. Esse modelo nos permite rastrear se os serviços estão sincronizados em relação às mudanças de estado e, se não, quanto tempo antes que possam ser sincronizadas. Essas idéias são extremamente poderosas ao operar um grande gráfico de serviços dependentes. A comunicação baseada em eventos e o consumo descentralizado nos ajudam a superar problemas que geralmente vemos em grandes gráficos de chamada síncrona (como mencionado acima).
A Netflix abraça o Apache Kafka ® como o padrão de fato para seus eventos, mensagens e necessidades de processamento de fluxo. Kafka atua como uma ponte para todas as comunicações de ponto a ponto e do Netflix Studio. Ele nos fornece a alta durabilidade e a arquitetura linearmente escalável e multi-ingestão necessária para sistemas operacionais na Netflix. Nossa Kafka interna como uma oferta de serviço fornece tolerância a falhas, observabilidade, implantações de várias regiões e autoatendimento. Isso facilita para todo o nosso ecossistema de microsserviços produzir e consumir facilmente eventos significativos e liberar o poder da comunicação assíncrona.
Uma troca de mensagens típica no ecossistema do Netflix Studio se parece com o seguinte:
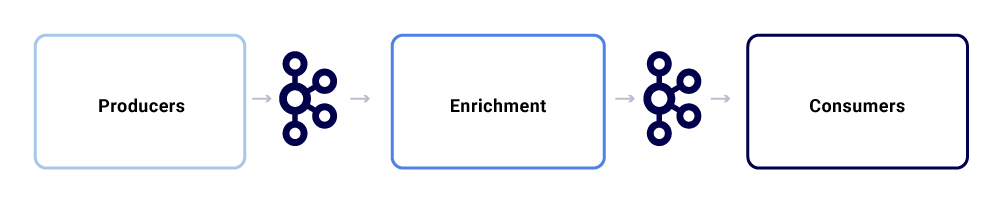
Podemos quebrá-los como três subcomponentes principais.
Produtores
Um produtor pode ser qualquer sistema que queira publicar todo o seu estado ou sugerir que uma parte crítica de seu estado interno mudou para uma entidade específica. Além da carga útil, um evento precisa aderir a um formato normalizado, o que facilita o rastreamento e a compreensão. Este formato inclui:
- Uuid: Identificador universalmente único
- Tipo: Um dos tipos de criação, leitura, atualização ou exclusão (CRUD)
- TS: Timestamp do evento
Alterar as ferramentas de captura de dados (CDC) são outra categoria de produtores de eventos que derivam eventos de alterações no banco de dados. Isso pode ser útil quando você deseja disponibilizar alterações no banco de dados para vários consumidores. Também usamos esse padrão para replicar os mesmos dados entre os datacenters (para bancos de dados mestre único). Um exemplo é quando temos dados no MySQL que precisam ser indexados no Elasticsearch ou Apache Solr ™. O benefício do uso do CDC é que ele não impõe carga adicional no aplicativo de origem.
Para eventos do CDC, o campo de tipo no formato de evento facilita a adaptação e a transformação dos eventos, conforme exigido pelos respectivos coletores.
Enriquecedores
Uma vez que os dados existam em Kafka, vários padrões de consumo podem ser aplicados a ele. Os eventos são usados de várias maneiras, inclusive como gatilhos para cálculos de sistema, transferência de carga útil para comunicação quase em tempo real e pistas para enriquecer e materializar visualizações na memória dos dados.
O enriquecimento de dados está se tornando cada vez mais comum onde os microsserviços precisam da visão completa de um conjunto de dados, mas parte dos dados vem de outro serviço’S DATASET. Um conjunto de dados unido pode ser útil para melhorar o desempenho da consulta ou fornecer uma visão de tempo quase real dos dados agregados. Para enriquecer os dados do evento, os consumidores leem os dados de Kafka e chamam outros serviços (usando métodos que incluem GRPC e GraphQL) para construir o conjunto de dados unido, que são mais tarde alimentados com outros tópicos de Kafka.
