
Somente na memória: malware sem arquivo – um TTP indescritível
Se os métodos de aprendizado de máquina de ar, lista de permissões, planos de areia e até mesmo os métodos de aprendizado de máquina não podem proteger contra ataques sem arquivo, o que’está à esquerda? As organizações podem se proteger adotando uma abordagem integrada que combina vários métodos.
Resumo:
Malware somente de memória, também conhecido como malware sem arquivo, vem ganhando atenção devido a violações de dados recentes como o assalto de dados de destino. Esses tipos de programas de malware se carregam na RAM e não se instalam no disco rígido, tornando -os difíceis de detectar. No entanto, existem várias razões pelas quais o malware somente de memória não deve ser uma grande preocupação.
Pontos chave:
- A maioria dos malware somente de memória não pode persistir através de uma reinicialização, facilitando a limpeza.
- Os programas de antimalware são mais eficientes na digitalização da memória do que a digitalização de um disco rígido ou SSD.
- Não há evidências sugerindo que o malware somente de memória seja mais difícil de detectar do que outros tipos de malware.
- Malware somente de memória existe há muito tempo, e os programas antimalware podem detectá-los prontamente.
Questões:
- Quais são os principais pontos em relação ao malware somente de memória?
Os principais pontos em relação ao malware somente de memória são que a maioria dos malware somente de memória não pode sobreviver a uma reinicialização, os programas de antimalware não têm problemas para digitalizar a memória, não há evidências sugerindo que o malware somente de memória seja mais difícil de detectar, e malware apenas de memória existe há muito tempo. - Por que é mais fácil limpar o malware somente de memória?
O malware somente de memória pode ser facilmente limpo, reiniciando o computador, pois ele não persiste através de uma reinicialização. - Por que os programas de antimalware são mais eficientes na memória de digitalização?
A memória de digitalização é muito mais rápida do que a digitalização de um disco rígido ou SSD, e há menos RAM para digitalizar em comparação com o espaço do disco. - Existe alguma evidência sugerindo que o malware somente de memória é mais difícil de detectar?
Não, não há evidências sugerindo que o malware somente de memória seja mais difícil de detectar. Programas de antimalware podem detectar prontamente malware somente de memória. - Malware somente de memória existe há muito tempo?
Sim, malware somente de memória existe há muito tempo. O Worm SQL Slammer em 2003 é um exemplo de malware somente de memória. - Quais são os benefícios do malware somente de memória?
Os benefícios dos malware somente de memória incluem limpeza mais fácil por meio de reinicialização, varredura mais rápida por programas de antimalware e nenhuma evidência sugerindo maior dificuldade na detecção. - Quais são alguns equívocos comuns sobre malware somente de memória?
Alguns conceitos errôneos comuns sobre malware somente de memória são que é mais difícil de detectar e mais perigoso do que outros tipos de malware. - Como o malware somente de memória se compara a outros tipos de malware?
O malware somente de memória não é inerentemente mais perigoso ou mais difícil de detectar do que outros tipos de malware. - Existem estudos sobre a detecção de malware somente de memória?
Não houve estudos indicando que o malware somente de memória é mais difícil de detectar ou aumentou falsos negativos. - Por que as organizações não devem se preocupar com malware somente de memória?
As organizações não devem se preocupar com o malware somente de memória, pois podem ser facilmente limpas, os programas de antimalware podem detectá-lo com eficiência, e não há evidências sugerindo maior dificuldade na detecção.
Respostas:
- O malware somente de memória pode ser resumido pelos seguintes pontos-chave: a maioria dos malware somente de memória não pode sobreviver a uma reinicialização, os programas de antimalware são eficientes na digitalização da memória, não há evidências sugerindo maior dificuldade na detecção, e malware exclusivo de memória existe há muito tempo. Esses pontos-chave oferecem garantias de que o malware somente de memória não deve ser uma grande preocupação.
- O malware somente de memória é mais fácil de limpar porque não pode persistir através de uma reinicialização. Ao fechar o ponto de entrada inicial e reiniciar o computador, o malware somente de memória é efetivamente removido sem a necessidade de extensa pesquisa e limpeza.
- Os programas antimalware são mais eficientes na memória de digitalização em comparação com a digitalização de um disco rígido ou SSD. A memória de digitalização é significativamente mais rápida e requer menos recursos, permitindo que os programas de antimalware detectem e removam rapidamente malware somente de memória.
- Não há evidências sugerindo que o malware somente de memória seja mais difícil de detectar do que outros tipos de malware. Programas de antimalware detectam prontamente malware somente de memória, e não houve estudos indicando maior dificuldade em detecção ou maiores falsos negativos.
- Malware somente de memória existe há muito tempo, com exemplos como o SQL Slammer Worm em 2003. Apesar de sua rápida propagação e impacto potencial, o malware somente de memória é facilmente detectável por programas de antimalware.
- Os benefícios do malware somente de memória incluem limpeza mais fácil através da reinicialização. Como o malware somente de memória não pode persistir através de uma reinicialização, basta reiniciar o computador limpa qualquer traço do malware, eliminando a necessidade de procedimentos de limpeza complexos.
- Alguns conceitos errôneos comuns sobre malware somente de memória são que é mais difícil de detectar e mais perigoso do que outros tipos de malware. No entanto, os programas de antimalware não têm problemas para detectar malware somente de memória, e não há evidências que apoiem perigo aumentado em comparação com outros tipos de malware.
- O malware somente de memória não é inerentemente mais perigoso ou mais difícil de detectar do que outros tipos de malware. Embora ofereça certas vantagens para os invasores, como fugir de certos métodos de detecção, os programas de antimalware estão equipados para identificar e remover malware somente de memória.
- Não houve estudos indicando que o malware somente de memória é mais difícil de detectar ou aumentou falsos negativos. Os programas de antimalware podem detectar com segurança malware somente de memória, e não há evidências sugerindo que os métodos de detecção atuais sejam insuficientes.
- As organizações não devem se preocupar com o malware somente de memória, pois podem ser facilmente limpas, os programas de antimalware são eficientes na detecção, e não há evidências sugerindo maior dificuldade na detecção. Ao adotar uma abordagem integrada que combina vários métodos de segurança, as organizações podem proteger efetivamente contra malware somente de memória.
Esta história, “Você se se preocupe com malware apenas de memória?,”Foi publicado originalmente no infoworld.com. Continue com os últimos desenvolvimentos em segurança de rede e leia mais do blog de consultor de segurança de Roger Grimes no Infoworld.com. Para as últimas notícias de tecnologia de negócios, siga o infoworld.com no Twitter.
Somente na memória: malware sem arquivo – um TTP indescritível
O uso de malware e vivendo as técnicas da terra (LOTL) por atores de ameaças cibernéticas (CTAs) tem aumentado ao longo dos anos. Os dados das ferramentas de endpoint do WatchGuard indicam que cerca de 80 % dos ataques de arquivo ou LOTL em 2020 já foram detectados até o final de 2021. Os dados da Symantec também mostram um aumento significativo no uso malicioso das ferramentas legítimas dos CTAs de 2019 a 2020. A pesquisa do Instituto Ponemon dos profissionais de TI responsável pelo gerenciamento de riscos de endpoint confirma ainda os crescentes instâncias de malware e uso de lotl em ambientes corporativos em ambientes corporativos.
Referências:
Figura 1: Dados de 2019-2020 representando o uso malicioso de ferramentas legítimas. (Fonte: Symantec)
Colunista de segurança desde 2005, Roger Grimes possui mais de 40 certificações de computador e é autor de dez livros sobre segurança do computador.
direito autoral © 2014 IDG Communications, Inc.
Somente na memória: malware sem arquivo – um TTP indescritível
Se os métodos de aprendizado de máquina de ar, lista de permissões, planos de areia e até mesmo os métodos de aprendizado de máquina não podem proteger contra ataques sem arquivo, o que’está à esquerda? As organizações podem se proteger adotando uma abordagem integrada que combina vários métodos.
Você deve se preocupar com malware somente de memória?