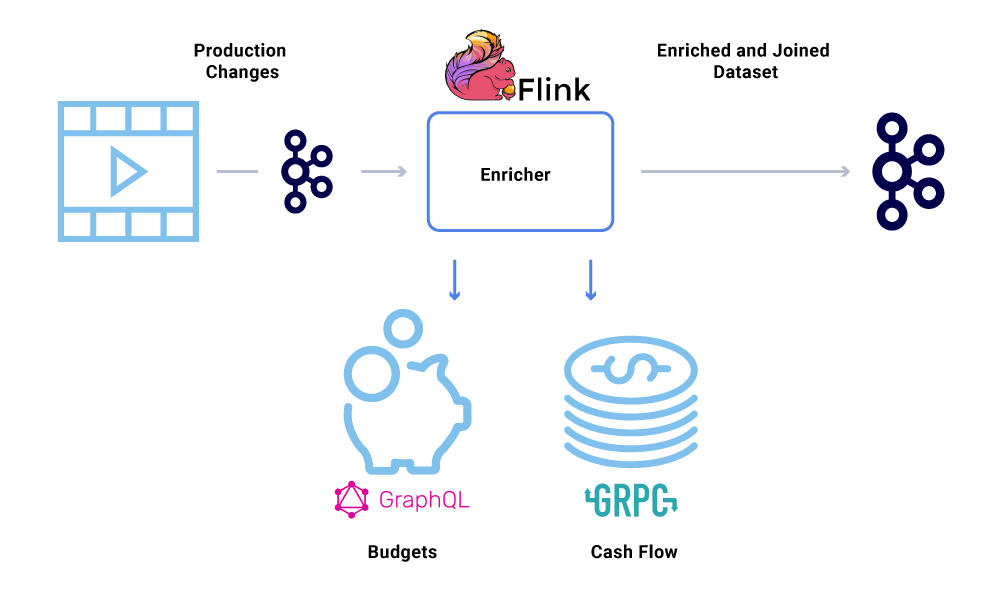
O enriquecimento pode ser executado como um microsserviço separado, responsável por fazer o fan-Out e por materializar conjuntos de dados. Há casos em que queremos fazer um processamento mais complexo, como janela, sessão e gerenciamento de estado. Para esses casos, é recomendável usar um mecanismo de processamento de fluxo maduro em cima de Kafka para construir a lógica de negócios. Na Netflix, usamos o Apache Flink ® e o RocksDB para fazer processamento de transmissão. Nós’também considerando o KSQLDB para fins semelhantes.
Pedidos de eventos
Um dos principais requisitos dentro de um conjunto de dados financeiros é a ordem estrita dos eventos. Kafka nos ajuda a conseguir isso é enviando mensagens com chave. Qualquer evento ou mensagem enviada com a mesma chave terá pedidos garantidos, pois eles são enviados para a mesma partição. No entanto, os produtores ainda podem atrapalhar a ordem dos eventos.
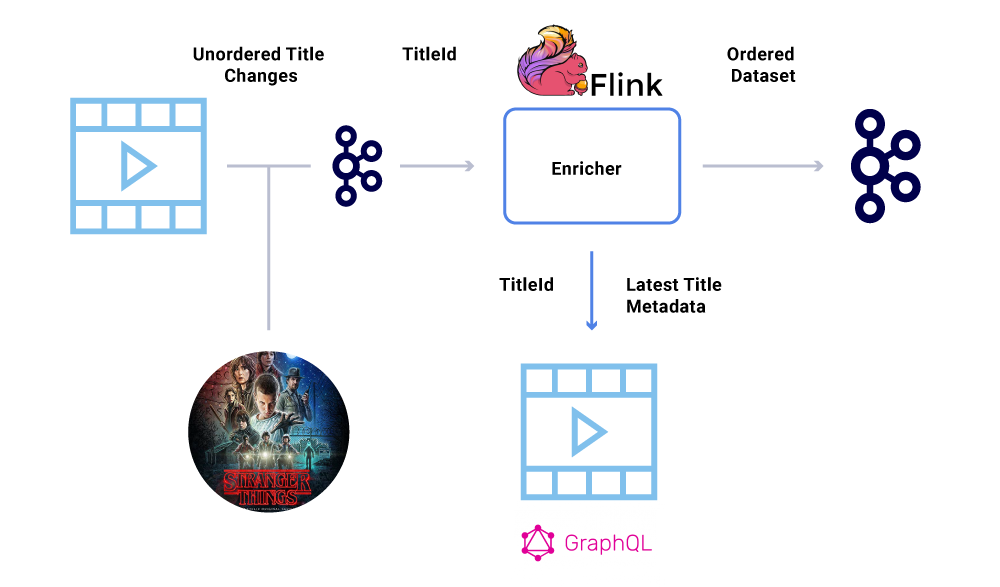
Por exemplo, a data de lançamento de “Coisas estranhas” foi originalmente transferido de julho a junho, mas depois de junho a julho. Por vários motivos, esses eventos podem ser escritos na ordem errada para Kafka (tempo limite da rede quando o produtor tentou chegar a Kafka, um bug de simultaneidade no código do produtor, etc.). Um soluço de pedido poderia ter impactado fortemente vários cálculos financeiros.
Para contornar esse cenário, os produtores são incentivados a enviar apenas o ID principal da entidade que mudou e não a carga útil completa na mensagem Kafka. O processo de enriquecimento (descrito na seção acima) consulta o serviço de origem com o ID da entidade para obter o estado/carga útil mais atualizado, fornecendo assim uma maneira elegante de contornar a questão fora de ordem. Nós nos referimos a isso como Materialização atrasada, e garante conjuntos de dados ordenados.
Consumidores
Usamos a Spring Boot para implementar muitos dos microsserviços consumidos que lêem dos tópicos de Kafka. O Spring Boot oferece ótimos consumidores de kafka embutidos chamados Spring Kafka Connectores, que tornam o consumo sem costura, fornecendo maneiras fáceis de conectar anotações para consumo e deserialização de dados.
Um aspecto dos dados que nós não temos’T discutido ainda são contratos. Ao dimensionar nosso uso de fluxos de eventos, acabamos com um grupo variado de conjuntos de dados, alguns dos quais são consumidos por um grande número de aplicativos. Nesses casos, definir um esquema na saída é ideal e ajuda a garantir a compatibilidade com versões anteriores. Para fazer isso, aproveitamos o Registro de Esquema Confluente e o Apache Avro ™ para construir nossos fluxos esquematizados para versões de dados de dados.