O recente assalto de dados-alvo de mais de 40 milhões de registros de cartão de crédito tem muitos se preocupando com o impacto do malware somente de memória. O malware alvo, uma variante do Blackpos, faz parte de uma família de cavalos de Trojan conhecida como Trojan.Posram. Após a exploração inicial, esses programas simplesmente se carregam na RAM – eles não se instalam no disco rígido.
A falta de “pegada de software” torna os programas de malware somente para RAM indescritíveis. Algumas pessoas dizem que são realmente temidas. Devemos nos preocupar com eles mais do que outros programas de malware?
[Também no infoworld: 13 perguntas difíceis sobre a segurança do computador. | Acompanhe os principais problemas de segurança com o Newsletter central de segurança do Infoworld. ]
O pânico sobre os Trojans somente de memória me lembra todas as profecias do dia do juízo final sobre malware rootkit, que poderiam “se esconder facilmente dos programas antivírus.”Isso traz à mente a histeria de anteriores sobre vermes, vírus de anexo de e -mail, vírus de inicialização e seqüestradores de DNS. Esses tipos de malware recém -descobertos pareciam assustadores a princípio, mas os programas antimalware agora detectam todos eles. O único desafio ao software antimalware é acompanhar o grande número de novos programas de malware que aparecem todos os dias. Detectando um inteiro tipo de malware raramente tem sido um problema.
De fato, malware somente de memória é uma espécie de bênção, por alguns motivos.
Primeiro, a maioria dos malware somente de memória não pode viver através de uma reinicialização. É verdade, se você não consertou o que permitiu obter acesso inicial em primeiro lugar, o malware voltará. Mas como é bom que, se você fechar o orifício de entrada inicial, uma reinicialização simples limpará a bagunça de malware? Não há nenhuma caça ao redor do disco rígido tentando encontrar todos os lugares que modificou ou nos quais pode estar escondido, sem puxar vírus para fora dos executáveis do host e tentar decidir como colocar o Humpty-Dumpty novamente, não se perguntando se você tem tudo. Basta reiniciar seu computador e relaxar. Estou me imaginando em uma praia no México, relaxando com uma cerveja dourada.
Segundo, os programas antimalware adoram digitalizar memória para maus atores. São os itens que não são de memória que os atrasam. A memória de digitalização pode ser literalmente milhares de vezes mais rápida do que a digitalização de um disco rígido – é muito, muito mais rápido do que a digitalização de um SSD. Além disso, é claro, há muito menos RAM do que o disco para digitalizar. Os scanners de antimalware adorariam manter a memória, se pudessem; o atingido do desempenho evaporaria.
Terceiro, não vi estudos que dizem que malware somente de memória é mais difícil de detectar ou incorrido. É com isso que a maioria das pessoas está preocupada; Ainda não vi nenhuma evidência real.
Por fim, embora o Blackpos exista há apenas alguns anos, tivemos malware apenas de memória há muito tempo. O worm SQL Slammer de 2003, por exemplo, era apenas de memória. Até hoje, o SQL Slammer ainda detém o título do verme mais rápido. Ele explorou quase todos os servidores SQL não patches na Internet em cerca de 10 minutos. Mas, por mais ruim que fosse, adorei a limpeza: você corrige o servidor e reiniciou. Pronto! Coisa ruim foi para sempre. Ah, sim, é prontamente detectado por todos os programas antivírus do mundo.
Então, não, não tenho medo de malware somente de memória. Pelo contrário, estou cruzando os dedos e esperando que todo malware se torne apenas memória.
Esta história, “Você se se preocupe com malware apenas de memória?,”Foi publicado originalmente no infoworld.com. Continue com os últimos desenvolvimentos em segurança de rede e leia mais do blog de consultor de segurança de Roger Grimes no Infoworld.com. Para as últimas notícias de tecnologia de negócios, siga o infoworld.com no Twitter.
- As 10 empresas mais poderosas de segurança cibernética
- 7 tendências quentes de segurança cibernética (e 2 indo frio)
- As vulnerabilidades Apache Log4J: uma linha do tempo
- Usando a estrutura de segurança cibernética do NIST para lidar com o risco organizacional
- 11 Ferramentas de teste de penetração Os profissionais usam
- Segurança
- Dados e segurança da informação
- Malware
Colunista de segurança desde 2005, Roger Grimes possui mais de 40 certificações de computador e é autor de dez livros sobre segurança do computador.
Copyright © 2014 IDG Communications, Inc.
Somente na memória: malware sem arquivo – um TTP indescritível
Os dados da indústria revelam crescimento substancial em atores de ameaças cibernéticas (CTAs’) Uso de malware sem arquivo e vivendo as técnicas da terra (LOTL) nos últimos anos.
- Até o final de 2021, as ferramentas de endpoint do WatchGuard tinham “Já detectou cerca de 80 % do arquivo ou vivendo dos ataques terrestres que eles viram para todos os 2020.”
- Na Figura 1, vemos Symantec’S Dados de 2019 e 2020 revelam um pico notável em CTAs’ Uso malicioso de ferramentas legítimas durante esse período.
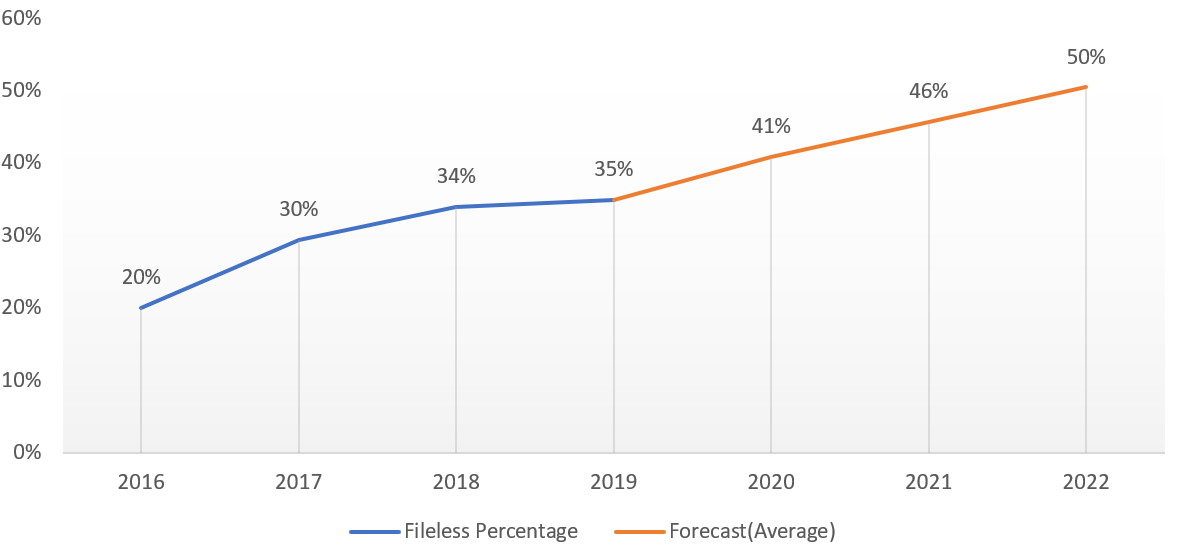
- A Figura 2 mostra como as instâncias de malware e o uso de lotl estão aumentando em ambientes corporativos, pois o Instituto Ponemon aprendeu ao pesquisar profissionais de TI responsáveis por gerenciar o risco de endpoint.