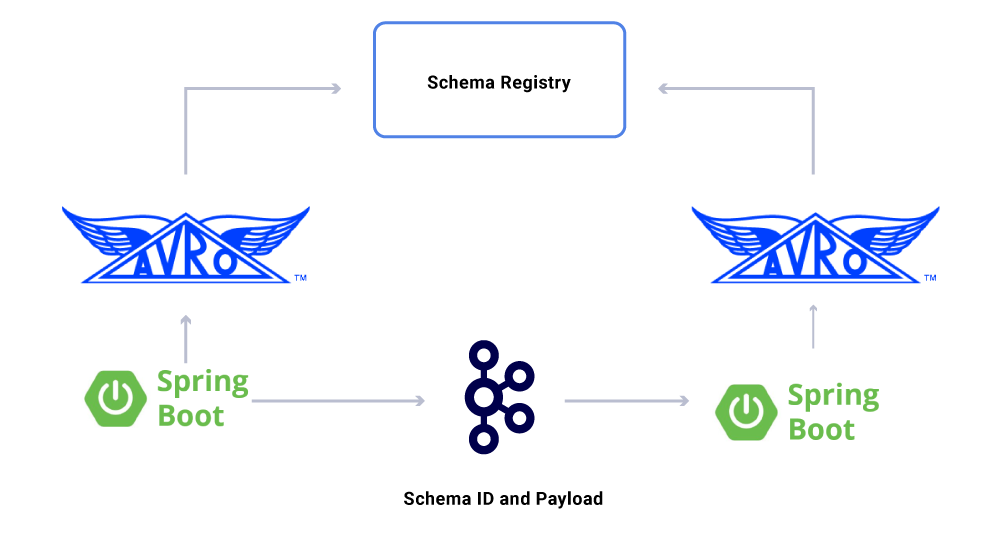
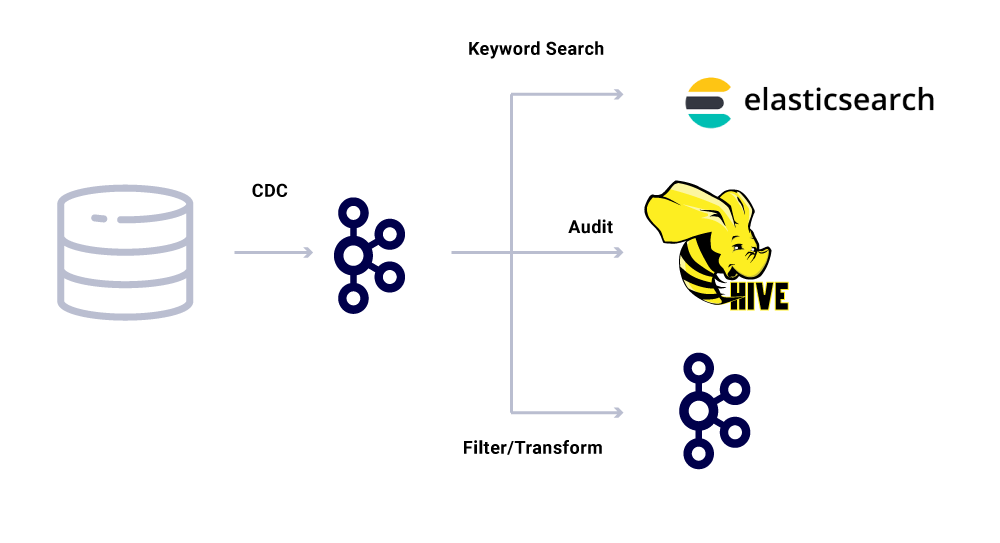
Além dos consumidores de microsserviços dedicados, também temos pia CDC que indexam os dados em uma variedade de lojas para análises adicionais. Isso inclui o Elasticsearch for Keyword Pesquisa, o Apache Hive ™ para auditoria e o próprio Kafka para mais processamento a jusante. A carga útil dessas pias é diretamente derivada da mensagem Kafka usando o campo de identificação como chave primária e tipo para identificar operações do CRUD.
Garantias de entrega de mensagens
Garantir exatamente uma vez que a entrega em um sistema distribuído não é trivial devido às complexidades envolvidas e uma infinidade de partes móveis. Os consumidores devem ter um comportamento idempotente para explicar qualquer infraestrutura potencial e contratempos produtores.
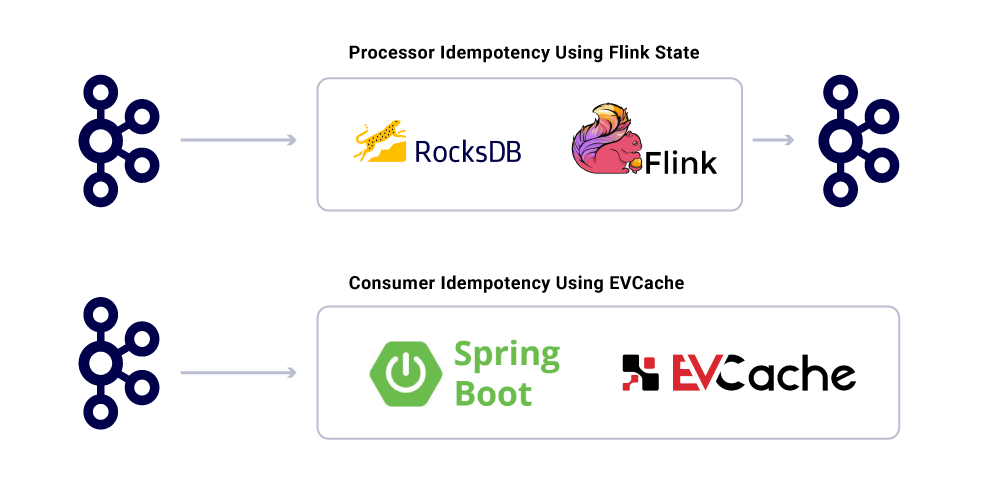
Apesar do fato de os aplicativos serem idempotentes, eles não devem repetir operações pesadas de computação para mensagens já processadas. Uma maneira popular de garantir isso é acompanhar o Uuid de mensagens consumidas por um serviço em um cache distribuído com expiração razoável (definido com base em acordos de nível de serviço (SLA). Sempre que o mesmo UUID é encontrado dentro do intervalo de expiração, o processamento é ignorado.
O processamento no Flink fornece essa garantia usando seu gerenciamento de estado baseado em rocksdb interno, com a chave sendo o Uuid da mensagem. Se você quiser fazer isso puramente usando Kafka, Kafka Streams oferece uma maneira de fazer isso também. Consumindo aplicativos com base no spring boot use evcache para conseguir isso.
Monitorando os níveis de serviço de infraestrutura
Isto’S Crucial para a Netflix ter uma visão em tempo real dos níveis de serviço em sua infraestrutura. Netflix escreveu Atlas para gerenciar dados de séries temporais dimensionais, a partir das quais publicamos e visualizamos métricas. Utilizamos uma variedade de métricas publicadas por produtores, processadores e consumidores para nos ajudar a construir uma imagem quase em tempo real de toda a infraestrutura.
Alguns dos aspectos principais que monitoramos são:
- Sla de frescura
- Qual é o tempo a fim da produção de um evento até chegar a todos os afiados?
- Qual é o atraso de processamento para todo consumidor?
- Quão grande é a carga útil capaz de enviar?
- Devemos comprimir os dados?
- Estamos utilizando com eficiência nossos recursos?
- Podemos consumir mais rápido?
- Somos capazes de criar um ponto de verificação para o nosso estado e retomar no caso de falhas?
- Se não conseguirmos acompanhar o evento Firehose, podemos aplicar a contrapressão às fontes correspondentes sem travar nosso aplicativo?
- Como lidamos com explosões de eventos?
- Estamos suficientemente provisionados para conhecer o SLA?
Sinopse
A Netflix Studio Productions and Finance Team abraça a governança distribuída como o modo de sistemas de arquitetura. Usamos Kafka como nossa plataforma de escolha para trabalhar com eventos, que são uma maneira imutável de gravar e derivar o estado do sistema. Kafka nos ajudou a alcançar maiores níveis de visibilidade e dissociação em nossa infraestrutura, ajudando -nos a dimensionar organicamente as operações. Está no coração de revolucionar a infraestrutura do estúdio da Netflix e, com ela, a indústria cinematográfica.
Interessado em mais?
Se você’D gostaria de saber mais, você pode ver a gravação e os slides da minha cúpula de Kafka San Francisco Apresentation Eventing Things – Um original da Netflix!
Netflix: Como o Apache Kafka transforma dados de milhões em inteligência
Netflix gastou US $ 16 bilhões em produção de conteúdo em 2020. Em janeiro de 2021, o Netflix Mobile App (iOS e Android) foi baixado 19 milhões de vezes e um mês depois, a empresa anunciou que havia atingido 203.66 milhões de assinantes em todo o mundo. Isto’é seguro assumir que a escala de dados que a empresa coleta e processa é enorme. A questão é –
Como a Netflix processa bilhões de registros e eventos de dados para tomar decisões críticas de negócios?
Com um orçamento anual de conteúdo no valor de US $ 16 bilhões, os tomadores de decisão da Netflix ARM’T É tomar decisões relacionadas ao conteúdo com base na intuição. Em vez disso, seus curadores de conteúdo usam tecnologia de ponta para entender enormes quantidades de dados sobre o comportamento do assinante, preferências de conteúdo do usuário, custos de produção de conteúdo, tipos de conteúdo que funcionam, etc. Esta lista continua.
Os usuários da Netflix gastam uma média de 3.2 horas por dia em sua plataforma e são constantemente alimentadas com as últimas recomendações da Netflix’S Proprietário mecanismo de recomendação. Isso garante que a rotatividade de assinantes seja baixa e atrai novos assinantes a se inscrever. A entrega de conteúdo orientada a dados está na frente e no centro disso.
Então, o que está sob o capô de uma perspectiva de processamento de dados?
Em outras palavras, como a Netflix construiu uma espinha dorsal de tecnologia que permitia a tomada de decisão orientada a dados em uma escala tão grande? Como alguém entende o comportamento do usuário de 203 milhões de assinantes?
A Netflix usa o que chama de keystone Data Pipeline. Em 2016, este pipeline estava processando 500 bilhões de eventos por dia. Esses eventos incluíram logs de erros, atividades de visualização do usuário, atividades da interface do usuário, eventos de solução de problemas e muitos outros conjuntos de dados valiosos.