Figura 1: Dados de 2019-2020 representando o uso malicioso de ferramentas legítimas. (Fonte: Symantec)
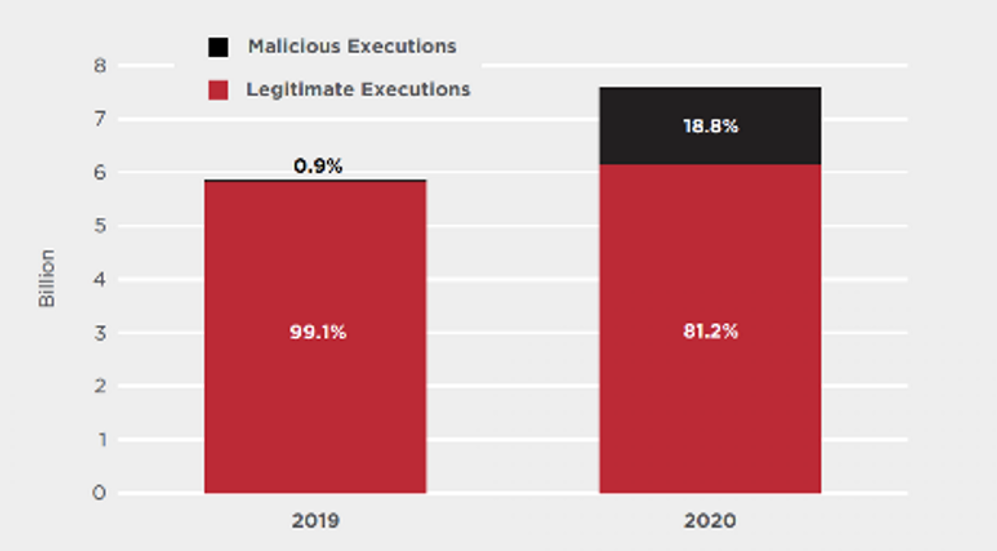
Figura 2: Previsão com base no Instituto Ponemon’s Anual 2020 Estudo sobre o Estado de Endpoint Segurança Pesquisa de Risco. (Fonte: Morphisec)
O que é malware sem arquivo?
Malware sem arquivo é um software malicioso que é executado na memória, em oposição ao malware tradicional que grava no disco usando executáveis maliciosos. Após a infecção, os CTAs que implantam malware sem arquivo geralmente alavancam o sistema legítimo e as ferramentas de administração como o Windows PowerShell e o Windows Management Instrumentation (WMI) para obter persistência pelo LOTL. Depois que os CTAs estabelecem uma posição na vítima’S Ambiente, eles podem escalar privilégios e se mover lateralmente pela rede (veja a Figura 3). Variantes comuns de malware de arquivo incluem Darkwatchman, PANDA LOUCADOR, BITRAT e AVEMARIARAT.
Figura 3: Cadeia de ataque de malware sem arquivo com exemplos

Malware sem arquivo é executado na memória e alavanca as ferramentas confiáveis, por isso geralmente parece benigno para sistemas de detecção de antivírus e intrusões baseados em assinatura, baseados em assinatura. Isso permite que ele opere não detectado, mantenha a persistência e deixe organizações de vítimas sem as ferramentas adequadas efetivamente cegas para uma intrusão contínua. De fato, organizações’ A forte dependência de ferramentas baseadas em assinatura para defender suas redes é provavelmente um motorista significativo que motiva os CTAs a atacar redes com malware sem arquivo.
Defendendo contra malware sem arquivo
De acordo com a análise da equipe de Inteligência de Ameaças Cyber (CTI) no Centro de Compartilhamento e Análise de Informações de Multi-Estado (MS-ISAC), os CTAs continuarão a comprometer as organizações a uma taxa crescente, apesar da implantação mais ampla de defesa organizacional em profundidade. De fato, sua avaliação sugere que malware e LOTL subirão para 50% do total de ataques contra ambientes corporativos em 2022, combinando assim a frequência de ataques baseados em arquivos pela primeira vez. (Esta disparidade pode resultar de CTAs’ Malware sem arquivo Uso de organizações de ultrapassagem’ implementações defensivas.)
As organizações se colocarão em uma postura significativamente melhor contra malware sem arquivo por não esperar para priorizar o seguinte:
- Defesa em profundidade: uma defesa cibernética eficaz contra malware sem arquivo alavancaria uma estratégia de defesa em profundidade que coloca as melhores práticas e ferramentas essenciais, como firewalls, IDs/IDs/sistemas de prevenção de intrusões, ess, segmentação de rede, rede e sistema de base, o princípio do mínimo privilegiado, gerenciamento de log, fortes requisitos de senha e patchesy.
- Serviços de Segurança do Endpoint do CIS (ESS): Fornecido pelo Centro de Segurança da Internet (CIS), este serviço analisa dados de endpoint para padrões suspeitos, incluindo os de malware sem arquivo e técnicas de LOTL. Em seguida, alerta ou bloqueia a atividade anômala, dependendo da natureza da ameaça.
- Controles de segurança críticos da CEI (Controles da CEI): um conjunto priorizado e recomendado de ações para defesa cibernética, os controles da CIS fornecem maneiras específicas e acionáveis de proteger contra os ataques mais difundidos e perigosos
Outras defesas importantes específicas para malware sem arquivo envolvem o emprego de uma combinação de interface de varredura antimalware (AMSI), monitoramento de comportamento, varredura de memória, restringindo o PowerShell a apenas scripts assinados, ou limitando o PowerShell e o WMI a estações de trabalho específicas, limitando macro para ativar apenas as contas específicas que precisam de acesso e inicializar o setor.
Proteção adicional para SLTTS
Quando se trata de lutar contra malware sem arquivo, você.S. As entidades governamentais estaduais, locais, tribais e territoriais (SLTT) precisam de toda a ajuda que possam obter. Felizmente, essas organizações podem encontrar amplo apoio ao ingressar no MS-ISAC. Como membros, eles receberão acesso a alertas e briefings de ameaças regulares que exploram o cenário de ameaças, incluindo a evolução de malware sem arquivo. Eles também se juntarão ao nosso programa de compartilhamento de indicadores que ingere/bloqueia indicadores maliciosos em tempo real. Essa inteligência, assim como os outros recursos da MS-ISAC, ajudará os SLTTs a se proteger contra malware sem arquivo daqui para frente.
Malware sem arquivo Explicado
Malware sem arquivo é um tipo de atividade maliciosa que usa ferramentas nativas e legítimas incorporadas em um sistema para executar um ataque cibernético. Ao contrário do malware tradicional, o malware sem arquivo não requer um invasor para instalar qualquer código em um alvo’sistema s, dificultando a detecção.
Essa técnica sem arquivo de usar ferramentas nativas para realizar um ataque malicioso às vezes é chamado de viver fora da terra ou lolbins
Técnicas comuns de malware sem arquivo
Enquanto os atacantes Don’É preciso instalar o código para lançar um ataque de malware sem arquivo, eles ainda precisam ter acesso ao meio ambiente para que possam modificar suas ferramentas nativas para servir seus propósitos. Acesso e ataques podem ser realizados de várias maneiras, como através do uso de:
- Explorar kits
- Ferramentas nativas seqüestradas
- Malware residente do registro
- Malware somente de memória
- Ransomware sem arquivo
- Credenciais roubadas
Explorar kits
Explorações são peças de código, sequências de comandos ou coleções de dados e kits de exploração são coleções de façanhas. Os adversários usam essas ferramentas para aproveitar as vulnerabilidades que são conhecidas por existir em um sistema operacional ou em um aplicativo instalado.
As façanhas são uma maneira eficiente de lançar um ataque de malware sem arquivo, porque podem ser injetados diretamente na memória sem exigir que nada seja escrito para disco. Os adversários podem usá -los para automatizar compromissos iniciais em escala.
Uma exploração começa da mesma maneira, independentemente de o ataque ser o arquivo ou usar malware tradicional. Normalmente, uma vítima é atraída por um email de phishing ou engenharia social. O kit de exploração geralmente inclui explorações para várias vulnerabilidades e um console de gerenciamento que o invasor pode usar para controlar o sistema. Em alguns casos, o kit de exploração incluirá a capacidade de digitalizar o sistema direcionado em busca de vulnerabilidades e depois criar e lançar uma exploração personalizada em tempo real.
Malware residente do registro
Malware residente de registro é malware que se instala no registro do Windows para permanecer persistente enquanto evita a detecção.
Geralmente, os sistemas Windows são infectados através do uso de um programa de conta -gotas que baixam um arquivo malicioso. Este arquivo malicioso permanece ativo no sistema direcionado, o que o torna vulnerável à detecção por software antivírus. Malware sem arquivo também pode usar um programa de conta -gotas, mas não’t baixando um arquivo malicioso. Em vez disso, o próprio programa conta.O código malicioso pode ser programado para ser lançado toda vez que o sistema operacional é lançado, e não há arquivo malicioso que possa ser descoberto – o código malicioso está oculto em arquivos nativos que não estão sujeitos a detecção AV.