De acordo com a Netflix, conforme publicado em seu blog de tecnologia:
O Keystone Pipeline é uma infraestrutura de publicação, coleção e roteamento unificada para o processamento de lote e fluxo.
Os clusters kafka são uma parte central do pipeline de dados Keystone na Netflix. Em 2016, o Pipeline da Netflix usou 36 clusters Kafka para processar bilhões de mensagens por dia.
Então, o que é apache kafka? E, por que se tornou tão popular?
Apache Kafka é uma plataforma de streaming de código aberto que permite o desenvolvimento de aplicativos que ingerem um alto volume de dados em tempo real. Foi originalmente construído pelos gênios no LinkedIn e agora é usado no Netflix, Pinterest e Airbnb, para citar alguns.
Kafka faz especificamente quatro coisas:
- Ele permite que os aplicativos publiquem ou assinem dados ou fluxos de eventos
- Ele armazena registros de dados com precisão e é altamente tolerante a falhas
- É capaz de processamento de dados em tempo real e de alto volume.
- É capaz de absorver e processar trilhões de registros de dados por dia, sem problemas de desempenho
As equipes de desenvolvimento de software podem alavancar Kafka’S Capacidades com as seguintes APIs:
- API do produtor: Esta API permite que um microsserviço ou aplicativo publique um fluxo de dados em um tópico Kafka em particular. Um tópico Kafka é um log que armazena dados e registros de eventos na ordem em que ocorreram.
- API do consumidor: Esta API permite que um aplicativo se inscreva nos fluxos de dados de um tópico Kafka. Usando a API do consumidor, os aplicativos podem ingerir e processar o fluxo de dados, que servirá como entrada para o aplicativo especificado.
- API Streams: Esta API é crítica para dados sofisticados de dados e transmissão de eventos. Essencialmente, ele consome fluxos de dados de vários tópicos de Kafka e é capaz de processar ou transformar isso conforme necessário. Pós-processamento, esse fluxo de dados é publicado em outro tópico Kafka a ser usado a jusante e/ou transformar um tópico existente.
- API do conector: Em aplicações modernas, há uma necessidade constante de reutilizar produtores ou consumidores e integrar automaticamente uma fonte de dados em um cluster kafka. Kafka Connect torna isso desnecessário por está conectando Kafka a sistemas externos.
Principais benefícios de Kafka
De acordo com o site da Kafka, 80% de todas as empresas da Fortune 100 usam Kafka. Uma das maiores razões para isso é que ele se encaixa bem com aplicações de missão crítica.
As principais empresas estão usando Kafka pelos seguintes motivos:
- Permite a dissociação de fluxos de dados e sistemas com facilidade
- Foi projetado para ser distribuído, resiliente e tolerante a falhas
- A escalabilidade horizontal de Kafka é uma de suas maiores vantagens. Pode escalar para 100s de grupos e milhões de mensagens por segundo
- Ele permite o streaming de dados em tempo real de alto desempenho, uma necessidade crítica em aplicativos de larga escala e orientados a dados
As maneiras pelas quais Kafka é usado para otimizar o processamento de dados
Kafka está sendo usado em toda a indústria para uma variedade de propósitos, incluindo, entre outros
- Processamento de dados em tempo real: Além de seu uso em empresas de tecnologia, a Kafka é parte integrante do processamento de dados em tempo real na indústria de manufatura, onde dados de alto volume vêm de um grande número de dispositivos e sensores de IoT
- Monitoramento do site em escala: Kafka é usado para rastrear o comportamento do usuário e a atividade do site em sites de alto tráfego. Ajuda no monitoramento em tempo real, processamento, conexão com Hadoop e data offline
- Rastreando métricas de chave: Como Kafka pode ser usado para agregar dados de diferentes aplicativos a um feed centralizado, ele facilita o monitoramento de dados operacionais de alto volume
- Agregação de log: Ele permite que dados de várias fontes sejam agregados em um log para obter clareza sobre o consumo distribuído
- Sistema de mensagens: Ele automatiza aplicativos de processamento de mensagens em larga escala
- Processamento de fluxo: Depois que os tópicos de Kafka são consumidos como dados brutos no processamento de dutos em vários estágios, são agregados, enriquecidos ou transformados em novos tópicos para consumo ou processamento adicional
- Dependências do sistema de desacoplamento
- Integratations com Spark, Flink, Storm, Hadoop e outras tecnologias de big data
Empresas que usam Kafka para processar dados
Como resultado de sua versatilidade e funcionalidade, Kafka é usado por alguns do mundo’S empresas de tecnologia que mais crescem para vários fins:
- Uber-Reúna um usuário, táxi e dados em tempo real para calcular e prever a demanda e calcular preços de ondas em tempo real
- LinkedIn-Impede o spam e coleta interações do usuário para fazer melhores recomendações de conexão em tempo real
- Twitter – parte de sua infraestrutura de processamento de fluxo de tempestades
- Spotify – parte de seu sistema de entrega de log
- Pinterest – parte de seu pipeline de coleção de logs
- Airbnb – Pipeline de eventos, rastreamento de exceções, etc.
- Cisco – para OpenSoc (Centro de Operações de Segurança)
Grupo de mérito’s especialização em kafka
No Merit Group, trabalhamos com parte do mundo’S líderes empresas de inteligência B2B como Wilmington, Dow Jones, Glenigan e Haymarket. Nossas equipes de dados e engenharia trabalham em estreita colaboração com nossos clientes para criar produtos de dados e ferramentas de inteligência de negócios. Nosso trabalho afeta diretamente o crescimento dos negócios, ajudando nossos clientes a identificar oportunidades de alto crescimento.
Nossos serviços específicos incluem coleta de dados de alto volume, transformação de dados usando IA e ML, assistência na web e desenvolvimento de aplicativos personalizado.
Nossa equipe também traz para a tabela profunda experiência na construção de aplicativos de streaming de dados em tempo real e processamento de dados. Nossa experiência em Kafka é especialmente útil neste contexto.
ПбблиоIц ц ччаgl тни deve
Para sistemas arquitetos que registram e derivam o estado do sistema, a Netflix aproveita o Apache Kafka e a governança distribuída. Nitin s. compartilha como isso os ajuda a alcançar a visibilidade e a dissociação em sua infraestrutura enquanto amplia organicamente as operações: https: // lnkd.in/gfxaa6g
Como o Netflix usa o Kafka para streaming distribuído
confluente.io
- КопироÊ
Crente, marido, pai de 5 anos, gerente de infraestrutura e serviços de TI, líder da equipe, desenvolvedor.
A Netflix constrói uma plataforma confiável e escalável com fornecimento de eventos, MQTT e Alpakka-kafka
A Netflix publicou recentemente uma postagem no blog detalhando como construiu uma plataforma de gerenciamento de dispositivos confiável usando uma implementação de fornecimento de eventos baseada em MQTT. Para dimensionar sua solução, a Netflix utiliza Apache Kafka, Alpakka-Kafka e Charroachdb.
A plataforma de gerenciamento de dispositivos da Netflix é o sistema que gerencia dispositivos de hardware usados para testes automatizados de seus aplicativos. Os engenheiros da Netflix Benson Ma e Alok Ahuja descrevem a jornada pela qual a plataforma passou:
Kafka Streams Processamento pode ser difícil de acertar. (. ) Felizmente, os primitivos fornecidos por Akka Streams e Alpakka-Kafka nos capacitam a alcançar exatamente isso, permitindo-nos criar soluções de streaming que correspondam aos fluxos de trabalho de negócios que temos enquanto ampliavam a produtividade do desenvolvedor na criação e manutenção dessas soluções. Com o processador baseado em alpakka-kafka no local (. ), garantimos a tolerância de falhas no lado do consumidor do plano de controle, que é essencial para permitir a agregação de estado de dispositivo precisa e confiável na plataforma de gerenciamento de dispositivos.
(. ) A confiabilidade da plataforma e seu plano de controle repousam em um trabalho significativo realizado em várias áreas, incluindo o transporte de MQTT, autenticação e autorização e monitoramento de sistemas. (. ) Como resultado deste trabalho, podemos esperar que a plataforma de gerenciamento de dispositivos continue a escalar para aumentar as cargas de trabalho ao longo do tempo, à medida que a bordo cada vez mais dispositivos em nossos sistemas.