A variante mais antiga desse tipo de ataque é Poweliks, mas muitos surgiram desde então, incluindo Kovter e Gootkit. Malware que modifica as chaves do registro é altamente provável que permaneça no local sem ser detectado por longos períodos de tempo.
Malware somente de memória
Malware somente de memória reside apenas na memória. Um exemplo de malware somente de memória é o Worm Duqu, que pode permanecer não detectado porque reside exclusivamente na memória. Duqu 2.0 vem em duas versões; O primeiro é um backdoor que permite ao adversário ganhar uma posição em uma organização. O adversário pode então usar a versão avançada do Duqu 2.0, que oferece recursos adicionais, como reconhecimento, movimento lateral e exfiltração de dados. Duqu 2.0 tem sido usado para violar as empresas com sucesso na indústria de telecomunicações e pelo menos um conhecido provedor de software de segurança.
Ransomware sem arquivo
Os adversários não se limitam a um tipo de ataque. Eles usam qualquer tecnologia que os ajudará a capturar sua carga útil. Hoje, os atacantes de ransomware estão usando técnicas sem arquivo para incorporar código malicioso em documentos através do uso de idiomas de script nativos, como macros ou para escrever o código malicioso diretamente na memória através do uso de uma exploração. O ransomware então sequestra ferramentas nativas como PowerShell para criptografar arquivos de reféns sem nunca ter escrito uma única linha para disco.
Credenciais roubadas
Os invasores podem iniciar um ataque sem arquivo através do uso de credenciais roubadas para que possam acessar seu alvo sob o disfarce de um usuário legítimo. Uma vez lá dentro, o invasor pode usar ferramentas nativas, como o Windows Management Instrumentation (WMI) ou o PowerShell para conduzir seu ataque. Eles podem estabelecer persistência escondendo código no registro ou no kernel ou criando contas de usuário que lhes concedam acesso a qualquer sistema que eles escolham.

Como os adversários usam ataques sem arquivo para evitar sua segurança
Faça o download deste white paper para aprender a anatomia detalhada de uma intrusão sem arquivo, incluindo o compromisso inicial, ganhando comando e controle, escalando privilégios e estabelecendo persistência.
Estágios de um ataque sem arquivo
Para demonstrar como um ataque sem arquivo pode funcionar, abaixo é um infográfico que ilustra uma intrusão de arquivo do mundo real descoberta pela equipe de Resposta de Incidentes de Serviços de Crowdstrike (IR).
Etapa 1: Ganhe acesso
Técnica: Explorar remotamente uma vulnerabilidade e use script da web para acesso remoto (por exemplo. Helicóptero da China)
O atacante ganha acesso remoto à vítima’sistema s, para estabelecer uma cabeça de praia para seu ataque.
Etapa 2: roubar credenciais
Técnica: Explorar remotamente uma vulnerabilidade e use script da web para acesso remoto (por exemplo. Mimikatz)
Usando o acesso obtido na etapa anterior, o invasor agora tenta obter credenciais para o ambiente que ele comprometeu, permitindo que ele se mova facilmente para outros sistemas nesse ambiente.
Etapa 3: Mantenha a persistência
Técnica: Modifique o registro para criar um backdoor (por exemplo. BILIDADE DE TENHAS STELTY)
Agora, o atacante cria um backdoor que permitirá que ele retorne a esse ambiente à vontade, sem ter que repetir as etapas iniciais do ataque.
Etapa 4: dados de exfiltrados
Técnica: Usa o sistema de arquivos e o utilitário de compressão interno para coletar dados e depois usa o FTP para fazer o upload dos dados
Na etapa final, o invasor reúne os dados que deseja e o prepara para a exfiltração, copiando -os em um local e depois comprimindo -os usando ferramentas de sistema prontamente disponíveis, como compactos. O atacante remove os dados da vítima’S Ambiente enviando -o via FTP.
Como detectar malware sem arquivo
Se os métodos de aprendizado de máquina de ar, lista de permissões, planos de areia e até mesmo os métodos de aprendizado de máquina não podem proteger contra ataques sem arquivo, o que’está à esquerda? As organizações podem se proteger adotando uma abordagem integrada que combina vários métodos.
Confie em indicadores de ataque em vez de indicadores de compromisso sozinho
Indicadores de ataque (IOAs) são uma maneira de adotar uma abordagem proativa contra ataques sem arquivo. IOAs não se concentram nas etapas de como um ataque está sendo executado – em vez disso, eles procuram sinais de que um ataque possa estar em andamento.
IOAs incluem sinais como execução de código, movimentos laterais e ações que parecem pretender encobrir sua verdadeira intenção.
IOAs não se concentram em como as etapas são lançadas ou executadas. Não importa se a ação foi iniciada a partir de um arquivo no disco rígido ou de uma técnica sem arquivo. A única coisa que importa é a ação executada, como ela se relacionou com outras ações, sua posição em uma sequência e suas ações dependentes. Esses indicadores revelam as verdadeiras intenções e objetivos por trás de seus comportamentos e os eventos ao seu redor.
Como ataques sem arquivo exploram idiomas legítimos de script, como PowerShell, e nunca são escritos para disco, eles não são detectados por métodos baseados em assinatura, na lista de permissões e na caixa de areia. Mesmo os métodos de aprendizado de máquina falham em analisar malware sem arquivo. Mas o IOAs procuram sequências de eventos que até o malware sem arquivo deve executar para alcançar sua missão.
E como os IOAs examinam intenção, contexto e sequências, eles podem até detectar e bloquear atividades maliciosas que são realizadas usando uma conta legítima, o que geralmente é o caso quando um invasor usa credenciais roubadas.
Empregar caça de ameaças gerenciadas
A caça às ameaças para malware sem arquivo é um trabalho demorado e trabalhoso que requer a coleta e a normalização de grandes quantidades de dados. No entanto, é um componente necessário em uma defesa que protege contra ataques sem arquivo e, por esses motivos, a abordagem mais pragmática para a maioria das organizações é entregar sua ameaça à caça a um fornecedor especializado.
Os serviços gerenciados de caça de ameaças estão assistindo o tempo todo, procurando proativamente intrusões, monitorando o ambiente e reconhecendo atividades sutis que passariam despercebidas pelas tecnologias de segurança padrão.
Como o crowdstrike pode impedir ataques sem arquivo em sua organização
Como vimos, técnicas sem arquivo são extremamente desafiadoras para detectar se você está confiando em métodos baseados em assinatura, sandboxing, lista de permissões ou até mesmo métodos de proteção de aprendizado de máquina.
Para proteger contra ataques furtivos e sem arquivo, o crowdstrike combina exclusivamente vários métodos em uma abordagem poderosa e integrada que oferece proteção incomparável. A plataforma CrowdStrike Falcon® fornece proteção de terminal de última geração em nuvem, por meio de um único agente leve e oferece uma variedade de métodos complementares de prevenção e detecção:
- Inventário de aplicativos descobre todos os aplicativos em execução em seu ambiente, ajudando a encontrar vulnerabilidades para que você possa corrigi -las ou atualizá -las e elas podem’é o alvo dos kits de exploração.
- Explorar o bloqueio para a execução de ataques sem arquivo por meio de explorações que aproveitam as vulnerabilidades não patches.
- Indicadores de ataque (IOAs) identificam e bloqueiam atividades maliciosas durante os estágios iniciais de um ataque, antes que ele possa executar completamente e infligir danos. Esse recurso também protege contra novas categorias de ransomware que não usam arquivos para criptografar sistemas de vítimas.
- Controle de script fornece visibilidade e proteção expandida contra ataques baseados em scripts de filmes.
- A varredura avançada de memória protege contra ataques sem arquivo e malware, como Apts, Ransomware e Ferramentas de Uso Dual, como ataque de cobalto na memória.
- A caça gerenciada pesquisa proativamente o tempo todo por atividades maliciosas que são geradas como resultado de técnicas sem arquivo.
Conheça o autor
Kurt Baker é o diretor sênior de marketing de produtos da Falcon Intelligence em Crowdstrike. Ele tem mais de 25 anos de experiência em cargos de liderança sênior, especializada em empresas de software emergentes. Ele tem experiência em inteligência de ameaças cibernéticas, análise de segurança, gerenciamento de segurança e proteção de ameaças avançadas. Antes de ingressar na Crowdstrike, Baker trabalhou em funções técnicas em Tripwire e co-fundou startups em mercados que variam de soluções de segurança corporativa a dispositivos móveis. Ele é bacharel em artes pela Universidade de Washington e agora está sediado em Boston, Massachusetts.
Uma abordagem de detecção de malware baseada em aprendizado profundo e memória forense
Universidade de Tecnologia de Qilu (Academia de Ciências de Shandong), Centro de Ciência da Computação de Shandong (Centro de Supercomputadores de 5 anos em Jinan), Laboratório Chave Provincial de Shandong de Redes de Computadores), Jinan 250014, China
Instituto Matemático, Academia Sérvia de Ciências e Artes, 11000 Belgrado, Sérvia
Autor a quem a correspondência deve ser abordada.
Simetria 2023, 15(3), 758; https: // doi.org/10.3390/SYM15030758
Recebido: 28 de dezembro de 2022 / revisado: 22 de fevereiro de 2023 / aceito: 17 de março de 2023 / publicado: 19 de março de 2023
Abstrato
À medida que os ataques cibernéticos se tornam mais complexos e sofisticados, novos tipos de malware se tornam mais perigosos e desafiadores para detectar. Em particular, malware sem arquivo injeta código malicioso na memória física diretamente sem deixar traços de ataque em arquivos de disco. Esse tipo de ataque está bem escondido e é difícil encontrar o código malicioso nos arquivos estáticos. Para processos maliciosos na memória, os métodos de detecção baseados em assinatura estão se tornando cada vez mais ineficazes. Enfrentando esses desafios, este artigo propõe uma abordagem de detecção de malware baseada em rede neural convolucional e na memória forense. Como o malware possui muitos recursos simétricos, o modelo de treinamento salvo pode detectar código malicioso com recursos simétricos. O método inclui a coleta de amostras estáticas e benignas executáveis, executando as amostras coletadas em uma caixa de areia e a construção de um conjunto de dados de executáveis portáteis na memória através da memória forense. Quando um processo está em execução, nem todo o conteúdo do programa é carregado na memória, de modo que fragmentos binários são utilizados para análise de malware, em vez de todos os arquivos executáveis portáteis (PE). Os fragmentos de arquivo PE são selecionados com diferentes comprimentos e locais. Realizamos vários experimentos no conjunto de dados produzidos para testar nosso modelo. O arquivo PE com 4096 bytes de fragmento de cabeçalho tem a maior precisão. Alcançamos uma precisão de previsão de até 97.48%. Além disso, um exemplo de ataque sem arquivo é ilustrado no final do artigo. Os resultados mostram que o método proposto pode detectar códigos maliciosos de maneira eficaz, especialmente o ataque sem arquivo. Sua precisão é melhor que a dos métodos comuns de aprendizado de máquina.
1. Introdução
Com o desenvolvimento da tecnologia da Internet, os ataques de malware tornaram -se mais prevalentes e sofisticados. Atualmente, o malware é um dos vetores de ataque dominantes usados pelos cibercriminosos para realizar atividades maliciosas [1]. Todos os dias, o Instituto AV-teste registra mais de 450.000 novos programas maliciosos (malware) e aplicativos potencialmente indesejados (PUA) [2]. Os produtos antivírus implementam tecnologias de análise estática e heurística para detectar malware. Infelizmente, essas abordagens se tornaram menos eficazes para detectar malware sofisticado que explora técnicas de ofuscação e criptografia [3]. Em particular, ataques de malware sem arquivo são usados e causam perdas graves. Malware sem arquivo é um tipo de software malicioso que não depende de arquivos e não deixa a pegada no disco do computador. É difícil detectar programas maliciosos desconhecidos sem conhecer suas assinaturas.
Para combater essas ameaças, muitas pesquisas são realizadas em vários campos, incluindo aprendizado profundo, forense de memória, teoria dos números e assim por diante [4,5,6]. A Memory Forensics oferece informações exclusivas sobre o sistema interno do kernel e programas de corrida [7]. A memória tem um alto potencial para conter código malicioso de uma infecção, no todo ou em parte, mesmo que nunca seja escrito no disco, porque deve ser carregado na memória para executar [8]. O alvo de análise da memória forense é um despejo de memória de onde os traços de ataque podem ser extraídos. Por outro lado, esses traços não estão disponíveis pelo método de análise de disco tradicional. Durante a análise da memória, os malwares são executados em uma caixa de areia para impedir que os malwares causem danos a todo o sistema de computador, o que é realizado pelo estabelecimento de máquinas virtuais. Os dados de memória devem ser coletados em tempo hábil quando o malware está em execução na máquina virtual (VM). Neste artigo, os dados de memória são despejados no disco usando o algoritmo de despejo de memória para análise posterior. Além de despejar os dados da memória, os arquivos de executáveis portáteis maliciosos (PE) devem ser extraídos de milhares de dados de memória como dados de amostra. Bozkir et al. [9] apresentaram uma abordagem para reconhecer malware, capturando o despejo de memória de processos suspeitos, que podem ser representados como uma imagem RGB. No entanto, a coleta de dados de memória maliciosa dessa maneira é inadequada. O processo extraído potencialmente não carregou código malicioso na memória. Alguns processos maliciosos são injetados em novos processos para executar ações maliciosas. Nesse caso, extrair um único processo malicioso não pode refletir completamente o comportamento malicioso do processo. Somente a extração de um processo único malicioso não pode refletir completamente o valor da análise de memória. O conjunto de dados neste artigo leva vários despejos de imagens de memória e extrai todos os processos e dados de DLL. Por análise atenta dessas informações, dados benignos e maliciosos podem ser classificados por meio de uma plataforma de detecção.
Este artigo propõe um método de detecção de código malicioso. Um modelo de rede neural é construído para detectar fragmentos de amostra. O fragmento de amostra’S O custo do tempo é reduzido em comparação para detectar toda a amostra. Para reduzir o problema da perda crucial de dados causada pela detecção de fragmentos de amostra, selecionamos fragmentos detectando diferentes posições e comprimentos para determinar o local e o tamanho apropriados dos segmentos detectados.
As principais contribuições deste artigo estão resumidas da seguinte forma:
Este artigo cria um conjunto de dados de arquivo executável (PE) portátil na memória, que extrai mais amostras de memória maliciosa no processo. Este artigo primeiro coleta arquivos de PE estáticos da conhecida biblioteca maliciosa de bibliotecas e malshare, que são amplamente utilizadas pelos pesquisadores e têm alta persuasão. Em seguida, este artigo baixa o software comum da plataforma oficial da Microsoft. Por fim, ele executa as amostras estáticas na execução de máquinas virtuais e extrai as amostras dinâmicas para criar nosso conjunto de dados;
Construímos um modelo baseado na rede neural (CNN) e usamos o modelo para treinar segmentos de memória para obter uma detecção precisa de código malicioso;
Damos um exemplo de ataque de malware sem arquivo no artigo. Como o conjunto de dados de arquivos dinâmicos é construído, ele tem um bom desempenho de detecção para “nenhum arquivo” Ataques e amostras maliciosas que só podem ser detectadas em arquivos dinâmicos.
2. Trabalho relatado
2.1. Memória forense
As abordagens forenses de computador são divididas na análise dinâmica e estática. A análise estática é construída com base na premissa de não executar o programa. Inclui o processo de extração de componentes, instruções, fluxo de controle e chamadas de função dos recursos de código estático da sequência, como detecção de anomalia [10]. Jiang et al. [11] projetaram um conjunto de esquemas de verificação de integridade binária de grão fino para verificar a integridade de arquivos binários em máquinas virtuais. O método de análise estática tinha alta cobertura de amostra. Ainda assim, foi necessária uma análise de vários ângulos para detectar código malicioso usando tecnologias como deformação, polimorfismo, ofuscação de código e criptografia [12]. Em relação à análise dinâmica, a maioria das informações na memória estava incompleta devido ao mecanismo de paginação e substituição da memória. O programa não transferiu todas as informações para a memória durante a execução. Apenas parte da informação foi movida para a memória primeiro. Portanto, os dados executáveis completos não podem ser obtidos.