O diagrama a seguir descreve a arquitetura.

Fonte: https: // netflixtechblog.COM/ROO PARA RELIAÇÃO DEVICE-MANOGEM-PLATFORM-4F86230CA623
Um computador de automação de referência local (RAE), o computador incorporado se conecta a vários dispositivos em teste (DUT). O Serviço de Registro Local é responsável pela detecção, integração e manutenção de informações sobre todos os dispositivos conectados no RAE. À medida que os atributos e propriedades do dispositivo mudam ao longo do tempo, ele salva essas mudanças no registro local e, simultaneamente, publicou a montante em um plano de controle baseado em nuvem. Além das mudanças de atributo, o registro local publica um instantâneo completo do registro do dispositivo em intervalos regulares. Esses eventos do ponto de verificação permitem uma reconstrução estatal mais rápida pelos consumidores do feed de dados enquanto se protege contra atualizações perdidas.
As atualizações são publicadas na nuvem usando o MQTT. MQTT é um protocolo de mensagens padrão do Oasis para a Internet das Coisas (IoT). É um transporte de mensagens de publicação/subscrição leve e confiável, ideal para conectar dispositivos remotos com uma pequena pegada de código e largura de banda de rede mínima. O corretor MQTT é responsável por receber todas as mensagens, filtrá -las e enviá -las para os clientes inscritos de acordo.
Netflix usa o Apache Kafka em toda a organização. Consequentemente, uma ponte converte mensagens MQTT em Records Kafka. Ele define a chave de registro para o tópico MQTT que a mensagem foi atribuída. MA e Ahuja descrevem que “como as atualizações do dispositivo publicadas no MQTT contêm o Device_Session_id No tópico, todas as atualizações de informações do dispositivo para uma determinada sessão de dispositivo aparecerão efetivamente na mesma partição Kafka, dando-nos assim uma ordem de mensagem bem definida para consumo.”
O registro em nuvem ingere as mensagens publicadas, as processa e empurra dados materializados em um armazenamento de dados apoiado por barraca. Cockroachdb é uma implementação de uma classe de sistemas RDBMS chamada NewsQL. Ma e Ahuja explicam a escolha da Netflix:
A barata é escolhida como o armazenamento de dados de apoio, pois ofereceu recursos SQL, e nosso modelo de dados para os registros do dispositivo foi normalizado. Além disso, diferentemente de outras lojas SQL, a barraca é projetada desde o início para ser horizontalmente escalável, que aborda nossas preocupações sobre a capacidade do Registro de Cloud de escalar com o número de dispositivos a bordo na plataforma de gerenciamento de dispositivos.
O diagrama a seguir mostra o pipeline de processamento Kafka compreendendo o registro de nuvem.

Fonte: https: // netflixtechblog.COM/ROO PARA RELIAÇÃO DEVICE-MANOGEM-PLATFORM-4F86230CA623
A Netflix considerou muitas estruturas para a implementação dos dutos de processamento de fluxos representados acima. Essas estruturas incluem fluxos de kafka, primavera kafkalistener, reator de projeto e flink. Eventualmente escolheu Alpakka-kafka. O motivo dessa escolha é que o Alpakka-Kafka fornece integração de inicialização da mola, juntamente com o “controle de granulação fina sobre o processamento de fluxos, incluindo suporte automático de pressão de retroilúntrias e supervisão de fluxos.”Além disso, de acordo com Ma e Ahuja, Akka e Alpakka-Kafka são mais leves que as alternativas e, como são mais maduras, os custos de manutenção ao longo do tempo serão mais baixos.
A implementação baseada em alpakka-kafka substituiu uma implicação baseada na primavera de Kafkalistsner da primavera. As métricas medidas na nova implementação da produção revelam que o suporte nativo de pressão de back-pressão de Alpakka-Kafka pode escalar dinamicamente seu consumo de kafka. Ao contrário de Kafkalistener, Alpakka-kafka não consuma ou consumir mensagens kafka. Além disso, uma queda nos valores máximos de atraso do consumidor após a liberação revelou que Alpakka-kafka e os recursos de streaming de Akka têm um bom desempenho em escala, mesmo diante de cargas repentinas de mensagem.