Além disso, uma vez que um programa malicioso detecta que a ferramenta de detecção de vírus/Trojan estava em execução ou usando software para obter a memória, ela interrompe imediatamente o comportamento do ataque, a autodestruição e apaga os traços de ataque. Esses comportamentos de autodestruição apresentam requisitos mais altos para amostragem e detecção de dados de memória. Otsuki et al. [13] propuseram um método de extrair traços de pilha das imagens de memória em um sistema Windows de 64 bits. Eles demonstraram a eficácia do carregador furtivo analisando um conjunto de executáveis e malware do Windows protegidos com o carregador furtivo usando as principais ferramentas de análise dinâmica e estática. Uroz et al. [14] investigaram as limitações que a memória forense impõe ao processo de verificação de assinatura digital de arquivos assinados pelo Windows PE obtidos de um despejo de memória. Essas limitações são dados incompletáveis, alterações de dados causadas por realocação, arquivos assinados por catálogo e inconsistências de arquivos e processos executáveis. Cheng et al. [15] propuseram um algoritmo de agrupamento que percebeu o método automático de análise de correlação de dados de memória através da análise da estrutura de dados críticos do sistema operacional. As principais idéias estão garantindo a precisão dos dados na extração de várias visões e analisando o comportamento da memória em um estilo para-síncrono. Palutke [16] explorou um mecanismo de compartilhamento de memória para detectar processos ocultos a partir de dados de memória. Eles apresentam três novos métodos que impedem a memória do espaço do usuário mal -intencionada em ferramentas de análise e, além disso, tornar a memória inacessível a partir de uma perspectiva de analistas de segurança. Wang et al. [17] adotaram o método de análise de memória física do Windows com base no KPCR (kernel’S Região de Controle do Processador) Estrutura, que resolveu os problemas do julgamento da versão e a tradução de endereços do sistema operacional. Tornou -se cada vez mais desafiador conduzir a memória forense usando os métodos acima para o aumento exponencial dos códigos maliciosos. É difícil detectar se existem comportamentos maliciosos em um grande número de arquivos de PE na memória por meio de análise manual profissional, o que o torna uma direção de pesquisa muito desafiadora.
2.2. Detecção de malware
As abordagens de detecção de código maliciosas são populares entre os pesquisadores de segurança de rede. Para julgar se o arquivo exe é software malicioso, todo o arquivo estático é tratado usando um algoritmo de aprendizado de máquina [18]. A desvantagem desse método é que, se a quantidade de dados no conjunto de dados era enorme, uma carga de grandes dimensões foi gerada durante o processo de treinamento de dados. Da maneira proposta por Bozkir et al. [9], os arquivos binários das amostras maliciosas são convertidas em imagens, e as imagens transformadas são classificadas pelos classificadores que suportam máquinas vetoriais (SVM), aumento de gradiente extremo (xgboost) e floresta aleatória. Marín et al. [19] extraídos caracteres imprimíveis dos arquivos PE para detecção através de aprendizado de máquina. Li et al. [20] propuseram uma abordagem de detecção de malware baseada na CNN. O modelo VGG-16 foi usado como modelo de trem no qual os filtros convolucionais eram do tamanho 3 × 3. Zhang et al. [21] propuseram um método de classificação para malware. O processo extraiu os recursos da estrutura semântica do código com base em uma análise de fluxo de dados e usou redes convolucionais de gráfico para detectar os recursos estruturais semânticos. A precisão da detecção deste método foi 95.8%. Wadkar et al. [22] propuseram um método de detecção evolutivo para malware com base no modelo SVM. O método proposto por Han et al. [23] analisa malware com base em sua estrutura e comportamento.
Posteriormente, vários classificadores, a saber, florestas aleatórias, árvore de decisão, CNN e XGBoost, foram usadas para classificar os dados de entrada. Huang et al. [24] desenvolveram um método de detecção de malware usando aprendizado e visualização profunda com base na API do Windows. Ele gera visualizações estáticas usando recursos estáticos recuperados dos arquivos de amostra. Lu XD et al. [25] propuseram uma abordagem de detecção de Floresta Deep (MCDF) de Code (MCDF). No processo, os arquivos binários foram convertidos em imagens em escala de cinza, que foram usadas para treinamento e teste do modelo MCDF.
Conforme discutido acima, a maioria dos métodos de pesquisa usou estruturas de dados de memória e conexões entre processos para a memória forense e detecção de código maliciosa. Muitas vezes é difícil encontrar malware específico usando esses métodos. Alguns métodos propostos anteriormente [5,12,26] analisaram arquivos de memória específicos; Outra maneira relatada anteriormente [14] examina o registro na memória. Um estudo anterior [9] propôs um método que converte arquivos de memória em imagens para análise por meio de aprendizado de máquina. Nos métodos de pesquisa existentes, o conjunto de dados é basicamente dados estáticos ou apenas um único arquivo de processo. O comportamento malicioso injetado em outros processos não pode ser detectado. Extraímos todos os processos e arquivos DLL da memória para detectar código malicioso, especialmente ataques sem arquivo. Além disso, maximizamos a criação de conjuntos de dados de memória PE, extraindo arquivos maliciosos da memória. Finalmente, construímos um modelo de aprendizado profundo que se encaixa em nossos dados. Técnicas típicas anti-malware são baseadas principalmente em assinaturas para determinar se o software contém código malicioso. Uroz et al. [14] desenvolveram o plug -in de volatilidade Sigcheck, que recupera arquivos executáveis de um despejo de memória e calcula sua assinatura digital (se viável). Eles testaram no Windows 7 x86 e x64 dumps de memória. Seu método requer captura o arquivo PE completo e sua taxa de detecção fica cada vez mais baixa à medida que o código é executado. No entanto, ao detectar fragmentos de arquivos, nosso método é mais eficiente. Ao realizar vários conjuntos de experimentos no conjunto de dados produzidos, concluímos que o fragmento de dados de 4096 bytes na cabeça do arquivo PE na memória é usado para detecção e a taxa de precisão é 97.48%.
3. Tecnologia de extração de arquivos PE de memória
3.1. Análise de memória
A memória forense depende da imagem da memória’S Arquivo binário. É um desafio localizar e analisar as informações valiosas da imagem de memória despejada. Embora um processo seja muito semelhante a um programa na superfície, o conceito de processo é essencialmente diferente. Um programa é uma sequência estática de instruções. O processo é uma operação dinâmica que contém a sequência de execução e vários recursos para executar o programa. No Windows Memory Forensics, as evidências obtidas e a ordem de obter as evidências de análise diferem de acordo com os diferentes requisitos forenses. No entanto, iniciar o estudo com os processos de execução é frequentemente preferido porque o pessoal forense pode entender quais aplicativos estão em execução e o que esses aplicativos estão fazendo através da análise do processo.
Através de uma estrutura de lista de lista ligada bidirecionalmente. A chave para processar a análise é obter o ponteiro para a lista de processos do sistema ligados a bidirecionais. Como mostrado na Figura 1.
O conteúdo CR3 e o modo de tradução de endereço são determinados de acordo com a estrutura do KPCR. O processo breve é o seguinte: estrutura de kPCR -> membro do KPCRB -> Membro do ProcessorState -> Membro do SpecialRegister -> CR3 Register;
O PSActiveProcessHead é determinado de acordo com a estrutura do KPCR, e o processo é o seguinte: estrutura de kpcr -> kdversionBlock -> psactiveProcessHead;
Para obter informações sobre os processos, “PsActiveProcessHead” e “ActiveProcessLinks” são usados para identificar os processos do sistema; Assim, uma lista vinculada de mão dupla pode ser percorrida e todas as atividades do processo podem ser enumeradas.
3.2. Memória forense
O algoritmo de despejo dos arquivos PE na memória é mostrado no algoritmo 1. Como o arquivo de imagem de memória a ser despejado é muito grande, precisamos obter o endereço físico exato para despejar o arquivo PE necessário. O endereço base do diretório da página do processo obtido na tecnologia de análise de memória é marcado como P. O nome do arquivo do arquivo PE alterado armazenado no arquivo especificado é inserido no algoritmo. O algoritmo 1 pode despejar os dados do espaço de PE especificados no arquivo especificado.
Em primeiro lugar, localize a tabela de diretório de página (linha1) pelo valor do endereço da base do diretório da página. Leia a entrada do diretório da página (PDE) na tabela de diretório de página e determine se a entrada do diretório está vazia. Se a entrada do diretório não estiver vazia, marque a entrada do diretório da página como D. Se d & 1 for igual a 1, marque o valor de d & 0xfffff000 como o endereço físico da tabela de páginas especificada pela entrada do diretório como t. Se d & 1 não for igual a 1, prossiga para a próxima entrada de diretório de página não vazia;
Em segundo lugar, leia a primeira entrada de página não vazia da tabela de páginas. As entradas da tabela de página estão marcadas com T e, se T & 1 for igual a 1, marque o valor de T & 0xfffff000 como T como o endereço físico da página física especificada pela entrada da página. Localize o endereço físico na imagem da memória, leia o conteúdo da página de memória física e despeje os dados de PE de uma única memória no arquivo especificado na imagem da memória através do endereço físico especificado. O algoritmo (das linhas 2 a 15) atravessa a página inteira da mesa.
Através da análise de memória e da tecnologia de despejo de memória, podemos extrair o arquivo PE de memória necessário do arquivo de imagem de memória despejado do sistema para criar nosso conjunto de dados.
Algoritmo 1 Algoritmo de despejo de espaço de processo. 
4. A abordagem
Nesta seção, explicamos o fluxo de trabalho de todo o processo em detalhes. A descrição do fluxo de trabalho é ilustrada na Figura 2.
4.1. Coletando dados de memória
Com relação à pesquisa de dados dinâmicos, Wei [27] usou o KDD99 para experimentos, vários estudos [28,29] usaram a estrutura do kernel como conjunto de dados para detecção dinâmica, e outro estudo [5] usou o arquivo binário extraído de um processo para convertê -lo em uma imagem para a análise para a análise. Os arquivos de DLL relacionados ao processo ainda não foram explorados. Para maximizar os arquivos maliciosos na memória, extraímos todos os arquivos de processo e DLL do despejo de memória e criamos um conjunto de dados.
Primeiro de tudo, os softwares comuns (escritório, vídeo, áudio e jogos et.) no sistema Windows são baixados. Em seguida, os softwares são executados e os arquivos de processo de memória são despejados. Principalmente, os arquivos de despejo de memória são despejados a cada 10 minutos e a operação é repetida dez vezes. Os arquivos PE são despejados várias vezes porque o software não carrega todos os arquivos na memória no tempo de execução. Para coletar amostras maliciosas, os arquivos de PE mal -intencionados estáticos são baixados do código malicioso VirusShare e Malshare, bibliotecas amplamente utilizadas por pesquisadores [30,31] e, em seguida, amostras maliciosas são executadas em máquinas virtuais. O método de extração de amostras maliciosas dinâmicas é o mesmo que as amostras benignas. Amostras maliciosas são despejadas em um determinado intervalo.
Finalmente, um total de 4896 amostras de dados são obtidas. Para identificar se as amostras extraídas são amostras benignas ou maliciosas, as amostras benignas e maliciosas são autenticadas através da interface da API do Virustottal.
4.2. Pré -processamento do conjunto de dados
4.2.1. Tipo de dados Conversão
O conjunto de dados do arquivo de memória é consideravelmente diferente do conjunto de dados de texto do processamento de linguagem natural. Primeiro, pré -processamos o conjunto de dados usando segmentação de palavras de linguagem natural; isto é, convertendo dados binários em palavras únicas e depois conduzindo a incorporação de palavras. No entanto, quando o modelo é usado para treinar as amostras processadas, o resultado do treinamento é inferior, com uma precisão de aproximadamente 0.5, que não tem valor para classificação de dicotomia. Após a realização de pesquisas, verifica -se que o arquivo binário de PE de memória tem muitos 0 s consecutivos aparecendo no arquivo, o que não pode ser efetivamente aprendido para os dados após a segmentação da palavra. Vários estudos [9,32] converteram os dados binários em imagens como conjuntos de dados. Um estudo anterior [14] aprendeu diretamente os arquivos binários durante o pré -processamento de dados. A Figura 3 mostra nossas operações na transformação do tipo de dados do conjunto de dados. O intervalo de valor do número binário de 8 bits é de 0 a 255, e o valor da imagem também é de 0 a 255. Como as redes neurais convolucionais têm um bom desempenho na classificação de imagens, convertemos a cada oito bits binários do código malicioso em um decimal, tornando -o uma forma semelhante aos valores numéricos de imagem. Os dados de treinamento devem ser reduzidos ao mesmo comprimento antes de serem adicionados ao modelo de treinamento. Primeiro, adicionamos 1 aos dados no conjunto de dados e, em seguida, para dados mais menores que o comprimento, 0 é usado para preencher os dados para evitar a mistura com os dados reais.
4.2.2. Seleção de segmento
A amostra do conjunto de dados leva um fragmento da amostra para treinamento. Três métodos são adotados para interceptar parte dos dados na amostra.
Como é mostrado na Figura 4, o cabeçalho da amostra é selecionado para fragmentação, e os comprimentos do cabeçalho para a fragmentação são 32, 64, 128, 256, 512, 1024, 2048, 4096, 10.000 e 30.000 bytes. O efeito de fazer comprimentos diferentes dos fragmentos de amostra no modelo’s precisão é observada através de experimentos. Além disso, o método de treinamento de fragmentos de amostra também pode melhorar a eficiência da detecção do modelo e reduzir significativamente o tempo necessário para a detecção de amostras;
Como é mostrado na Figura 5, a cauda da amostra é selecionada para a fragmentação, de modo que a influência das diferentes posições do fragmento na precisão do treinamento possa ser julgada. A cauda é escolhida para extrair o fragmento da amostra e o comprimento extraído é o mesmo que o comprimento extraído do cabeçalho, para que o efeito das diferentes posições possa ser melhor executado;
Como é mostrado na Figura 6, as amostras para a fragmentação são selecionadas aleatoriamente. Para refletir melhor a influência dos diferentes locais nos resultados experimentais, amostras com o mesmo comprimento de fragmento, mas outros locais são extraídos aleatoriamente para cada amostra.
4.3. Nosso modelo
Para abordar os problemas que os arquivos dinâmicos de PE são incompletos e é difícil a detecção profissional de malware, uma estrutura de modelo profunda é proposta para aprender as características dos arquivos dinâmicos de PE para alcançar o objetivo da classificação. O pequeno fragmento dos arquivos de memória PE (256 bytes) exibe bons resultados de detecção.
No processo de seleção do modelo de aprendizado profundo, a memória de curto prazo de longo prazo [33] (LSTM) é usada primeiro para as experiências. O LSTM é relativamente maduro no campo do processamento de linguagem natural [34,35,36]. No entanto, os resultados experimentais mostram que o custo de tempo do treinamento do modelo é maior que o da CNN. Devido às formas complexas e diversas de código malicioso, os recursos extraídos pela CNN têm características de invariância de tradução [37]. Como a localização do código malicioso não é corrigida, a CNN é mais adequada para a detecção de código maliciosa em arquivos PE binários. Além disso, com o crescente comprimento dos fragmentos de sequência, a quantidade de computação do modelo LSTM será muito grande e o procedimento é demorado. Embora a duração do treinamento do modelo CNN comum seja mais curta que a do LSTM, o efeito de treinamento da CNN é semelhante ao LSTM em termos de precisão. Nossa arquitetura de modelo foi projetada para maximizar o aprendizado com amostras pré -processadas, como mostrado na Figura 7. Adotamos um modelo de rede com uma estrutura de 12 camadas baseada na CNN, na qual usamos principalmente várias camadas convolucionais para o modelo’s arquitetura. Para evitar o excesso de ajuste do modelo durante o treinamento, adicionamos várias camadas de abandono. A camada geral de abandono esconde um quarto dos nós de neurônios. No estudo que propôs a famosa estrutura VGG, Simonyan e Zisserman [21] observaram que, para um determinado campo receptor, o desempenho do pequeno kernel convolucional empilhado é melhor que o do grande kernel convolucional, porque várias camadas não lineares podem aumentar a profundidade da rede. Portanto, os grãos de convolução usados neste estudo são pequenos. Para o otimizador em aprendizado profundo, a taxa de precisão de Adam foi considerada melhor que a do SGD. Portanto, Adam foi adotado e uma função de perda de entropia cruzada foi adotada para a função de perda da propagação de fundo profundo. O conjunto de dados pré-processado na Seção 4.2 são dados unidimensionais, então a rede neural convolucional unidimensional (CNN1D) é adotada em nosso modelo. A diferença entre CNN1D e CNN é que a CNN é usada principalmente para a detecção de imagens bidimensionais, enquanto o CNN1D é usado para a detecção de dados unidimensionais. Usamos o CNN1D para inserir dados unidimensionais no modelo com um modo multicanal e, em seguida, fazemos o cálculo contínuo de tradução pelo kernel da convolução. Os valores de tags são comparados usando a função Softmax. Finalmente, a função de perda de entropia cruzada é usada para propagação traseira para otimizar o modelo; Assim, alcançar a detecção precisa de detecção de código maliciosa pode ser alcançada com alta precisão. O procedimento de processamento do modelo LSTM é semelhante ao método acima. Os dados unidimensionais pré-processados também são inseridos para o modelo LSTM para treinamento e detecção de código maliciosa pode ser realizado.
4.4. Algoritmo de rede neural
Esta seção apresenta o algoritmo no modelo de rede neural projetado para este estudo.
As características de saída das camadas de primeira, segunda e terceira convolução no ambiente de Pytorch podem ser expressas como:
o u t (n i, c o u t j) = b i a s (c o u t j, k) + ∑ k = 0 c i n – 1 w e i g h t (c o u t j, k) × i n p u t (n i, k)
Onde n é o tamanho do lote, C é o tamanho do canal, L é o comprimento da sequência e o viés é o valor de deslocamento da rede neural. Lote refere -se ao número de amostras processadas em lotes, pois as amostras são divididas em vários grupos. O número de amostras em cada grupo é o tamanho do lote, i é o índice dos grupos de amostra, j é o índice do número de amostras e k é o índice do canal de entrada.
A duração da sequência de saída que compreende as camadas de primeira, segunda e terceira convolução é calculada usando a seguinte equação:
L o u t = ⌊ l i n + 2 × p a d d i n g – d i l a t i n (k e r n e l _ s i z e – 1) – 1 s t r i d e + 1 ⌋
onde lfora é o comprimento da sequência de saída, lem é o comprimento da sequência de entrada, o preenchimento é o comprimento do enchimento, a dilatação é o tamanho da convolução da cavidade, que é definida como 1, kernel_size é o tamanho do núcleo da convolução, e o passo é o tamanho do passo.
Os parâmetros de entrada da camada achatada são calculados usando os parâmetros de saída da camada de agrupamento. A sequência é achatada usando uma camada achatada e depois transformada em dois nós de neurônios por uma camada totalmente conectada e, finalmente, classificada por uma função softmax.
A camada Softmax, que é a última camada da camada oculta, a saber, o classificador, é expresso como:
y k = e x p (a k) ∑ i = 1 n e x p (a i)
O exp (x) denota a função exponencial de ex (e é o napier’s constante = 2.7182. ), n representa o número total de neurônios na camada de saída e yk representa a saída dos neurônios K na camada de saída, onde o numerador é a função exponencial do sinal de entrada ak do neurônio K, e o denominador é a soma das funções exponenciais de todos os sinais de entrada.
A função de perda do modelo de rede neural adota a função de perda de entropia cruzada min:
E = – 1 m ∑ m ∑ k t m k l o g y m k
onde m representa o número de amostras de conjunto de treinamento, tMk representa o valor do elemento k da amostra de previsão M, yMk é a rede neural’s Saída para a amostra de previsão M, e tMk são os dados supervisionados. Ao estender a função de perda de uma única peça de dados a M peças de dados e dividindo -se por M no final, a função de perda média de um único fragmento de previsão pode ser obtido. Um indicador unificado independente dos dados de treinamento pode ser obtido através de tal média.
Através das equações (1) e (2), podemos calcular cada camada convolucional’s tamanhos de entrada e saída. Em nosso modelo, os parâmetros de entrada da camada totalmente conectada precisam ser calculados manualmente ao treinar segmentos de amostras de diferentes tamanhos. Calculando cada camada’o comprimento s é complicado através da fórmula acima. Ao observar e calcular o modelo de rede neural que construímos, obtivemos a fórmula para calcular o comprimento da entrada da camada totalmente conectada em nosso modelo:
F l a t t e n i n = ((s a m p l e n e n – 1) m a x p o l s i z e) – 2 m a x p o l s i z e 2
Falttenem representa o comprimento de entrada da camada totalmente conectada, amostraLen representa o comprimento da amostra de entrada, Maxpooltamanho significa o tamanho da camada de pool e o Conv_Channel representa o tamanho do canal de saída da última camada convolucional. Tomando o comprimento do fragmento de 2048 como exemplo, apenas a camada de convolução e a camada de agrupamento afetam o tamanho dos dados e as outras camadas de rede neural antes que a camada totalmente conectada não afete o tamanho dos dados. Nosso modelo tem três camadas de convolução e três camadas de pool, e os tamanhos do kernel da convolução das três camadas de convolução são 3, 4 e 5, respectivamente. O pool máximo é usado para a camada de agrupamento, e as três camadas de pool estão todas definidas como 4. Em nosso modelo, o preenchimento da camada de convolução é definido como 0, para que o comprimento dos dados seja reduzido em 1 após cada convolução. Encolhe por um fator de quatro a cada pool. A ordem de convolução agrupada em nosso modelo é a convolução, o agrupamento, a convolução, a convolução, o agrupamento e o pool; Após o agrupamento de convolução do nosso modelo, o comprimento dos dados com um comprimento de fragmento de amostra de 2048 é primeiro reduzido em 1 e, em seguida, o comprimento é reduzido em quatro vezes. Ao subtrair a saída da camada anterior por 1 duas vezes e reduzindo duas vezes em quatro vezes, o comprimento da amostra se torna 31. Finalmente, multiplicar 31 pelo número de canais de saída da última camada convolucional é o parâmetro de entrada da camada totalmente conectada. A Figura 7 mostra o processo de cálculo detalhado do comprimento de entrada da camada de achatamento na seção de rede neural.
As configurações detalhadas de parâmetros do modelo de rede neural são introduzidas na seção 5.3.
5. Visão geral experimental
5.1. Ambiente operacional e conjuntos de dados
A CPU de hardware do nosso experimento é o processador Intel (R) Core (TM) i7-11800H, configurado com duas memória 8G; Nvidia GeForce RTX 3050 Cartão gráfico. O ambiente de software é um sistema operacional Windows10 de 64 bits e VMware, que instala máquinas virtuais do Windows 7 e Windows XP para executar amostras maliciosas. O ambiente para construir e executar a estrutura de aprendizado profundo é o Python 3.7, Anaconda conda 4.11.0, e pytorch Torch1.10.1. O conjunto de dados é gerado da seguinte forma: Coletando amostras estáticas de Virusshare e Malshare, executando as amostras na máquina virtual, despejando informações de memória e processos de extração e arquivos DLL dos dados de memória.
5.2. Métricas de avaliação
Para detectar código malicioso, usamos os quatro índices de avaliação da classificação binária: precisão, precisão, medida F e recall [38]. F-mesa implica que um índice pode refletir as taxas de precisão e recall.

